
Python_正则表达式
正则表达式
一、说明
正则表达式:精确匹配或者模糊匹配
比如:匹配所有日志中的ip,匹配所有的响应时间。
1、简单实例+说明:
import re re.match(r"1","1abc") <_sre.SRE_Match object; span=(0, 1), match='1' >>> type(re.match(r"1","1abc")) <class '_sre.SRE_Match'>
参数说明
match——表示从开头匹配,不匹配会报错.search是全部
r"1"——是正则表达式
"1abc" ——是匹配的目标字符串
2、没有匹配结果是空
>>> import re >>> re.match(r"1","abc")#有转义字符时,必须要有r >>> print (re.match(r"1","abc")) None
二、re.search().group()匹配字段
1、参数说明
(1)带字母的
r表示元字符
\d匹配数字
\d+匹配多个数字
D:匹配非数字
\w:匹配数字和字母
\W:匹配非数字和字母
\s:匹配空白()
\S:匹配非空白
(2)带符号的
+:表示匹配一个或多个
*:表示匹配0个或多个,必须从开头匹配的,开头不是则返回空
re.match()
*或者+正则表达式的贪婪性:尽量多匹配
?限制贪婪,仅仅匹配一个,0次或1次
{}指定匹配内容的具体个数
非贪婪模式,仅匹配1个
2、简单例子(参数说明)
re.search(r"\d","a123ed").group()#匹配数字,一个
re.search(r"\d+","a123ed").group()#匹配多个数字
re.search(r"\D","a123ed").group()#匹配非数字,一个
re.search(r"\D+","a123ed").group()#匹配多个非数字
re.search(r"\w+","a123ed").group()#匹配数字+字母,一个,空格不可以
re.search(r"\W+","a1@#@d").group()#匹配非数字+字母,空格不可以
re.search(r"\d+","a1dd2dd3dded").group()

re.search(r"a+\s+a","113a a#@d").group()#匹配含空白的
re.search(r"\S+","113a a#Hd").group()#匹配含非空白的

re.search(r"a\s+a","113 frf")#+表示多个
三、re.findall()和search的比较
只有findall是匹配多个,剩下的都是一个
只有findall返回的是列表,其他返回的都是字符串
re.findall(r"\d","a123ed")#匹配所有数字以列表返回,没有后面的group()
Import re
re.search(r"\d","abcd1ed")

>>> re.search(r"\d","abcd1ed").group()#后面要用group才能打印结果
'1'
re.search(r"cd\ded","abcd1ed").group()#匹配拼接的字段

re.search(r"\d+","a123ed").group()#匹配多个数字
四、匹配连续字母{}
s = “i am a goodd boy” if re.search(r"[a-zA-Z]{5}",s): print("got it") else: print("no")
五、分组
import re
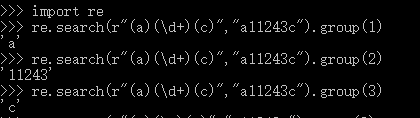
re.search(r"(a)(\d+)(c)","a11243c").group(1)
re.search(r"(a)(\d+)(c)","a11243c").group(2)
re.search(r"(a)(\d+)(c)","a11243c").group(3)
re.search(r"(a)(\d+)(c)","a11243c").group()#默认全部匹配
'a11243c'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号