【论文翻译】DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
原文:DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
代码地址:https://github.com/declare-lab/conv-emotion
注意:全文有部分机翻内容,没来得及校对和理解,很抱歉。
翻译帮助:百度翻译
摘要
对话中的情感检测对于许多应用程序来说都是重要的一步,包括对聊天历史的意见挖掘、社交媒体线程、辩论、论证挖掘、理解现场对话中的消费者反馈等。目前的系统并不是通过适应每一个话语的说话人来分别对待对话中的各方。在本文中,我们描述了一种基于递归神经网络(RNN)的新方法,该方法在整个对话过程中跟踪各个参与者的状态,并使用这些信息来进行情感分类。我们的模型在两个不同的数据集上和最先进的模型相比有显著的优势。
1 介绍
会话中的情感检测由于其在许多重要任务中的应用而越来越受到研究界的关注,如对聊天历史的意见挖掘以及 YouTube、Facebook、Twitter 等社交媒体中的线程(指对单个帖子的一系列回复。它们可以来自原帖作者或其他用户,但它们都是一条接一条的,可以在原帖中查看)。在本文中,我们提出了一种基于递归神经网络( RNN )的方法,通过处理大量可用的会话数据来满足这些需求。
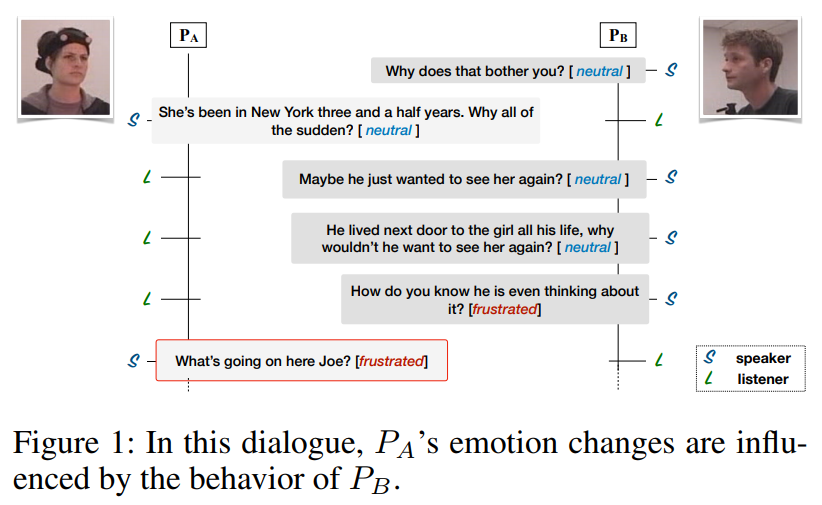
目前的系统,包括最新的技术,没有以一个有意义的方式区分对话中的不同参与者。它们不知道某一特定话语的说话人。相比之下,随着对话的进行,我们根据话语、上下文和当前的参与者状态对单个参与者用 party state 进行建模。我们的模型基于假设会话中有三个主要方面与情感有关:说话人、前面话语的上下文和前面话语的情感。这三个方面不一定是独立的,但它们各自的建模显著优于最新技术(表2)。在二元对话中,参与者有不同的角色。因此,要提取上下文,关键是要考虑说话者和聆听者在给定时刻的先前轮次(图1)。
我们提议的 DialogueRNN 系统采用三个门控循环单元( GRU )对这些方面进行建模。传入的话语被输入到两个 GRU 中,分别称为全局 GRU( global GRU )和参与者 GRU( party GRU ),以更新上下文和参与者状态。 global GRU 在对话语进行编码的同时对相应的参与者信息进行编码。
global GRU 提供了上下文表示,其中包含对话中不同参与者的所有先前话语的信息。 speaker state 依赖于上下文,通过注意力机制和说话者先前的状态。这确保了在时间 t ,说话者状态直接从说话者的先前状态和 global GRU 中获取信息, global GRU 中有先前各个参与者的信息。最后,更新后的 speaker state 被输入到 emotion GRU 中以解码给定话语的情感表示,用于情感分类。 在时间 t, emotion GRU 单元获得 t-1 的情感表示和 t 的说话者状态。
emotion GRU 和 global GRU 在参与者关系建模中起着关键作用。另一方面, party GRU 为同一参与者的两个连续状态之间的关系建模。在 DialogueRNN 中,所有这三种不同类型的 GRU 都以递归的方式连接。我们认为 DialogueRNN 优于最先进的情境情绪分类工具,因为它具有更好的上下文表现。
论文的其余部分组织如下:第2节讨论了相关工作;第3节详细描述了我们的模型;第4节和第5节介绍了实验结果;最后,第6节总结了本文。
2 相关工作
情绪识别在自然语言处理、心理学、认知科学等各个领域都引起了人们的关注(Picard 2010)。Ekman(1993)发现了情绪和面部线索之间的相关性。Datcu和Rothkrantz(2008)将声音信息与视觉线索相融合,用于情感识别。Alm、Roth和Sproat(2005)引入了基于文本的情感识别,这是Strapparava和Mihalcea(2010)在工作中开发的。Wollmer等人(2010)在多模态环境中使用上下文信息进行情感识别。最近,Poria等人(2017年)成功地将基于RNN的深度网络用于多模态情感识别,随后进行了其他工作(Chen等人2017年;Zadeh等人2018a;2018b)。
