Python_中文的处理、编码转换(py2和py3的简单比较)
一、编码转换py2和py3对中文的处理
py2:
1 文件要存为utf-8
2 文件第一行声明为:#encoding=utf-8
#coding=utf-8
#coding:utf-8
#_*_coding:UTF-8_*_
3 所有的中文前面加u,表示unicode
py3:
1 文件要存为utf-8
2 声明可以不加,加上也没问题
3 中文前面不用加u,加了也没事。
不用utf-8的时候,需要第一行声明(如:#encoding = gbk)
二、编码转换
1、说明py -2
py2:utf-8,文件第一行也声明为utf-8
str1="我们" 类型:str
str1.decode() 默认是:ascii
str1.decode("utf-8")
str1.decode("utf-8")==u"我们"
str1.decode("utf-8").encode("utf-8")==str1
py2:ansi,文件第一行也声明为gbk
str1="我们" 类型:str
str1.decode() 默认是:ascii
str1.decode("gbk")==u"我们"
str1.decode("gbk").encode("gbk")== str1
2、utf-8:
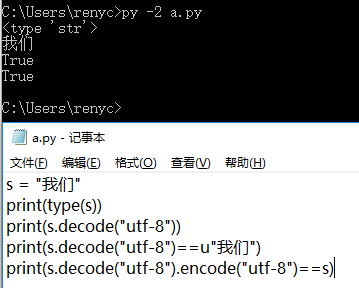
#encoding=utf-8
s = "我们"
print(type(s))
print(s.decode("utf-8"))
print(s.decode("utf-8")==u"我们")
print(s.decode("utf-8").encode("utf-8")==s)
非交互模式下运行以上代码
3、Ansi
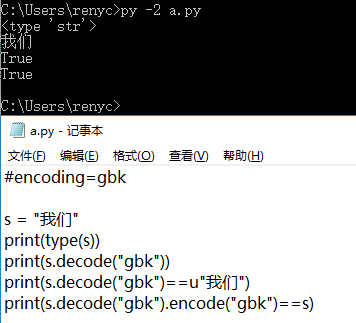
#encoding=gbk
s = "我们"
print(type(s))
print(s.decode("gbk"))
print(s.decode("gbk")==u"我们")
print(s.decode("gbk").encode("gbk")==s)
非交互模式下运行以上代码
4、py -3和py-2转码的区别说明
py2:str类型等价于py3的bytes类型
py2:str类型例子: s ="中国"
py2的Unicode类型例子:s =u"中国"
p3:str类型等价于py2的unicode类型
py3 的str类型:s = "中国"
py3 的byte类型: s= "中国".encode("utf-8")
encode:不管是2还是3,只能对unicode对象来用
在py2:将unicode类型的对象,转换为str类型
在py3:将str类型的对象,转换为了bytes类型
cmd默认是gbk编码
py2默认是ascii编码
计算机内存里是unicode编码
存储格式可为gbk(ansi)或utf-8等等
涉及到存储传输的byte
只有在unicode下才能将utf-8与gbk互转
------------------------------------------------------------
py3时:
a="中国" 和a=u"中国" 是一个意思,都表示str类型unicode存储类型
c=b"good" 表示str类型bytes存储类型
py2时:
a="中国" 和a=b"中国" 是一个意思,表示str类型bytes存储类型
a=u"中国" 表示str类型unicode存储类型
Python3默认为“utf-8”
>>> import sys
>>> sys.getdefaultencoding()#查看默认编码方式 'utf-8' >>> "我们".encode() b'\xe6\x88\x91\xe4\xbb\xac' >>> "我们".encode().decode() '我们'
>>> "我们".encode("utf-8").decode("utf-8") '我们'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号