
ElasticSearch-IK分词器
IK分词器插件安装
1.安装插件并重启
root@ryj-dev10:/opt/modules# docker container ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
592f35773efc kibana:7.10.1 "/usr/local/bin/dumb…" 2 days ago Up 47 hours 0.0.0.0:5601->5601/tcp kibana
3fb9036b3034 elasticsearch:7.10.1 "/tini -- /usr/local…" 13 days ago Up 2 days 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp es
root@ryj-dev10:/opt/modules# docker container exec -it 3fb9036b3034 sh
sh-4.4# ls
sh-4.4# sh /usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
sh-4.4# ls
analysis-ik
sh-4.4# exit
exit
root@ryj-dev10:/opt/modules# docker container restart 3fb9036b3034
3fb9036b3034
2.提交镜像
root@ryj-dev10:/opt/modules# docker container commit -a ryj -m 增加IK分词器 3fb9036b3034 elasticsearch:7.10.1-IK sha256:6e0721efe09d8e782e446312877dad60d7636f2d4335270ed60548f875e578b3 root@ryj-dev10:/opt/modules# docker image list REPOSITORY TAG IMAGE ID CREATED SIZE elasticsearch 7.10.1-IK 6e0721efe09d 13 seconds ago 791MB kibana 7.10.1 3e014820ee3f 6 weeks ago 992MB elasticsearch 7.10.1 558380375f1a 6 weeks ago 774MB harbor.lingda.com/common/java 8-jre-alpine fdc893b19a14 3 years ago 108MB
IK分词器演示
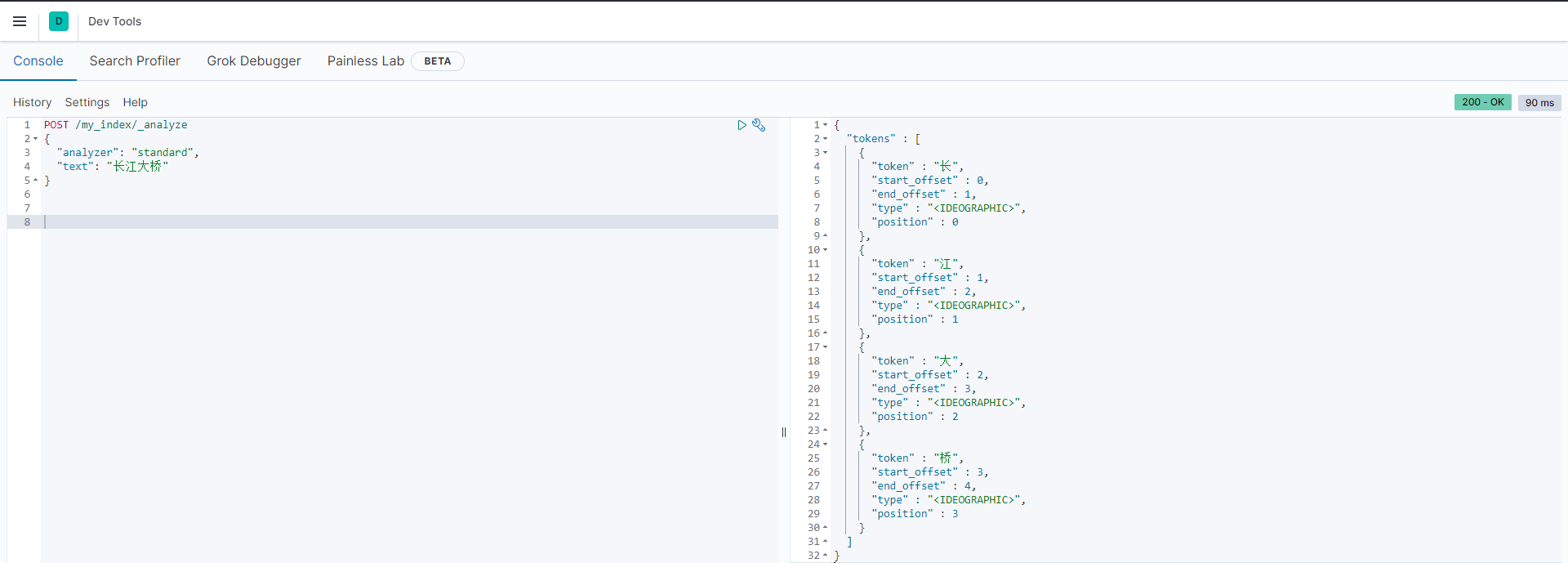
默认的:根据中文逐字分词
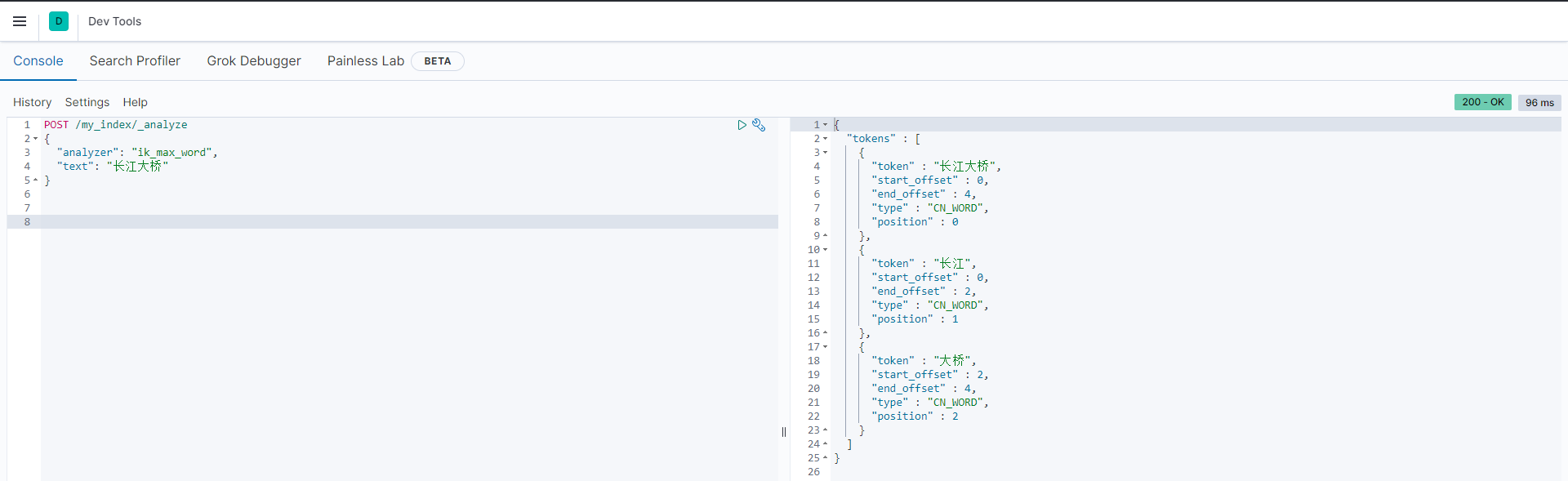
IK:根据词库分词
查询示例
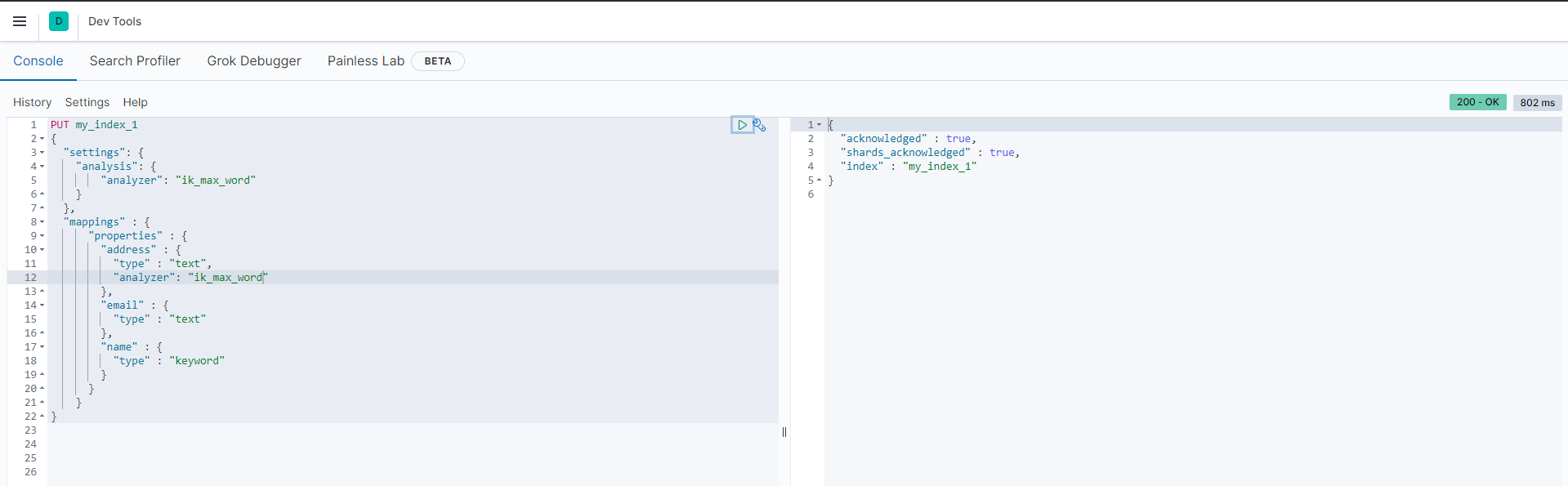
1.建立新Index
2.插入数据
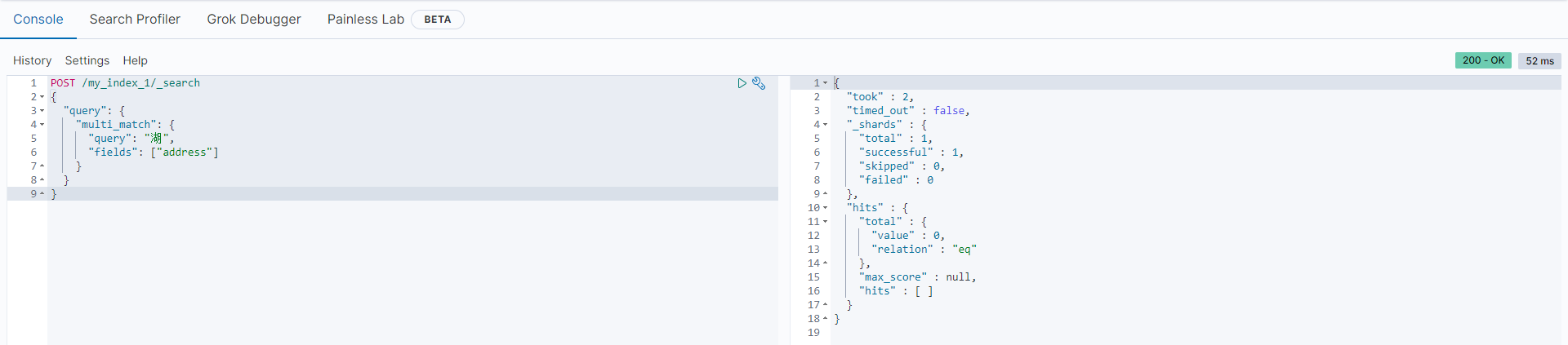
3.查询
用了IK分词器之后,通过【湖】查不到数据,但是可以通过【湖北】查到,因为"中国湖北省武汉市"分词后没有【湖】这个词了
分词器原理
