吃瓜教程|Datawhale-10月(4)
吃瓜教程|Datawhale-10月(4)
神经网络
神经元模型
M-P 神经元模型(一个用来模拟生物行为的数学模型)
在此模型中,神经元接收到来自 n 个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过激活函数(模拟“抑制”或“激活”)处理以产生神经元的输入。
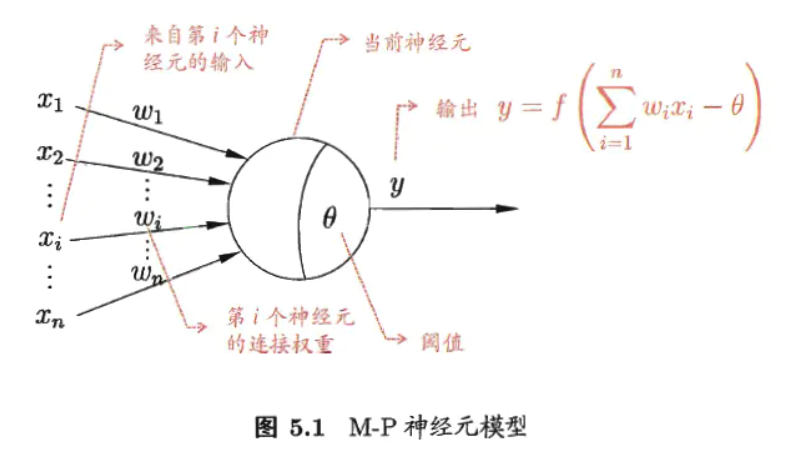
理想的激活函数是阶跃函数,它将输入值映射为0或1。然而阶跃函数不连续,不光滑,所以实际上用 Sigmoid 函数作为激活函数。
把许多个这样的神经元按一定的层次结构连接起来,就得到了神经网络。
我们将神经网络视为是由下式相互嵌套而得的模型:
单个 M-P 神经元:感知机( sgn (阶跃函数)作激活函数)、对数几率回归( sigmoid 作激活函数)
多个 M-P 神经元:神经网络
感知机和多层网络
感知机由两层神经元组成,输入层接受外界输入信号后传递给输出层,输出层是M-P神经元,也称为“阈值逻辑单元”。
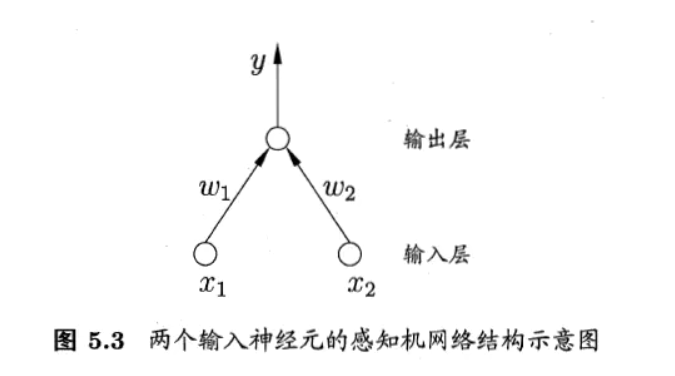
对于 \(y_{j}=f(\sum_{i}w_{i}x_{i}-\theta_{j})=f(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}-\theta)\) ,假如 f 是阶跃函数,则有
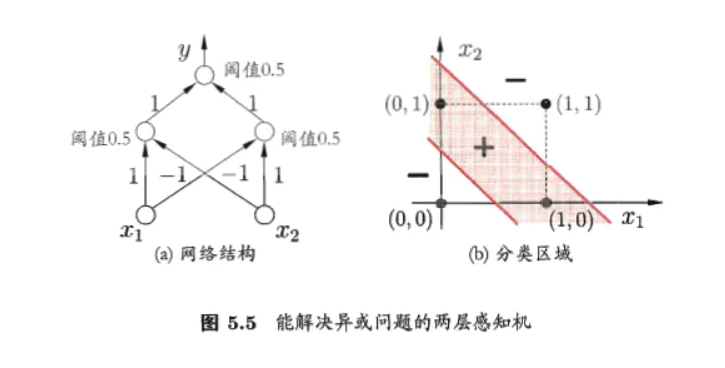
- 与( \(x_{1}\and x_{2}\) ):令 \(w_{1}=w_{2}=1,\theta =2\) ,则 \(y=f(1\cdot x_{1}+1\cdot x_{2}-2)\) ,仅在 \(x_{1}=x_{2}=1\) 时,y = 1。
- 或( \(x_{1}\or x_{2}\) ):令 \(w_{1}=w_{2}=1,\theta =0.5\) ,则 \(y=f(1\cdot x_{1}+1\cdot x_{2}-0.5)\) ,当 \(x_{1}=1或x_{2}=1\) 时,y = 1。
- 非( \(\neg x_{1}\) ):令 \(w_{1}=-0.6,w_{2}=0,\theta =-0.5\) ,则 \(y=f(-0.6\cdot x_{1}+0\cdot x_{2}+0.5)\) ,当 \(x_{1}=1时,y=0;x_{1}=0\) 时,y = 1。
更一般地,给定训练数据集,权重 \(w_{i}(i=1,2,...,n)\) 以及阈值 \(\theta\) 可通过学习得到。阈值 \(\theta\) 可视为一个固定输入为-1.0的“哑结点”所对应的连接权重 \(w_{n+1}\) ,这样,权重和阈值的学习就可以统一为权重的学习。
对于训练样本 \((x,y)\) ,若当前感知机的输出为 \(\hat{y}\) ,则感知机这样调整权重:
其中 \(\eta \in (0,1)\) 称为学习率。
以上内容的详细版本在下边会有介绍。
从几何角度来说,给定一个线性可分的数据集 \(T\) ,感知机的学习目标是求得能对数据集 \(T\) 中的正负样本完全正确划分的超平面,其中 \(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}-\theta\) 即为超平面方程。
