C++并发与多线程学习笔记--future成员函数、shared_future、atomic
- std::future的其他成员函数
- std::shared_future
- 原子操作、概念、基本用法
多线程主要是为了执行某个函数,本文的函数的例子,采用如下写法
int mythread()
{
cout << "my thread start, and thread id is " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(1000);
std::this_thread::sleep_for(dura);
cout << "my thread end, and thread id is " << std::this_thread::get_id() << endl;
return 5;
}
int mythread1(int aa)
{
cout << "my thread start, and thread id is " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(1000);
std::this_thread::sleep_for(dura);
cout << "my thread end, and thread id is " << std::this_thread::get_id() << endl;
return 5;
}
int mythread2(std::future<int> &tmp)
{
cout << "my thread start, and thread id is " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(1000);
std::this_thread::sleep_for(dura);
cout << "my thread end, and thread id is " << std::this_thread::get_id() << endl;
return 5;
}
std::future的其他成员函数
成员函数wait_for有三个返回值
如果遇到以下情况
1)主线程等待子线程执行完毕,然后返回结果,线程有三种状态,那么就要用到std::future_status
enum class future_status { // names for timed wait function returns
ready,
timeout,
deferred
};
在主函数中写
cout << "Main thead " << std::this_thread::get_id() << endl;
std::future<int> result = std::async(std::launch::deferred, mythread);
//如果第一个参数使用 std::launch::deferred,线程会被延迟执行,到了get
cout << "continue....!" << endl;
std::future_status status = result.wait_for(std::chrono::milliseconds(6000));
if (status == std::future_status::timeout) {
cout << "线程执行超时,线程还未执行完" << endl;
//主线程想要等待子线程的结果,如果超时,状态就会变成超时
}
else if (status == std::future_status::ready) {
cout << "线程成功执行完毕,返回" << endl;
cout << "result:" << result.get() << endl;
}
else if (status == std::future_status::deferred)
{
//如果async的第一个参数被设置为延迟执行,std::launch::deferred, 则本条件成立
cout << "线程被延迟执行" << endl;
cout << "result:" << result.get() << endl;
//这个时候实际上没有创建一个新的子线程,函数在主线程中执行
}
ready表示线程成功返回、timeout表示等待超时(线程没有成功返回)、deferrd表示延迟执行(调用get才执行)。注意async的第一参数是否为deferred。
std::shared_future
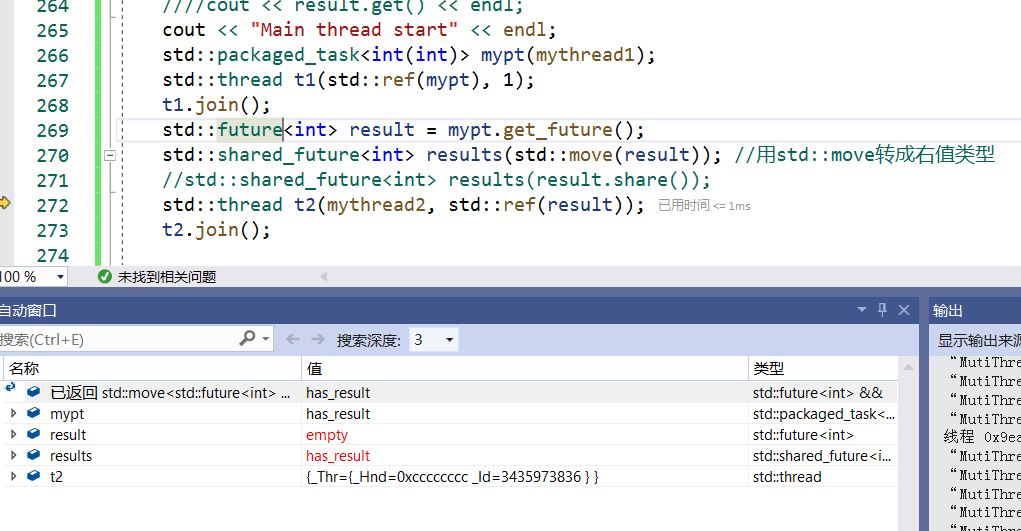
futured对象中的get只能获取一次,为什么第二次get会得到一个异常,这个异常主要就是因为get函数的设计,是一个移动语义,相当于把里面的对象移动到另外一个内存中,再次调用的话就会报异常。如果有多个线程都想要获得get的结果,此时就需要使用std::shared_future。