再现人际互动需要对对话有深刻的理解。Ruusuvuori(2013)指出,情感在对话中起着关键作用。有人认为,谈话中的情感动力是一种人际现象(Richards、Butler和Gross,2003)。因此,我们的模型有效地整合了人际互动。此外,由于会话具有自然的时间性,我们通过循环网络采用时间性(Poria et al.2017)。
记忆网络(Sukhbatar et al.2015)在几个NLP领域取得了成功,包括问答(Sukhbatar et al.2015;Kumar et al.2016)、机器翻译(Bahdanaau、Cho和Bengio 2014)、语音识别(Graves、Wayne和Danihelka 2014)等。因此,Hazarika等人(2018年)在二元对话中使用记忆网络进行情感识别,其中两个不同的记忆网络实现了说话人之间的互动,产生了最先进的性能。
3 方法论
3.1 启动问题
设对话中有 \(M\) 个参与者 \(p_{1},p_{2},...,p_{m}\) (在我们使用的数据集中 \(M=2\) )。 本研究的任务是预测话语 \(u_{1},u_{2},...,u_{N}\) 的情感标签(happy, sad, neutral, angry, excited, and frustrated),其中,话语 \(u_{t}\) 由参与方 \(p_{s(u_{t})}\) 发出,而 \(s\) 是话语与其对应方的索引之间的映射。同样的, \(u_{t} \in \mathbb{R}^{D_{m}}\) 是话语表达,使用下文描述的特征提取器获得。
3.2 单峰特征提取
为了与最先进的方法——会话记忆网络(CMN)(Hazarika等人,2018)进行公平比较,我们遵循相同的特征提取程序。
文本特征提取
我们采用卷积神经网络(CNN)进行文本特征提取。继Kim(2014)之后,我们使用大小分别为3、4和5的三个不同卷积滤波器从每个话语中获得 n-gram 特征,每个滤波器都有50个特征图。接着对输出进行最大池化,然后用校正线性单元(ReLU)作为激活函数进行激活。这些激活被连接并馈送到一个100维的密集层,该层被视为文本话语表示。该网络在话语层面上通过情感标签进行训练。
音视频特征提取
与Hazarika等人(2018年)相同,我们分别使用 3D-CNN 和 openSMILE (Eyben、Wollmer和Schuler 2010)进行视觉和声学特征提取。
3.3 我们的模型
我们假设对话中的话语情感取决于三个主要因素:
- 说话人。
- 由前面的话语给出的上下文。
- 前几句话隐含的情感。
我们的 DialogueRNN 模型(如图2a所示)对这三个因素进行了如下建模:
每一方都使用一个当该方发表言论时发生变化的 party state 进行建模。这使得该模型能够通过与话语背后的情感相关的对话来跟踪双方的情感动态。
此外,使用 global state (称为全局,是因为在各方之间共享)对话语的上下文进行建模,其中前面的话语和 party states 被联合编码用于上下文表示,这对于准确的 party states 表示是必要的。
最后,该模型从说话人的 party states 以及前面说话人的状态作为语境来推断情感表征。这种情绪表现用于最终情绪分类。
我们使用 GRU 单元(Chung等人,2014年)更新状态和表示。每个GRU单元用 \(h_{t} = GRU_{*}(h_{t-1},x_{t})\) 计算定义的隐藏状态,其中 \(x_{t}\) 是当前输入, \(h_{t-1}\) 是上一个 GRU 的状态。 \(h_{t}\) 也充当了当前 GRU 的输出。我们在补充文件中提供了 GRU 计算的详细信息。GRU是有效网络,其可训练参数为: \(W_{*,\{h, x\}}^{\{r, z, c\}} \text { , } b_{\star}^{\{r, z, c\}}\) 。
我们将当前话语的情感表述建模为先前话语的情感表述和当前说话人状态的函数。最后,该情绪表述被送到 softmax 层进行情绪分类。
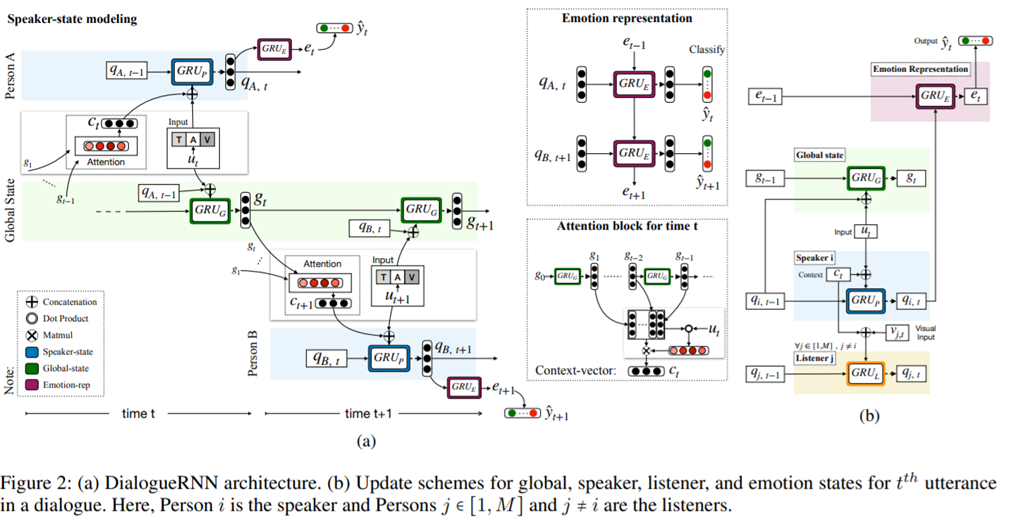
Global State (Global GRU)
