【论文笔记】Emotional Chatting Machine
Emotional Chatting Machine 论文笔记
背景
现在的研究(指这篇论文发表之前)大多受心理学的启发,要么基于规则,要么局限于小规模数据。在大规模数据上训练的模型都没有考虑到情感因素。
该研究有几个挑战:
- 缺少有情感标记数据的数据库
- 需要平衡语法和情感的表达
- 现有模型只是简单嵌入情感,通常生成的是没有感情的话语(比较含蓄,模棱两可)
本文做出了以下改善:
- 本文提出了在大规模会话生成中处理情感因素。据我们所知,这是关于该主题的第一项研究工作。
- 本文提出了一个端到端框架(称为 ECM ),将情感影响整合到了大规模对话生成中。它有三种新的机制:情感类别嵌入、内部情感记忆和外部记忆。
- 结果表明,与传统的 Seq2Seq 模型相比, ECM 可以产生更高的内容和情感分数的响应。我们相信,未来的研究工作,如移情计算机代理和情感交互模型可以基于 ECM 进行。
与现有研究相比,我们的工作在两个主要方面有所不同:
- 先前的研究在文本生成中严重依赖于语言工具或定制参数,而我们的模型完全是数据驱动的,没有任何手动调整;
- 先前的研究无法模拟输入和回应之间的多重情感互动,生成的文本只是延续了主要的上下文的情感。
模型
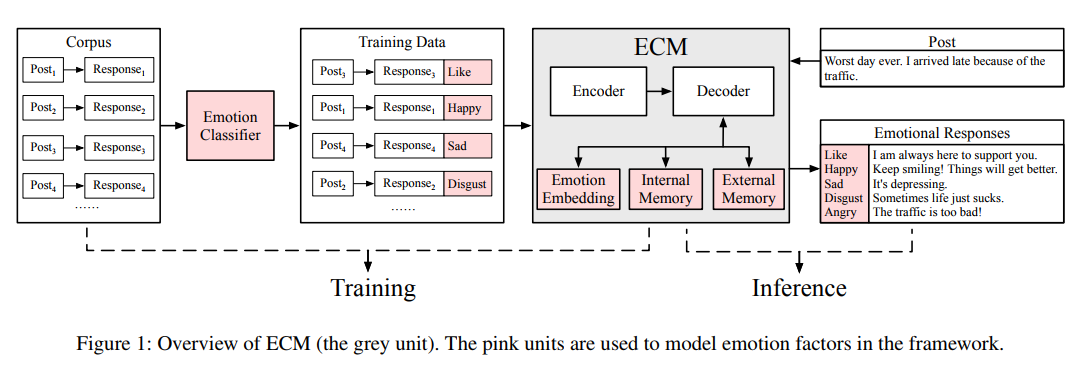
给一个输入 \(\boldsymbol{X}=\left(x_{1}, x_{2}, \cdots, x_{n}\right)\) 和将要生成的响应的情感分类 \(e\) (解释如下),目标是生成和情感分类 \(e\) 一致的响应 \(\boldsymbol{Y}=\left(y_{1}, y_{2}, \cdots, y_{m}\right)\) 。究其根本,该模型估计了以下概率:
情绪类别为{ Angry, Disgust, Happy, Like, Sad, Other },采用中文情绪分类挑战任务。
我们提出的情感聊天机( ECM )使用了三种机制生成情感表达:
- 由于情感类别是情感表达的高级抽象,ECM 嵌入情感类别,并将情感类别嵌入反馈给解码器。
- 我们假设在解码过程中,存在一个内部情绪状态,为了捕获该状态的隐含变化并动态平衡语法状态和情绪状态之间的权重,ECM 采用了一个内部存储模块。
- 通过外部记忆模块显式选择一般(非情绪)词或情绪词,对情绪的显式表达进行建模。
情感类别嵌入
