Python_urllib相关的应用(证书、超时、文件上传、url编码)
urllib相关的应用(证书、超时、文件上传、url编码)
一、证书相关、禁止警告信息
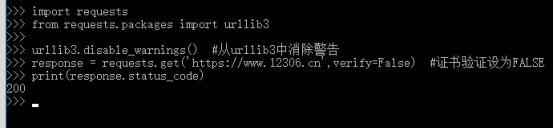
#coding:utf-8 import requests from requests.packages import urllib3 urllib3.disable_warnings() #从urllib3中消除警告 response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE print(response.status_code)
运行:
二、超时异常
1、设置超时时间较短
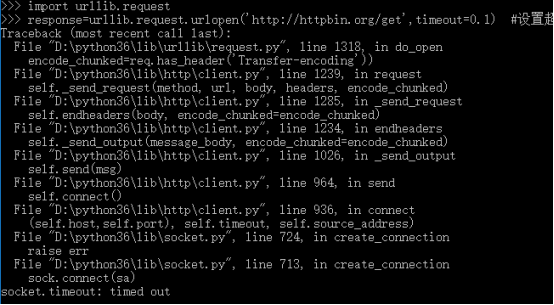
import urllib.request response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1) #设置超时时间为0.1秒,将抛出异常 print(response.read()) #运行结果 #urllib.error.URLError: <urlopen error timed out>
运行:
2、设置超时时间较长,捕获异常
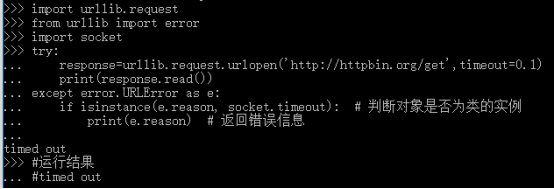
import urllib.request from urllib import error import socket try: response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1) print(response.read()) except error.URLError as e: if isinstance(e.reason, socket.timeout): # 判断对象是否为类的实例 print(e.reason) # 返回错误信息 #运行结果 #timed out
运行:
三、上传文件
>>> url = 'http://httpbin.org/post' >>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})} >>> r = requests.post(url, files=files) >>> r.text { ... "files": { "file": "<censored...binary...data>" }, ...
四、可实现编码(URL编码)
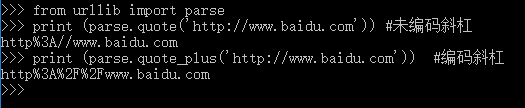
from urllib import parse print (parse.quote('http://www.baidu.com')) #未编码斜杠 print (parse.quote_plus('http://www.baidu.com')) #编码斜杠
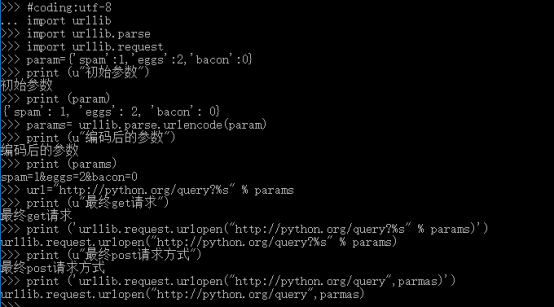
#coding:utf-8 import urllib import urllib.parse import urllib.request param={'spam':1,'eggs':2,'bacon':0} print (u"初始参数") print (param) params= urllib.parse.urlencode(param) print (u"编码后的参数") print (params) url="http://python.org/query?%s" % params print (u"最终get请求") print ('urllib.request.urlopen("http://python.org/query?%s" % params)') print (u"最终post请求方式") print ('urllib.request.urlopen("http://python.org/query",parmas)')