global state的目标是通过对话语和说话人状态进行联合编码来捕获给定话语的上下文。每种状态也作为说话人特定的话语表达。关注这些状态有助于增加说话人之间和话语之间的依赖,从而产生更好的上下文表示。当前话语 \(u_{t}\) 将说话人状态从 \(q_{s(u_{t}),t-1}\) 变为 \(q_{s(u_{t}),t}\) 。我们用输出大小为 \(D_{\mathcal{G}}\) 的 GRU 单元 \(GRU_{\mathcal{G}}\) 来捕获这个变化,用 \(u_{t}\) 和 \(q_{s(u_{t}),t-1}\) :
其中 \(D_{\mathcal{G}}\) 是 global state 向量的大小, \(D_{\mathcal{P}}\) 是 party state 向量的大小, \(W_{\mathcal{G}, h}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{G}} \times D_{\mathcal{G}}}\) , \(W_{\mathcal{G}, x}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{G}} \times\left(D_{m}+D_{\mathcal{P}}\right)}\) , \(b_{\mathcal{G}}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{G}}}\) , \(q_{s\left(u_{t}\right), t-1} \in \mathbb{R}^{D_{\mathcal{P}}}\) , \(g_{t}, g_{t-1} \in \mathbb{R}^{D_{\mathcal{G}}}\) , \(D_{\mathcal{P}}\) 是 party state 的大小, \(\oplus\) 表示 concatenation 操作。
concatenation:将新向量拼接到原来的向量之后。
Party State (Party GRU)
DialogueRNN 在整个对话过程中使用固定大小向量 \(q_{1},q_{2},…,q_{M}\) 跟踪单个说话者的状态。这些状态代表了说话人在对话中的状态,与情绪分类相关。我们根据对话中参与者的当前(在时间 t )角色(说话者或听者)以及传入的话语 \(u_{t}\) 更新这些状态。对于所有参与者,这些状态向量用空向量初始化。本模块的主要目的是确保模型了解每个话语的说话人,并相应地进行处理。
说话者更新 (Speaker GRU)
说话人通常根据语境来安排回应,语境是谈话中的前置话语。因此,我们捕获与话语 \(u_{t}\) 相关的上下文 \(c_{t}\) ,如下所示:
其中 \(g_{1}, g_{2}, \ldots, g_{t-1}\) 是前 t-1 个 global states ( \(g_{i} \in \mathbb{R}^{D_{\mathcal{G}}}\) ) \(W_{\alpha} \in \mathbb{R}^{D_{m} \times D_{\mathcal{G}}}\) , \(\alpha^{T} \in \mathbb{R}^{(t-1)}\) , \(c_{t} \in \mathbb{R}^{D_{\mathcal{G}}}\) 。在上述第一个式子,我们计算代表先前话语的先前 global states 的注意分数 \(α\) 。这使得与 \(u_{t}\) 情绪相关的话语获得更高的注意力分数。最后,在上述第三个式子中,通过将先前的 global states 与 \(α\) 池化来计算上下文向量 \(c_{t}\) 。
我们用GRU 单元 \(GRU_{\mathcal{P}}\) 来将当前说话人状态从 \(q_{s(u_{t}),t-1}\) 更新为 \(q_{s(u_{t}),t}\) ,基于属于的话语 \(u_{t}\) 和上下文 \(c_{t}\) ,使用输出大小为 \(D_{\mathcal{P}}\) 的 GRU 单元 \(GRU_{\mathcal{P}}\)
