
ElasticSearch-倒排索引
什么是倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
倒排索引的内部结构
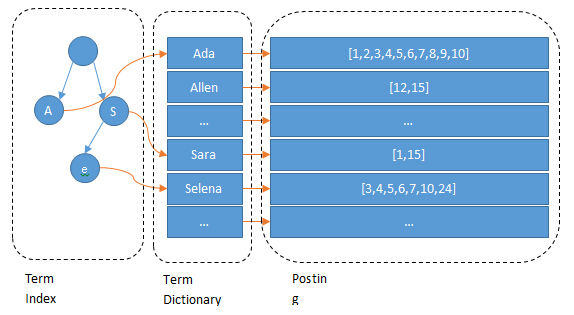
Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词) Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引 Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合 Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。(实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Python中的元组,或者Java中的对象)
为什么Elasticsearch/Lucene检索可以比mysql快?
Mysql只有term dictionary这一层,是以b-tree排序的方式存储在磁盘上的。检索一个term需要若干次的random access的磁盘操作。而Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。
数据压缩算法
Term index的压缩
Lucene使用FST算法以字节的方式来存储所有的Term,重复利用Term Index的前缀和后缀,使Term Index小到可以放进内存,减少存储空间,不过相对的也会占用更多的cpu资源。
Finite StateTransducers,简称 FST,通常中文译作有穷状态转换器,在语音识别和自然语言搜索、处理等方向被广泛应用。FST的功能类似于字典,可以表示成FST<Key, Value>的形式。其最大的特点是,可以用O(length(key))的复杂度来找到key对应的value,也就是说查找复杂度仅取决于所查找的key长度。
posting list的压缩
1.Frame Of Reference
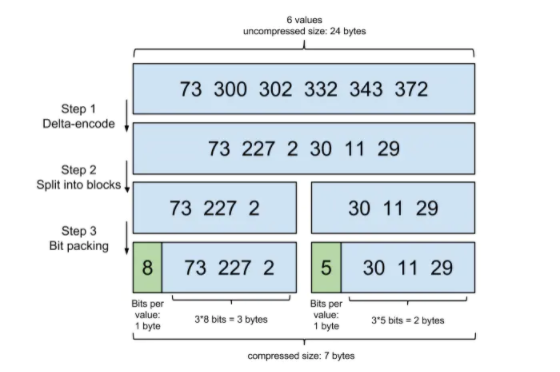
step1:在对posting list进行压缩时进行了正序排序。 step2:通过增量将73后面的大数变成小数存储增量值。 step3: 转换成二进制,取占最大位的数,227占8位,前三个占八位,30占五位,后三个数每个占五位。
2.Roaring bitmaps

step1:从小到大进行排序。 step2:将大数除以65536,用除得的结果和余数来表示这个大数。 step3::以65535为界进行分块。
为什么是以65535为界限呢
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short[]存着方便。
为什么用4096来区分大块还是小块呢
都说程序员的世界是二进制的,4096*2bytes = 8192bytes < 1KB, 磁盘一次寻道可以顺序把一个小块的内容都读出来,再大一位就超过1KB了,需要两次读。
文档数量的压缩
一种常见的压缩存储时间序列的方式是把多个数据点合并成一行。Opentsdb支持海量数据的一个绝招就是定期把很多行数据合并成一行,这个过程叫compaction。类似的vivdcortext使用mysql存储的时候,也把一分钟的很多数据点合并存储到mysql的一行里以减少行数。

可以看到,行变成了列了。每一列可以代表这一分钟内一秒的数据。
参考:Elasticsearch之数据压缩算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号