对于每个情感类别 \(e\) ,我们随机初始化情感类别 \(\boldsymbol{v}_{e}\) 的向量,然后通过训练学习情绪类别的向量。情感类别嵌入 \(\boldsymbol{v}_{e}\) 、单词嵌入 \(\boldsymbol{e}(y_{t-1})\) 和上下文向量 \(\boldsymbol{c}_ {t}\) 被馈入解码器以更新解码器的状态 \(\boldsymbol{s}_{\boldsymbol{t}}\) :
基于 \(\boldsymbol{s}_{\boldsymbol{t}}\) ,可通过之前的式子相应地计算解码概率分布以生成下一令牌 \(y_{t}\) 。
内部记忆
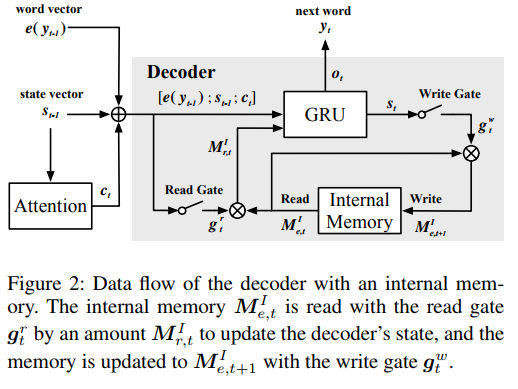
内部记忆的作用就是平衡语法性和情感性。本文中使用的方法是在每一步中,情绪状态都会有一定程度的衰退;一旦解码过程完成,情绪状态应衰减为零,表明情绪已完全表达。
(我的理解是,如果情感状态一直是保持不变,很可能会出现因为情感权重过高导致整个句子的语法出现问题,比如:I'm happy because of the weather. 在前半句情感状态权重会比较高,所以会选择 happy 表达情感,在情感权重逐步下降的过程中,后半句才会选择陈述形式的从句而不是比如:because of the happy )
内部记忆模块的详细过程如图2所示。在每个步骤 t ,ECM 使用先前解码的词的词嵌入 \(\boldsymbol{e}(y_{t}-1)\) ,解码器的先前状态 \(\boldsymbol{s}_{t-1}\) 和当前上下文向量 \(\boldsymbol{c}_{t}\) 的输入来计算读取门 $\boldsymbol{g}{t}^{r} $ 。在解码器的状态向量 \(s_{t}\) 上计算写入门 $\boldsymbol{g}^{w} $ 。读取门和写入门定义如下:(式6、7)
读取门和写入门分别用于从内部记忆模块中读取和写入。因此,情感状态在每一步都被一定量( $\boldsymbol{g}_{t}^{w} $ )擦除。在最后一步,内部情感状态将衰减为零。该过程正式描述如下:(式8、9)
其中, \(\otimes\) element-wise 乘法, \(r/w\) 分别表示读取/写入, \(I\) 意思是内部。GRU 根据前一个目标单词 \(\boldsymbol{e}(y_{t}-1)\) 、解码器的先前状态 \(\boldsymbol{s}_{t-1}\) 、上下文向量 \(\boldsymbol{c}_{t}\) 以及情绪状态更新 \(\boldsymbol{M}_{r, t}^{I}\) 更新其状态 \(\boldsymbol{s}_{t}\) ,具体如下:(式10)