其中 \(W_{\mathcal{P}, h}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{P}} \times D_{\mathcal{P}}}\) , \(W_{\mathcal{P}, x}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{P}} \times\left(D_{m}+D_{\mathcal{G}}\right)}\) , \(b_{\mathcal{P}}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{P}}}\) , \(q_{s\left(u_{t}\right), t}, q_{s\left(u_{t}\right), t-1} \in \mathbb{R}^{D_{\mathcal{P}}}\) 。这将当前话语的信息及其上下文从 global GRU 编码到说话人的状态 \(q_{s\left(u_{t}\right), t}\) ,这有助于情感分类。
聆听者更新
聆听者状态对聆听者由于说话者的话语而发生的状态变化进行建模。我们尝试了两种聆听者状态更新机制:
-
保持聆听者的状态不变,即
\[\forall i \neq s\left(u_{t}\right), q_{i, t}=q_{i, t-1},\tag{6} \] -
使用另一个 GRU 单元 \(GRU_{\mathcal{L}}\) 根据聆听者视觉线索(面部表情) \(v_{i,t}\) 及其上下文 \(c_{t}\) 更新聆听者状态,如下所示:
\[\forall i \neq s\left(u_{t}\right), q_{i, t}=G R U_{\mathcal{L}}\left(q_{i, t-1},\left(v_{i, t} \oplus c_{t}\right)\right),\tag{7} \]其中, \(v_{i, t} \in \mathbb{R}^{D_{\mathcal{V}}}\) , \(W_{\mathcal{L}, h}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{P}} \times D_{\mathcal{P}}}\) , \(W_{\mathcal{L}, x}^{\{r, z, c\}} \mathbb{R}^{D_{\mathcal{P}} \times\left(D_{\mathcal{V}}+D_{\mathcal{G}}\right)}\) , \(b_{\mathcal{L}}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{P}}}\) 。使用 Arriaga、Valdenegro Toro 和 Ploger(2017)引入的模型提取参与者 i ,时间 t 的聆听者视觉特征 \(v_{i,t}\) ,该模型在 FER2013 数据集上预训练,其中特征尺寸 \(D_{V}=7\) 。
更为简单的第一种方法被证明是已经够用的,因为第二种方法在增加参数数量的同时也产生了非常相似的结果。这是因为聆听者只有在他/她说话时才与对话相关。换句话说,也就是沉默的参与者对对话没有影响。现在,当一方说话时,我们用上下文 \(c_{t}\) 更新他/她的状态 \(q_{i}\) ,上下文 \(c_{t}\) 包含前面所有话语的相关信息,使得不需要显式的听者状态更新。如表2所示。
情感表述 (Emotion GRU)
我们从说话人状态 \(q_{s(u_{t}),t}\) 和先前话语的情感表述 \(e_{t}\) 推断出话语 \(u_{t}\) 的情感相关表述 \(e_{t−1}\) 。因为上下文对输入话语 \(u_{t}\) 的情感很重要, \(e_{t-1}\) 将来自其他 party states \(q_{s(u_{<t}),<t}\) 的经过微调的情感相关的上下文信息输入情感表述 \(e_{t}\) 。这就在说话者和其他参与者之间建立了联系。因此,我们使用大小为 \(D_{\mathcal{E}}\) 的 GRU 单元( \(GRU_{\mathcal{E}}\) )来对 \(e_{t}\) 建模:
其中 \(D_{\mathcal{E}}\) 是情感表述向量的大小, \(e_{\{t, t-1\}} \in \mathbb{R}^{D_{\mathcal{E}}}\) , \(W_{\mathcal{E}, h}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{E}} \times D_{\mathcal{E}}}\) , \(W_{\mathcal{E}, x}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{E}} \times D_{\mathcal{P}}}\) , \(b_{\mathcal{E}}^{\{r, z, c\}} \in \mathbb{R}^{D_{\mathcal{E}}}\) 。