std::shared_future也是一个类模板,此时get函数就不是转移数据,而是复制数据。
get多次的情况
int mythread3(std::shared_future<int>& tmp)
{
cout << "my thread start, and thread id is " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(1000);
std::this_thread::sleep_for(dura);
cout << tmp.get() << endl;
cout << tmp.get() << endl;
cout << "my thread end, and thread id is " << std::this_thread::get_id() << endl;
return 5;
}
在main函数中
cout << "Main thread start" << endl; std::packaged_task<int(int)> mypt(mythread1); std::thread t1(std::ref(mypt), 1); t1.join(); std::future<int> result = mypt.get_future(); //std::shared_future<int> results(std::move(result)); //用std::move转成右值类型 std::shared_future<int> results(result.share()); std::thread t2(mythread3, std::ref(results)); t2.join();
原子操作、概念、基本用法
互斥量:用来在多线程编程中,保护共享数据:用一把锁把共享数据锁住,操作完毕之后再把锁打开。
一个线程读变量值,另外一个线程往变量中写值。
//读线程 int tmpvalue = atomvalue; //写线程 atomvalue = 0;
读线程A和写线程B,如果写线程不断地往下写值,可能是读到新的值,也可能读到老的值,真正情况,会读到一个中间值,不可预料。即使一个简单的读或者幅值语句,也是分成很多步骤,一条语句会被拆成三四条汇编代码。
例子
int g_mycount = 0; //创建一个全局变量
void mythred_write() {
//线程入口函数
for (int i = 0; i < 1000000; i++) {
g_mycount++;
}
return;
}
main函数中
std::thread myobj1(mythred_write); std::thread myobj2(mythred_write); myobj1.join(); myobj2.join(); //两个线程执行完毕 cout << "加完的结果" << g_mycount << endl;
程序的执行结果,此时程序的执行结果并不是想象中的1,000,000+1,000,000:
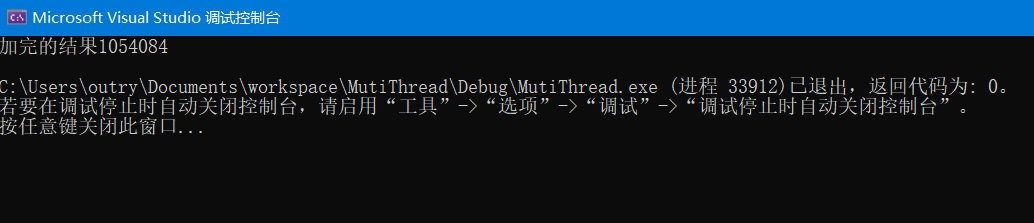
返回值和我们想像中的不符合,线程在操作的时候不稳定,代码被拆分为多条汇编语言执行,加法的代码没有成功执行完,就被打断。可以用互斥量的知识来解决问题。
std::mutex mymutex;
//线程入口函数修改
for (int i = 0; i < 1000000; i++) {
mymutex.lock();
g_mycount++;
mymutex.unlock();
}
除了用互斥量加锁的操作,用别的操作使得程序也达到同样的效果-->原子操作,无锁的多线程并发编程方式,或者也可以理解成原子操作是在多线程中不会被打断的程序执行片段。效率上而言,原子操作比互斥量效率上更胜一筹。有一点需要注意,互斥量,不仅仅加锁一行代码,原子操作一般针对的是一个变量,而不是一个代码段。在计算机中,原子操作是不可分割的操作,不可能出现中间状态。
std::atomic_int g_mycount = 0; //创建一个全局变量
atomic 是用来封装某给类型的值,可以定义成一个原子的全局量。
std::atomic<int> g_mycount = 0; //创建一个全局变量
像操作一个int对象一样来操作变量。根据范例,实用性为主,记住几个基本的用法范例即可。
心得体会:
1) std::atomic针对变量的赋值和判断,原子操作不能用于太复杂的操作。原子操作有用处,但是用处是有限的,在实际工作中,原子操作用的不太多,一般用于计数或者统计,累计发送出去了多少个数据包,接收了多少个数据包。实际工作中,如果有多个线程用来计数,可以考虑一下采用std::atomic变量。
2) 实际工作中,写商业代码,要谨慎行动,不太清楚这行代码有什么副作用,可以写一小段代码论证想法是否正确。或者干脆不使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号