基于该状态,可以获得词生成分布 \(\boldsymbol{o}_{t}\) ,并且可以对下一个词 \(y_{t}\) 进行采样。在生成下一个词后, \(\boldsymbol{M}_{r, t+1}^{I}\) 被回写到内部记忆中。注意,如果多次执行式9,则相当于将矩阵连续相乘,从而产生衰减效应因为 \(1≤ sigmoid(·) ≤ 1\) 。这类似于记忆网络中的删除操作。
(简而言之内部记忆参与的部分就是先算出读取门参数,和内部记忆一起元素相乘送入GRU 中,之后算出当前时间 t 的解码器状态,经过写入门写入内部记忆,此时会做一个衰减,因为写入门参数是0-1的数字)
外部记忆
就是决定选择通用词还是情感词,用一个类型选择器。
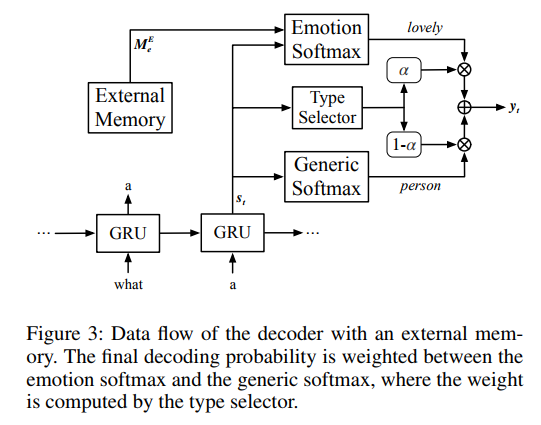
给定解码器的当前状态 \(s_{t}\) ,分别对从外部记忆模块和通用词汇读取的情感词汇表计算情感 softmax \(P_{e}(y_{t}=w_{e})\) 和通用 softmax \(P_{g}(y_{t}=w_{g})\) 。类型选择器 \(α_{t}\) 控制生成情感或一般词 \(y_{t}\) 的权重。最后,从下一个单词概率(两个加权概率的 concatenation )中对下一个单词进行采样。该过程可制定如下:(式11-14)
其中, \(\alpha_{t}\in[0,1]\) 是一个标量,用于平衡情感词 \(w_{e}\) 和一般词 \(w_{g}\) 之间的选择, \(P_{g}/P_{e}\) 分别是一般词/情感词的分布, \(P_{(y_{t})}\) 是最终的单词解码分布。请注意,这两个词汇表没有交集,最终分布 \(P_{(y_{t})}\) 是两个分布的 concatenation 。
实验
实施细节
我们使用 Tensorflow 来实现所提出的模型。
编码器和解码器两层 GRU 结构,每层有256个隐藏单元,并分别使用不同的参数集。词嵌入大小设置为100。
词汇量限制为40000。情感类别的嵌入大小设置为100。
内部记忆是一个大小为6×256的可训练矩阵,外部记忆是一个40000个单词的列表,其中包含一般单词和情感单词(但情感单词有不同的标记)。
为了产生不同的响应,我们在解码过程中采用了波束搜索,其中波束大小设置为20,然后在移除包含未知词的响应后,根据生成概率重新排列响应。
我们使用小批量随机梯度下降(SGD)算法。批量大小和学习率分别设置为128和0.5。