由于说话者状态从 global states 获取信息,作为说话人特定的话语表述,有人可能会声称,通过这种方式,模型已经可以访问其他各方的信息。然而,如消融研究(第5.6节)所示, emotion GRU 通过直接连接先前参与者的状态,有助于提高性能。此外,我们认为说话者和 global GRUs( \(GRU_{\mathcal{P}}\) , \(GRU_{\mathcal{G}}\) )共同起着类似于编码器的作用,而 emotion GRU 起着解码器的作用。
情感分类
我们使用一个两层感知器和一个最终的 softmax 层,从话语 \(u_{t}\) 的情绪表述 \(e_{t}\) 计算 c=6 情绪类别概率,然后我们选择最可能的情绪类别:
其中 \(W_{l} \in \mathbb{R}^{D_{l} \times D_{\mathcal{E}}}\) , \(b_{l} \in \mathbb{R}^{D_{l}}\) , \(W_{\text {smax }} \in \mathbb{R}^{c \times D_{l}}\) , \(b_{\text {smax }} \in \mathbb{R}^{c}\) , \(\mathcal{P}_{t} \in \mathbb{R}^{c}\) , \(\hat{y}_{t}\) 是话语 \(u_{t}\) 的预测标签。
训练
我们使用分类交叉熵和 L2-正规化作为训练期间损失函数:
其中, N 是样本/对话的数量, \(c(i)\) 是样本 \(i\) 中话语的数量, \(\mathcal{P}_{i, j}\) 是对话 i 中话语 j 的情感标签的概率分布, \(y_{i,j}\) 是对话 i 中话语 j 的预期分类标签, \(\lambda\) 是 L2-正规化的权重, \(\theta\) 是可训练参数的集合:
我们使用基于随机梯度下降的 Adam( Kingma 和 Ba 2014)优化器来训练我们的网络。使用网格搜索优化超参数(数值加在了补充资料中)。
3.4 对话框RNN变体
我们使用 DialogueRNN (第3.3节)作为以下模型的基础:
DialogueRNN + Listener State Update (DialogueRNN)
该变体根据得到的说话人状态 \(q_{s(u_{t}),t}\) 更新侦听器状态,如式 (7) 所述。
Bidirectional DialogueRNN (BiDialogueRNN)
双向 DialogueRNN 类似于双向 RNN ,其中两个不同的 RNN 用于输入序列的向前和向后传递。 RNN 的输出在序列级串联。类似地,在 BiDialogueRNN 中,最终的情感表述包含了通过前向和后向对话分别来自对话中过去和未来话语的信息,这为情感分类提供了更好的上下文信息。
DialogueRNN + attention ( DialogueRNN + Att)
对于每个情绪表述 \(e_{t}\) ,在对话中,注意力通过与 \(e_{t}\) 的匹配应用于所有周围的情感表述(式 (13) (14) )。这提供了与未来和之前话语相关的上下文(基于注意分数)。
Bidirectional DialogueRNN + Emotional attention (BiDialogueRNN+Att)
对于 BiDialogueRNN 的每个情绪表征 \(e_{t}\) ,注意力被应用于对话中的所有情绪表述,从而可以从对话中的其他话语中捕捉上下文:
其中, \(e_{t} \in \mathbb{R}^{2 D_{\mathcal{E}}}\) , \(W_{\beta} \in \mathbb{R}^{2 D_{\mathcal{E}} \times 2 D_{\mathcal{E}}}\) , \(\tilde{e}_{t} \in \mathbb{R}^{2 D_{\mathcal{E}}}\) , \(\beta_{t}^{T} \in \mathbb{R}^{N}\) 。另外,如式 (9) 到式 (11) 所示, \(\tilde{e}_{t}\) 被馈送到两层感知机进行情感分类。
4 实验设置
4.1 数据集使用
