KMP算法(串的模式匹配算法)(未完待续......)
KMP算法的实现
1.基本原理
在暴力破解算法(BF算法)中,模式串需要一个一个来跟主串进行对比,若有一个不相同,则主串前进一位,继续从头开始进行比较,这样比较的最坏时间复杂度为O(mn),例:‘aaaaaaaaab’和‘aaab’,需要比较到最后一个才能成功,效率太过低下。
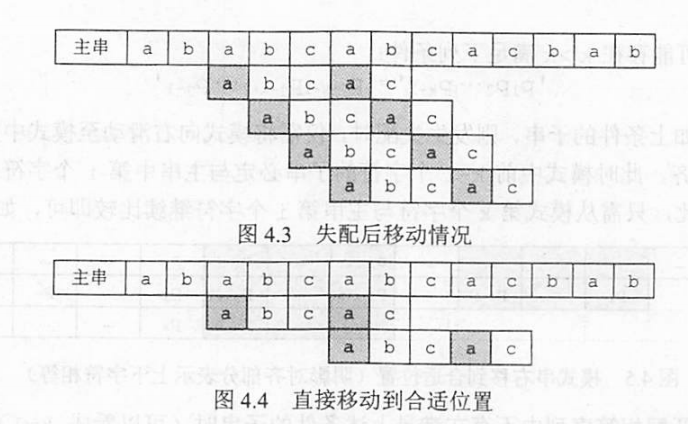
KMP算法的原理是,找到模式串的最大相等前后缀(所以与主串无关),再次进行比较时,相等的部分就可以跳过比较,从下一位开始进行比较。(如下图4.4)
2.部分匹配值 (参考:阮一峰的网络日志)
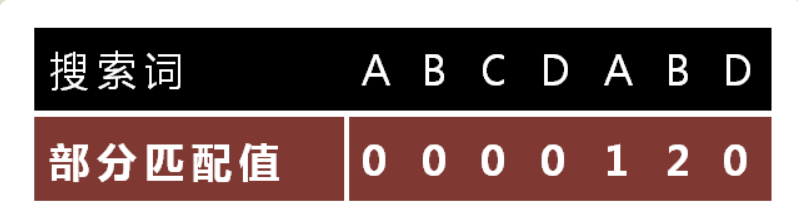
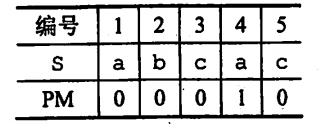
部分匹配值即串的最大前后缀个数
部分匹配值跟next数组是不同的,部分匹配值是包含本元素所组成的字符串的最大前后缀个数,例:‘ABCDA’的最大前后缀个数为1,所以上表中第五个A的部分匹配值是1。
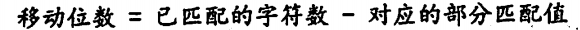 (已匹配正确的字符 - 最后一个匹配正确的字符的部分匹配值)
(已匹配正确的字符 - 最后一个匹配正确的字符的部分匹配值)
例:


3.next数组

因为每次匹配错误时,都要去寻找前一位的部分匹配值,所以,为了方便,将部分匹配表全部进行右移即可得到
 →
→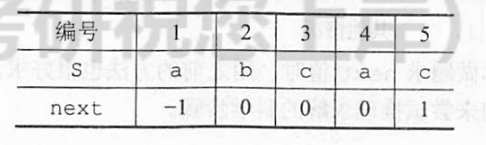
此时每一位对应的即是前一位的部分匹配值,所以如果当前字符匹配错误,直接调用当前的next[j]即可。
上式就变为了:
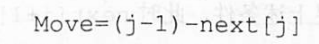

为了使公式更加简洁,计算简单,将next数组整体加一得到:
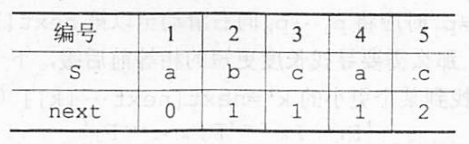
next[j]的含义是:在子串的第j个字符与主串发生失配时,则跳到子串的next[j]位置重新与主串当前位置进行比较。
所以此时若失配,子串的比较指针回退到 j = next[j]
4.next数组的计算

(1)当模式串第一个位置就失配时,next[1]=0,即将模式串整体向右移一位。
(2)当模式串已匹配相等序列中不存在满足上述条件的子串时,应该将模式串右移j-1位,让主串第i个字符和模式串第一个字符进行比较。
综上得到next函数的公式:
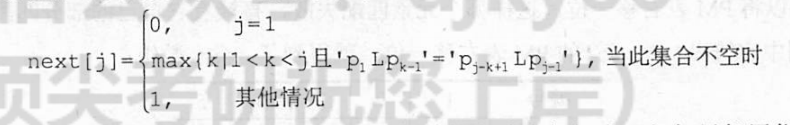
重点:手动求next函数

next[j+1]中存储的是前面的字符串的部分匹配值(最长前后缀)+1
所以若P(k)=P(j),则next[j+1]=next[j]+1
尚未搞懂:

总结next数组的求法:前两位是固定的,分别是0和1,后边的求法:假设模式串为‘abcdacd’,则next[3]=‘ab’的最大前后缀大小+1,next[4]=‘abc’的最大前后缀大小+1,......
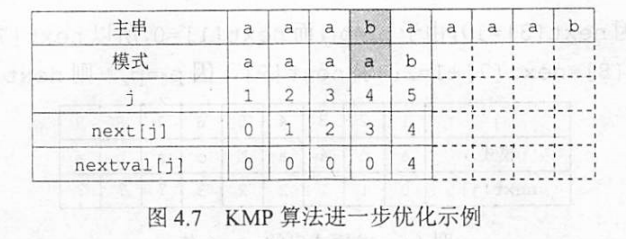
5.KMP算法的进一步优化(nextval())
原理:倘若模式串中失配的字符与他next[j]所指向的字符相同,则会进行一次无意义的匹配,所以应继续寻找他next[j]指向的字符的next[j]值,如果还是跟失配的字符相等就继续寻找,一直到nextval[j]=0
参考视频:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号