\(n\) 维空间的超平面 \(\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b=0\right. , 其中 \left.\boldsymbol{w}, \boldsymbol{x} \in \mathbb{R}^{n}\right)\) :
-
超平面方程不唯一
-
法向量 \(\boldsymbol{w}\) 垂直于超平面
-
法向量 \(\boldsymbol{w}\) 和位移项 \(b(或者-\theta)\) 确定一个唯一超平面
-
法向量 \(\boldsymbol{w}\) 指向的那一半空间为正空间, 另一半为负空间
感知机学习策略
随机初始化 \(\boldsymbol{w}, b\) ,将全体训练样本代入模型找出误分类样本,假设此时误分类样本集合为 \(M \subseteq T\) ,对任意一个误分类样本 \((\boldsymbol{x}, y) \in M\) 来说,当 \(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}- \theta \geqslant 0\) 时,模型输出值为 \(\hat{y}=1\) ,样本真实标记为 y = 0 ,反之,当 \(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}-\theta<0\) 时,模型输出值为 \(\hat{y}=0\) ,样本真实标记为 y = 1 。综合两种情形可知,以下公式恒成立:
所以,给定数据集 \(T\) ,其损失函数可以定义为:
显然,此损失函数是非负的。如果没有误分类点,损失函数值是 0 。而且,误分类点越少,误分类点离超平面越近,损失函数值就越小。
如何优化损失函数
具体地,给定数据集
其中 \(\boldsymbol{x}_{i} \in \mathbb{R}^{n}, y_{i} \in\{0,1\}\) ,求参数 \(\boldsymbol{w}, \theta\) ,使其为极小化损失函数的解:
其中 \(M \subseteq T\) 为误分类样本集合。若将阈值 \(\theta\) 看作一个固定输入为 -1 的“哑节点",即
根据该式,可将要求解的极小化问题进一步简化为
感知学习算法
当误分类样本集合 \(M\) 固定时,那么可以求得损失函数 \(L(\boldsymbol{w})\) 的梯度为
感知机的学习算法具体采用的是随机梯度下降法,也就是极小化过程中不是一次使 \(M\) 中 所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。所以权重 \(\boldsymbol{w}\) 的更新公式为
相应地, \(\boldsymbol{w}\) 中的某个分量 \(w_{i}\) 的更新公式即为
最终解出来的 \(\boldsymbol{w}\) 通常不唯一。
感知机只有输出层神经元进行激活函数处理,即只有一层功能神经元,其学习能力非常有限,只能解决线性可分问题。
若要解决非线性可分问题(比如异或),需要用到多层功能神经元。
多层前馈网络
下图的是更常见的神经网络,上下层神经元全互联,神经元之间不存在同层连接,也没有跨层连接,通常被称为多层前馈神经网络。
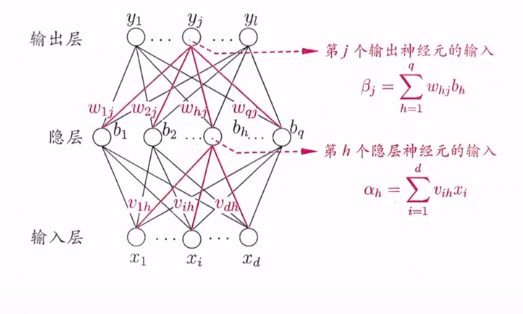
输入层仅接收外界输入,不进行函数处理,隐层和输入层包含功能性神经元,对信号进行加工。因此图5.6(a)是两层神经网络,为了避免歧义可称为单隐层神经网络。神经网络的学习过程就是调整神经元之间的连接权重以及每个功能神经元的阈值。
