
ElasticSearch-集群
分布式特性
Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据。Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。这里列举了一些在后台自动执行的操作:
- 分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
集群配置
修改elasticsearch.yml
# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了 cluster.name: es-cluster # 每一个节点的名称,必须不一样 node.name: es-node1 # http端口(使用默认即可) http.port: 9200 # 主节点,作用主要是用于来管理整个集群,负责创建或删除索引,管理其他非master节点 node.master: true # 数据节点,用于对文档数据的增删改查 node.data: true # 集群列表 discovery.seed_hosts: ["192.168.1.184", "192.168.1.185", "192.168.1.186"] # 启动的时候使用一个master节点 cluster.initial_master_nodes: ["es-node1"]

多台主机构成了一个集群,每台主机称作一个节点(Node)。在图中,每个 Node 都有三个分片,其中 P 开头的代表 Primary 分片,即主分片,R 开头的代表 Replica 分片,即副本分片。所以图中主分片 1、2,副本分片 0 储存在 1 号节点,副本分片 0、1、2 储存在 2 号节点,主分片 0 和副本分片 1、2 储存在 3 号节点,一共是 3 个主分片和 6 个副本分片。同时我们还注意到 1 号节点还有个 MASTER 的标识,这代表它是一个主节点,它相比其他的节点更加特殊,它有权限控制整个集群,比如资源的分配、节点的修改等等。
- 主节点:即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
- 数据节点:即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
- 负载均衡节点:也称作 Client 节点,也称作客户端节点。当一个节点既不配置为主节点,也不配置为数据节点时,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
- 预处理节点:也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点
一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但如果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
分布式原理
- 一个index包含多个shard,也就是一个index存在多个服务器上
- 每个shard都是一个最小工作单元,承载部分数据,比如有三台服务器,现在有三条数据,这三条数据在三台服务器上各方一条.
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?
shard_num = hash(_routing) % num_primary_shards
其中 _routing 是一个可变值,默认是文档的 _id 的值 ,也可以设置成一个自定义的值。 _routing 通过 hash 函数生成一个数字,然后这个数字再除以 num_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。

假设有一个100个分片的索引。当一个请求在集群上执行搜索时会发生什么呢?
1. 这个搜索的请求会被发送到一个节点
2. 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
3. 每个分片执行这个搜索查询并返回结果
4. 结果在通道节点上合并、排序并返回给用户
数据写入流程
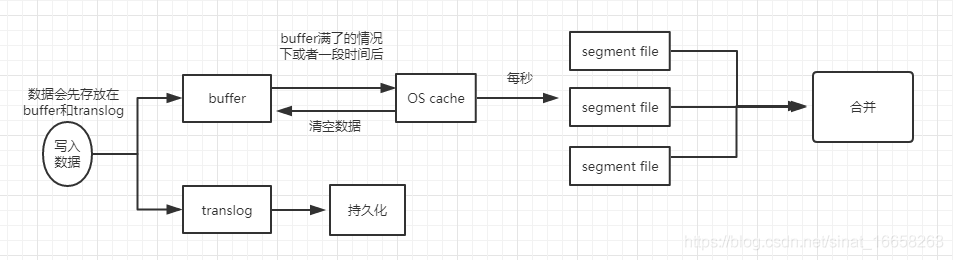
- 数据先写入到buffer里面,在buffer里面的数据时搜索不到的,同时将数据写入到translog日志文件之中
- 如果buffer快满了,或是一段时间之后(定时),就会将buffer数据refresh到一个新的OS cache之中,然后每隔1秒,就会将OS cache的数据写入到segment file之中,但是如果每一秒钟没有新的数据到buffer之中,就会创建一个新的空的segment file,只要buffer中的数据被refresh到OS cache之中,就代表这个数据可以被搜索到了。当然可以通过restful api 和Java api,手动的执行一次refresh操作,就是手动的将buffer中的数据刷入到OS cache之中,让数据立马搜索到,只要数据被输入到OS cache之中,buffer的内容就会被清空了。同时进行的是,数据到shard之后,就会将数据写入到translog之中,每隔5秒将translog之中的数据持久化到磁盘之中
- 重复以上的操作,每次一条数据写入buffer,同时会写入一条日志到translog日志文件之中去,这个translog文件会不断的变大,当达到一定的程度之后,就会触发commit操作。
- 将一个commit point写入到磁盘文件,里面标识着这个commit point 对应的所有segment file
- 强行将OS cache 之中的数据都fsync到磁盘文件中去。
解释:translog的作用:在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志问价之中,一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件的数据,恢复到内存buffer和OS cache之中。 - 将现有的translog文件进行清空,然后在重新启动一个translog,此时commit就算是成功了,默认的是每隔30分钟进行一次commit,但是如果translog的文件过大,也会触发commit,整个commit过程就叫做一个flush操作,我们也可以通过ES API,手动执行flush操作,手动将OS cache 的数据fsync到磁盘上面去,记录一个commit point,清空translog文件
补充:其实translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。 - 如果时删除操作,commit的时候会产生一个.del文件,里面讲某个doc标记为delete状态,那么搜索的时候,会根据.del文件的状态,就知道那个文件被删除了。
- 如果时更新操作,就是讲原来的doc标识为delete状态,然后重新写入一条数据即可。
- buffer每次更新一次,就会产生一个segment file 文件,所以在默认情况之下,就会产生很多的segment file 文件,将会定期执行merge操作
- 每次merge的时候,就会将多个segment file 文件进行合并为一个,同时将标记为delete的文件进行删除,然后将新的segment file 文件写入到磁盘,这里会写一个commit point,标识所有的新的segment file,然后打开新的segment file供搜索使用。
参考:https://blog.csdn.net/sinat_16658263/article/details/90444038

 浙公网安备 33010602011771号
浙公网安备 33010602011771号