我们使用两个情绪检测数据集 IEMOCAP(Busso 等人,2008年)和 AVEC(Schuller 等人,2012年)来评估 DialogueRNN 。我们以大约 80/20 的比率将两个数据集划分为训练集和测试集,这样分区就不会共享任何说话人。表1显示了两个数据集的序列和测试样本的分布。
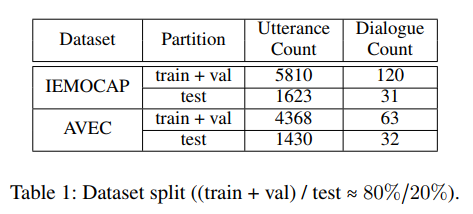
IEMOCAP
IEMOCAP(Busso 等人,2008年)数据集包含十位独特演讲者的双向对话视频,其中只有第1至第4节的前八位演讲者属于培训组。每段视频都包含一段单音二元对话,分为若干段。这些话语由六个情感标签中的一个加以注释,分别是 happy, sad, neutral, angry, excited, 和 frustrated。
AVEC
AVEC(Schuler 等人,2012年)数据集是对 SEMAINE 数据库(McKeown 等人,2012年)的修改,该数据库包含人类和艺术智能主体之间的互动。对话的每一个话语都有四个真正有价值的情感属性:valence ( [−1, 1] ),arousal ( [−1, 1] ) , expectancy ( [−1, 1] ) 和 power ( [0, ∞) ) 。注释在原始数据库中每0.2秒可用一次。但是,为了使注释适应我们对话语级别注释的需要,我们在话语的持续时间内平均属性。
4.2 基线和最新技术
为了全面评估 DialogueRNN ,我们将我们的模型与以下基线方法进行比较:
c-LSTM ( Poria 等人,2017年 )
双向 LSTM ( Hochreiter 和 Schmidhuber 1997 )用于从周围的话语中捕获上下文,以生成上下文感知的话语表示。但是,这种模式在说话人之间没有区别。
c-LSTM + Att ( Poria 等人,2017年 )
在该变体中,注意力通过等式 (13) (14) 应用于每个时间戳的c-LSTM输出。这为最终的话语表述提供了更好的上下文信息。
TFN ( Zadeh 等人,2017年 )
这是多模态场景的特殊情况。张量外积用于捕捉模态间和模态内的交互作用。该模型不从周围的话语中捕捉上下文信息。
MFN ( Zadeh 等人,2018a )
特定于多模态场景,该模型通过对特定视图和交叉视图交互进行建模,利用多视图学习。与 TFN 类似,此模型不使用上下文信息。
CNN ( Kim 2014 年)
这与我们的文本特征提取器网络(第3.2节)相同,它不使用来自周围话语的上下文信息。
Memnet ( Sukhbaatar 等人,2015年 )
如 Hazarika 等人(2018)所述,当前话语被馈送至记忆网络,其中记忆对应于先前的话语。记忆网络的输出被用作情感分类的最终话语表示。
CMN ( Hazarika 等人,2018年 )
这种最先进的方法利用两个不同的GRU为两个说话人模拟对话历史中的话语上下文。最后,通过将当前话语作为查询提供给两个不同的说话人记忆网络,获得话语表述。
4.3 模态
我们主要根据文本情态来评估我们的模型。然而,为了证实我们的模型在多模态场景中的有效性,我们还试验了多模态特征。
5 结果和讨论
我们将 DialogueRNN 及其变体与表2中文本数据的基线进行比较。正如预期的那样, DialogueRNN 在这两个数据集上的平均性能都优于所有基线方法,包括最先进的 CMN 。
5.1 与最新技术的比较
我们将 DialogueRNN 的性能与最先进的 CMN 的性能在 IEMOCAP 和 AVEC 数据集上进行了文本情景的比较。
IEMOCAP
如表2所示,对于 IEMOCAP 数据集,我们的模型超过了最先进的CMN方法,平均下来,准确率为2.77%,f1-score 为3.76%。我们认为,这种增强是由 CMN 和 DialogueRNN 之间的基本差异造成的,主要有:
- 式 (5) 中对 party state 用 \(GRU_{\mathcal{P}}\) 进行建模
- 式 (1) 和式 (5) 中对特定说话人进行话语处理
- 式 (1) 中用 \(GRU_{\mathcal{G}}\) 捕捉 global state