将神经网络(记为 NN )看作一个特征加工函数
(单输出)回归:后面接一个 \(\mathbb{R}^{l} \rightarrow \mathbb{R}\) 的神经元,例如:没有激活函数的神经元
分类:后面接一个 \(\mathbb{R}^{l} \rightarrow[0,1]\) 的神经元,例如:激活函数为 \(\operatorname{sigmoid}\) 函数的神经元(损失函数用交叉熵损失函数)
在模型训练过程中,神经网络 (NN) 自动学习提取有用的特征,因此,机器学习向“全自动数据分析”又前进了一步。
误差逆传播算法
假设多层前馈网络中的激活函数全为 \(\operatorname{sigmoid}\) 函数,且当前要完成的任务为一个(多输出)回归任务,因此损失函数可以采用均方误差(分类任务则用交叉熵)。对于某个训练样本 \(\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{k}\right)\) ,其中 \(\boldsymbol{y}_{k}=\left(y_{1}^{k}, y_{2}^{k}, \ldots, y_{l}^{k}\right)\) ,假定其多层前馈网络的输出为 \(\hat{\boldsymbol{y}}_{k}= \left(\hat{y}_{1}^{k}, \hat{y}_{2}^{k}, \ldots, \hat{y}_{l}^{k}\right)\) ,则该单个样本(随机梯度下降只需用单个样本求梯度即可)的均方误差(损失)为
误差逆传播算法 (BP算法) :基于随机梯度下降的参数更新算法
其中只需推导出 \(\nabla_{w} E\) 这个损失函数 \(E\) 关于参数 \(w\) 的一阶偏导数(梯度)即可(链式求导)。值得一提的是,由于 \(\mathrm{NN}(\boldsymbol{x})\) 通常是极其其复杂的非凸函数, 不具备像凸函数这种良好的数学性质,因此随机梯度下降不能保证一定能走到全局最小值点,更多情况下走到的都是局部极小值点。
公式推导参照:南瓜书
BP算法步骤:
'''
输入: 训练集D; 学习率lr
过程:
1: 在(0, 1)范围内随机初始化网络中所有连接权和阈值
2: repeat
3: for all (x_k, y_k) ∈ D do
4: 根据当前参数和式1计算当前样本的输出y_hat_k;
5: 根据式8计算输出层神经元的梯度项g_j;
6: 根据式13计算隐层神经元的梯度向e_h;
7: 根据式9-12更新连接权w_hj, v_ih与阈值theta_j与gamma_h
8: end for
9: until 达到停止条件
输出: 连接权与阈值确定的多层前馈神经网络
'''
深度学习
典型的深度学习就是很深层的神经网络。但是多隐层神经网络难以直接用经典算法(如BP算法)进行训练,因为误差在多隐层内传播时,往往会“发散”而不能收敛到稳定状态。
无监督逐层训练是多隐层网络训练的有效手段,主要思想为每次训练一层隐结点,训练时将上一层隐结点的输出作为输入,而本层隐结点的输出作为下一层隐结点的输入,这称为预训练。预训练全部完成后再对整个网络进行微调训练。
另一种节省训练开销的策略是权共享,即让一组神经元使用相同的连接权。这个策略在 CNN 中发挥了作用。
我们也可以把深度学习理解为通过多层处理逐渐将初始的底层特征表示转化为高层特征表示后,用简单模型即可完成复杂的分类等学习任务的特征学习或表示学习。