为了加快训练过程,我们在 STC 数据集上训练了一个带有预训练的词嵌入的 seq2seq 模型。然后我们在 ESTC 数据集上训练我们的模型,参数由预先训练的 seq2seq 模型的参数初始化。
我们运行了20个 epoches ,每个模型的训练阶段在 Titan X GPU 机器上大约需要一周的时间。
对比模型
一般的 seq2seq 模型和我们创建的情感类别嵌入模型(Emb),其中情感类别嵌入到向量中,向量作为每个解码位置的输入,类似于用户嵌入的想法。由于情感类别是情感表达的高级抽象,因此这是我们模型的适当基线。
结果
自动评估
我们采用了情感准确性来检测预期情感类别(作为模型的输入)和情感分类器生成的响应的预测情感类别之间的一致性。
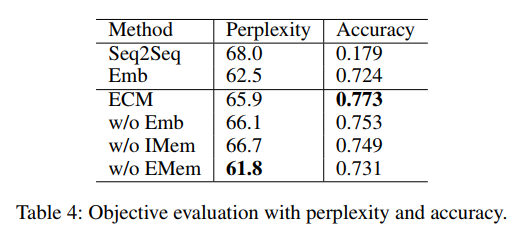
ECM 在情感准确性方面表现最好,而在困惑度方面表现比 Seq2Seq 好,但比 Emb 差。
人工评估
注释者被要求根据内容(评分范围为0、1、2)和情感(评分范围为0、1)对响应进行评分,并说明更倾向于两种系统中哪一个。
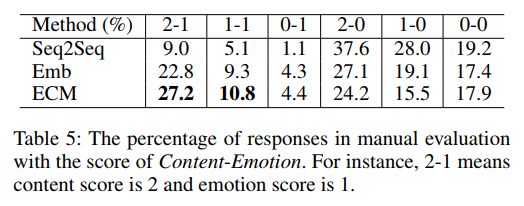
ECM 的所有响应分数在两个指标上都显著优于其他方法。如我们所见,ECM 生成的响应中有27.2%的内容分数为2,情感分数为1,而 Emb 和 Seq2Seq 分别只有22.8%和9.0%。这表明 ECM 在内容和情感方面都能更好地产生高质量的响应。

对于所有情感类别,ECM 在情感层面的表现均优于其他方法。然而,ECM 在 Disgust 和 Angry 类别中的内容层面的表现不如基线模型,因为这两个类别没有足够的训练数据。例如,在我们的 ESTC 数据集中,愤怒类别只有234635个响应,远远少于其他类别。
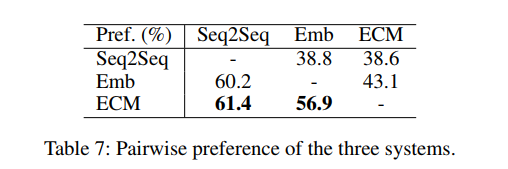
情感模型( Emb 和 ECM )比 Seq2Seq 更受欢迎,由于情感的明确表达以及内容的恰当性,ECM 更受青睐。
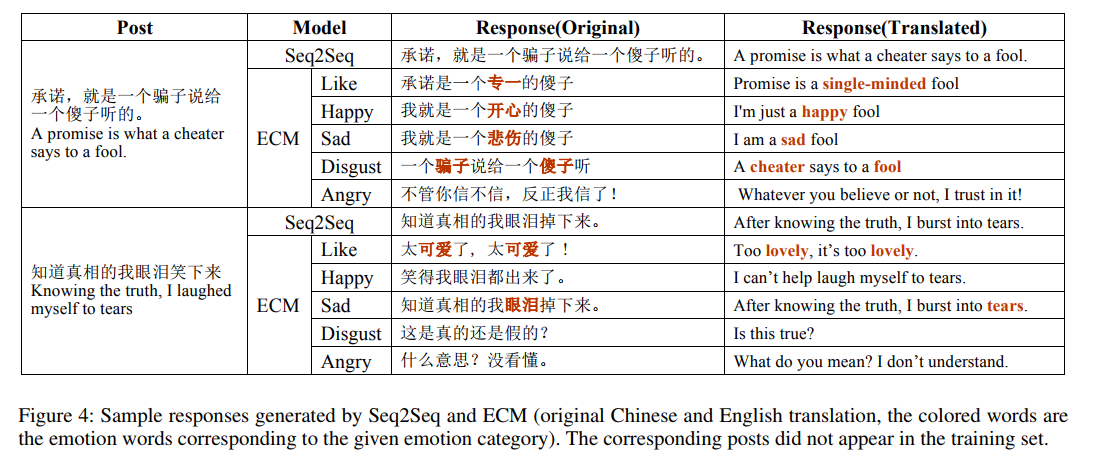
案例研究
结论和今后的工作
在本文中,我们提出了情感聊天机( ECM )来模拟大规模对话生成中的情感影响。提出了三种情感因素模型,包括情感类别嵌入、内部情绪记忆和外部记忆。客观和手动评估表明, ECM 不仅可以在内容层面上生成适当的响应,而且可以在情感层面上生成适当的响应。
在我们未来的工作中,我们将探索感与 ECM 的交互作用:模型应该为响应确定最合适的情感类别,而不是指定情感类别。然而,这可能具有挑战性,因为这样的任务取决于主题、上下文或用户的情感。