我们处理了六个不平衡的情绪标签,还探讨了单个标签的模型性能。 DialogueRNN 在六个情绪类别中的五个类别中都优于最先进的 CMN 方法,并且差距很大。对于 frustrated 类,DialogueRNN 的 f1-score 落后于 CMN 1.23%。我们认为如果 DialogueRNN 为 frustrated 类使用独立的分类器, DialogueRNN 可能会超越 CMN 。然而,从表2中可以看出, DialogueRNN 的一些其他变体,如 BiDialogueRNN ,在 frustrated 类的性能中已经超过了 CMN 。
AVEC
DialogueRNN 在 valence , arousal , expectancy ,和 power 属性方面优于 CMN(见表2)。这使得所有四个属性的平均绝对误差(MAE)和皮尔逊相关系数(r)显著降低。我们认为,这是由于纳入了 CMN 中缺失的 party state 和 emotion GRU 。
5.2 DialogueRNN 和 DialogueRNN 变体比较
我们讨论了 IEMOCAP 和 AVEC 数据集上不同 DialogueRNN 变体对于文本模态的性能。
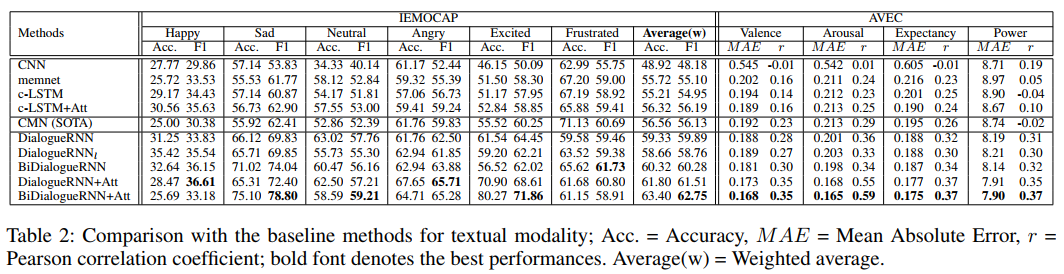
\(DialogueRNN_{l}\)
根据表2,使用显式聆听者状态更新产生的性能提升比常规 DialogueRNN 稍差。对于 IEMOCAP 和 AVEC 数据集都是如此。然而,这一趋势的唯一例外是 IEMOCAP 的 happy 情感标签,其中 \(DialogueRNN_{l}\) 的 f1-score 比 DialogueRNN 高1.71%。我们推测,这是因为聆听者只有在他/她说话时才与对话相关。现在,在 DialogueRNN 中,当一方讲话时,我们用上下文 \(c_{t}\) 更新他/她的状态 \(q_{i}\) ,上下文 \(c_{t}\) 包含前面所有话语的相关信息,不必使用 \(DialogueRNN_{l}\) 进行显式聆听者状态更新。
BiDialogueRNN
由于 BiDialogueRNN 从未来的话语中捕获上下文信息,我们期望它比 DialogueRNN 的性能更好。表2证实了这一点,其中 BiDialogueRNN 在两个数据集上的平均表现都优于 DialogueRNN 。
DialogueRNN + Attn
DialogueRNN + Attn 也使用来自未来话语的信息。然而,这个模型中我们通过将过去和未来的话语与当前的话语进行匹配,并计算它们的注意分数来获取信息。这为情感上重要的语境话语提供了更高的相关性,从而产生了比 BiDialogueRNN 更好的表现。与 BiDialogueRNN 相比, IEMOCAP 的f1-score提高了1.23%,并且在 AVEC 中持续降低了 MAE 和更高的 r 。
BiDialogueRNN + Attn
由于这个模型设置使用参与 BiDialogueRNN 的情感表述生成最终情感表述,因此我们期望该模型比 BiDialogueRNN 和 DialogueRNN+Attn 有更好的性能。表2证实了这一点,在这两个数据集上,该模型一般情况下比讨论中的任何其他方法表现都好。对于 IEMOCAP 数据集,该模型的f1-score平均数比最先进的 CMN 高6.62%,比普通 DialogueRNN 高2.86%。对于 AVEC 数据集,该模型在所有四个属性中都表现出了最佳性能。
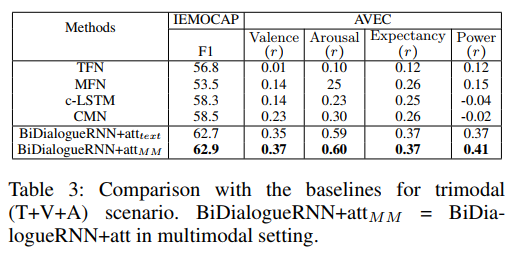
5.3 多模态设置
由于 IEMOCAP 和 AVEC 数据集均包含多模态信息,我们已评估了 Hazarika 等人(2018)使用和提供的 DialogueRNN 多模态特征。我们遵循 Hazarika 等人(2018年)的做法,将单峰特征串联作为融合方法,但是融合机制不是本文的重点。现在,如表3所示, DialogueRNN 显著优于强基线和最先进的 CMN 方法。
5.4 案例研究
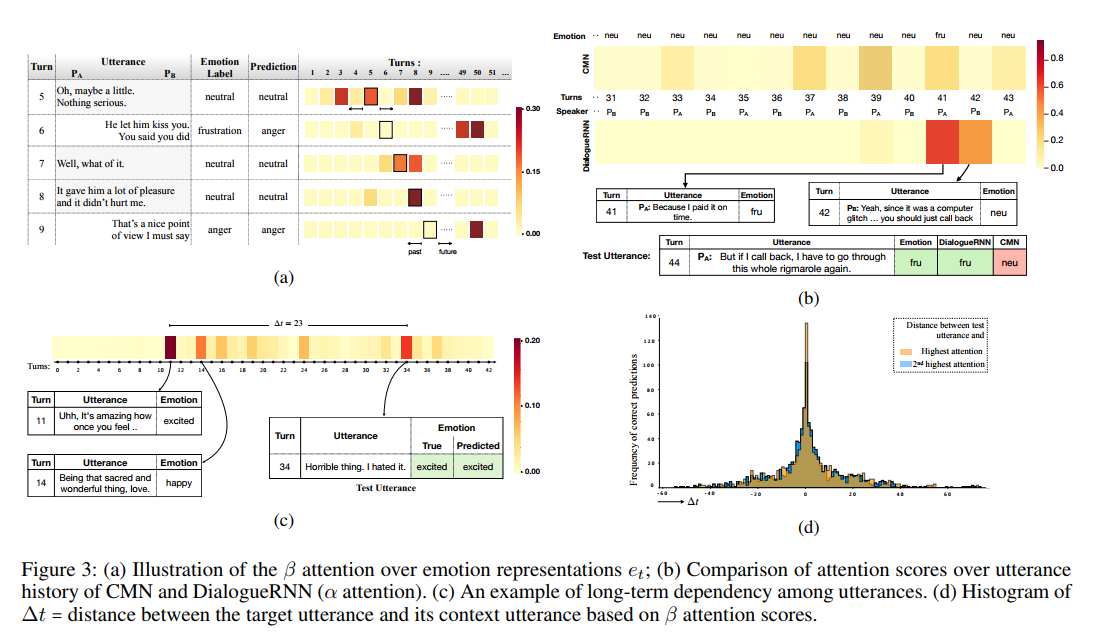
对先前话语的依赖(DialogueRNN)
DialogueRNN 的关键组件之一是其对 global GRU( \(GRU_{\mathcal{G}}\) )输出的注意模块。图 3b 显示了与来自 CMN 模型的 attention 向量和之前给定测试话语上的 \(α\) attention 向量(式 (2) )的比较。与 CMN 相比,我们模型的注意力更为集中:后者稀释了注意力分数,导致分类错误。我们观察到这种集中注意力的趋势,并假设它可以被解释为一个信心指标。在本例中,\(P_{A}\) 的测试话语(第44轮次)中所隐含的情绪从 neutral 变成了 frustrated 。 DialogueRNN 通过分别参加 \(P_{A}\) 和 \(P_{B}\) 所说的第41和42轮次来正确预测这一点。这两种话语提供了触发情绪转变的自身和参与者间的影响。然而, CMN 未能捕捉到这种依赖性,错误地预测了 neutral 情绪。