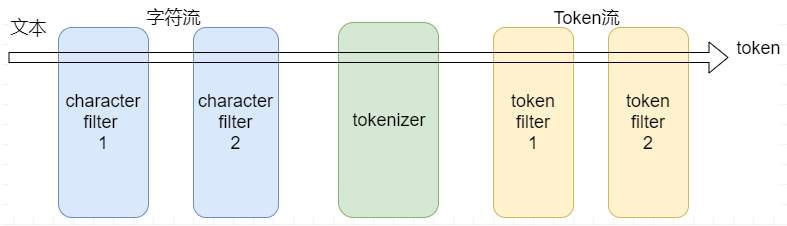
- Character filters:字符过滤器以字符流的形式接收原始文本,并可以通过添加、删除或更改字符来转换该流。一个分析器可能有0个或多个字符过滤器。
- Tokenizer:一个分词器接收一个字符流,并将其拆分成单个token (通常是单个单词),并输出一个token流。
- Token filters:token过滤器接收token流,并且可能会添加、删除或更改tokens。例如,一个lowercase token filter可以将所有的token转成小写。不允许token过滤器更改每个token的位置或字符偏移量。一个分析器可能有0个或多个token过滤器,它们按顺序应用。
在全文搜索(Fulltext Search)中,词(Term)是一个搜索单元,表示文本中的一个词,标记(Token)表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,其工作流程是:
- 首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
- 过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记,
- 然后,标记过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
- 最终,过滤之后的标记流被存储在倒排索引中;
- ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号