对未来话语的依赖 ( BiDialogueRNN+Att )
图 3a 可视化了一对夫妇之间对话的一段中,对情绪表述 \(e_{t}\) 的 \(β\) (等式 (13) )注意力。在讨论中,女性( \(P_{A}\) )最初处于中立状态,而男性( \(P_{B}\) )始终处于愤怒状态。该图显示,女性的情感注意力集中在其中性状态的持续时间上(大约1-16轮次)。例如,在对话中,第5、7和8轮次强烈关注轮次8。有趣的是,第五轮次关注过去(第三轮次)和未来(第八轮次)的话语。其他话语中的类似趋势建立了未来话语和过去话语的情感状态之间的相互依赖关系。通过 \(GRU_{\mathcal{E}}\) 对未来话语的有益考虑在第6轮次、第9轮次中也很明显。这些话语聚焦于遥远的未来(第49、50轮次),此时男人处于愤怒的状态,从而捕捉跨时间的情感关联。尽管我们的模型错误地将第六轮次分类,但它仍然能够根据正确的状态( frustrated )推断出相关的情绪状态( anger )。我们在第5.5节中对这一趋势进行了更多分析。
对远程上下文的依赖
对于图 3d 中 IEMOCAP 测试集的所有正确预测,我们总结了测试话语和(第二)最高参与话语之间的相对距离分布,无论是在过去还是在未来。这显示出一种下降趋势,在局部上下文中依赖性最高。然而,测试话语中有很大一部分(∼ 18%),注意到20到40轮次与自己不同的话语,这突出了长期情感依赖的重要作用。这种情况主要发生在保持特定情感基调并且不会引起频繁的情绪变化的对话中。图 3c 展示了长期上下文依赖的情况。所呈现的对话在整个对话过程中保持着 happy 的情绪。虽然第34轮次说了一句"Horrible thing. I hated it."。这似乎是一种消极的表达,从全局上下文来看,它表达了说话者目前的 excitement 情绪。为了消除这种情况的歧义,我们的模型关注过去(第11、14轮次)的远程话语,将这些话语作为整体对话情感调性的原型。
5.5 误差分析
预测中一个值得注意的趋势是相关情绪之间的交叉预测水平较高。这个模型中 happy 情绪的大部分错误分类都是对应了 excited 类的。此外, anger 和 frustrated 也会进行相互错误分类。我们怀疑这是由于这些情感对之间的细微差异,使得消除歧义更加困难。另一类错误率较高的是 neutral 类。其主要原因可能是其在分类分布中占多数,超过了其他情绪。
在对话层面,我们观察到,同一方的情绪发生变化的轮次是否是当前轮次的预测出现了大量错误。在测试集中发生的所有这些情绪变化中,我们的模型正确预测了47.5%的情况。与它在没有情绪变化的时候取得的69.2%的成功相比,它的成功率更低。对话中情绪的变化是一种复杂的现象,受潜在作用的支配。这些案例的进一步改进仍然是一个开放的研究领域。
5.6 消融实验
我们的方法的主要创新之处在于引入了 party state 和 emotion GRU ( \(GRU_{\mathcal{E}}\) )。为了全面研究这两个组成部分的影响,我们一次删除一个,并评估它们对 IEMOCAP 的影响。
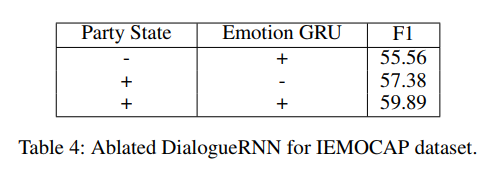
正如预期的那样,如表4所示, party state 非常重要,如果没有它,性能会下降4.33%。我们怀疑 party state 有助于提取与参与者情绪相关的有用上下文信息。
emotion GRU 也有影响,但不如 party state ,它的缺失只会导致性能下降2.51%。我们认为,原因在于缺乏来自其他参与者的上下文流中的先前话语的情感表述。
6 总结
我们提出了一种基于 RNN 的神经网络结构,用于会话中的情感检测。与最先进的方法 CMN 相比,我们的方法将每个传入的话语都考虑到说话人的特征,从而为话语提供了更清晰的上下文。我们的模型在两个不同的数据集上的文本和多模态上都优于当前的最新技术。我们的方法被设计成可扩展到具有两个以上说话者的多方交流情景,我们计划在未来的工作中对此进行探索。
