
Python_Xml简介
Xml简介
1、说明:


<?xml version="1.0" encoding="utf-8" ?> <!--this is a test about xml.--> <booklist type="science and engineering"> <book category="math"> <title>learning math</title> <author>张三</author> <pageNumber>561</pageNumber> </book> <book category="Python"> <title>learning Python</title> <author>李四</author> <pageNumber>600</pageNumber> </book> </booklist>

>>> from xml.dom.minidom import parse >>> #minidom解析器打开xml文档并将其解析为内存中的一棵树 ... DOMTree = parse(r"E:\756271310\FileRecv\book.xml") >>> #获取xml文档对象,就是拿到树的根 ... booklist = DOMTree.documentElement >>> >>> for book in booklist.getElementsByTagName("book"): ... print ("本书的分类是:%s" %book.getAttribute("category")) ... for element in ["title","author","pageNumber"]: ... name = book.getElementsByTagName(element)[0].tagName ... name_value = book.getElementsByTagName(element)[0].childNodes[0].data ... print(name,":",name_value) ...
本书的分类是:math
title : learning math
author : 张三
pageNumber : 561
本书的分类是:Python
title : learning Python
author : 李四
pageNumber : 600
>>> print("*"*50)

1、XML没有像HTML那样具有预定义标签,需要程序员自定义标签
2、XML被设计为具有自我描述性,并且是W3C的标准
3、所有的XML元素都必须有一个开始标签和结束标签,省略结束标签是非法的。如: content
4、XML标签对大小写敏感;比如: 下面是两个不同的标签
2、DOM的解析
#coding=utf-8 #从xml.dom.minidom模块引入解析器parse from xml.dom.minidom import parse #minidom解析器打开xml文档并将其解析为内存中的一棵树 DOMTree = parse(r"e:\book.xml") print(type(DOMTree)) #生成了文档类型

(1)获取根元素
booklist = DOMTree.documentElement#自动获取根元素 print(booklist)
(2)找到所有元素
print(u"xml文档内容:\n%s" %DOMTree.toxml())
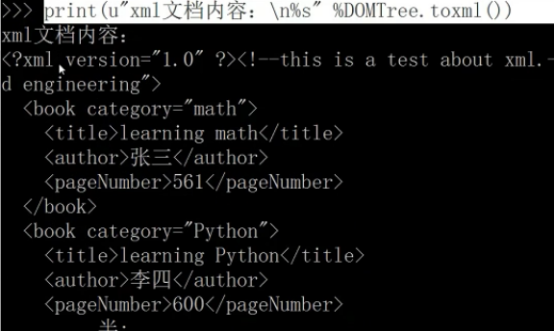
(3)判断根目录是否有属性type
if booklist.hasAttribute("type"): #判断根节点booklist是否有type属性 print(u"booklist元素存在type属性") else : print(u"booklist元素不存在type属性")

(4)获取属性值
if booklist.hasAttribute("type") : #判断根节点booklist是否有type属性,有则获取并打印属性的值 print("Root element is", booklist.getAttribute("type"))

(5)所有book的节点的list集合
books = booklist.getElementsByTagName("book") print(type(books)) print (books)

(6)获取节点的属性值
>>> books[1].getAttribute("category") 'Python'

(7)获取所有子节点
books = booklist.getElementsByTagName("book") print(books[0].childNodes)

(8)获取文本节点的值
是author的下一级节点 >>> books[0].childNodes[3].childNodes[0].data '张三' >>> books[1].childNodes[3].childNodes[0].data '李四'
(9)获取标签名称
>>> books[1].childNodes[3].tagName#Name大写 'author'
(10)练习一:
把所有书的分类属性输出一下
把所有书的具体信息输出一下:名字、作者和书的页数
from xml.dom.minidom import parse #minidom解析器打开xml文档并将其解析为内存中的一棵树 DOMTree = parse(r"e:\book.xml") #获取xml文档对象,就是拿到树的根 booklist = DOMTree.documentElement for book in booklist.getElementsByTagName("book"): print ("本书的分类是:%s" %book.getAttribute("category")) name = book.getElementsByTagName("title")[0].tagName name_value = book.getElementsByTagName("title")[0].childNodes[0].data print(name,":",name_value) author = book.getElementsByTagName("author")[0].tagName author_value = book.getElementsByTagName("author")[0].childNodes[0].data print(author,":",author_value) page_number = book.getElementsByTagName("pageNumber")[0].tagName page_number_value = book.getElementsByTagName("pageNumber")[0].childNodes[0].data print(page_number,":",page_number_value) print("*"*50) *****************************************************************
(11)练习二
from xml.dom.minidom import parse #minidom解析器打开xml文档并将其解析为内存中的一棵树 DOMTree = parse(r"e:\book.xml") #获取xml文档对象,就是拿到树的根 booklist = DOMTree.documentElement for book in booklist.getElementsByTagName("book"): print ("本书的分类是:%s" %book.getAttribute("category")) for element in ["title","author","pageNumber"]: name = book.getElementsByTagName(element)[0].tagName name_value = book.getElementsByTagName(element)[0].childNodes[0].data print(name,":",name_value) print("*"*50) ****************************************************
(12)判断是否有子节点
#coding=utf-8 import xml.dom.minidom from xml.dom.minidom import parse #minidom解析器打开xml文档并将其解析为内存中的一棵树 DOMTree = xml.dom.minidom.parse(r"e:\book.xml") #获取xml文档对象,就是拿到树的根 booklist = DOMTree.documentElement #获取booklist对象中所有book节点的list集合 books = booklist.getElementsByTagName("book") print(u"book节点的个数:", books.length) print(books[0]) if books[0].hasChildNodes(): print(u"存在叶子节点\n", books[0].childNodes) else : print(u"不存在叶子节点")
****************************************************************
(13)判断是否有文本节点/Element节点
>>> isinstance(books[0].childNodes[0],xml.dom.minidom.Text) True >>> isinstance(books[0].childNodes[1],xml.dom.minidom.Element) True
(14)创建文档
#coding=utf-8 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() print(doc)
(15)创建根元素
1)设置根元素的属性
>>> root.setAttribute('company', 'xx科技') >>> value = root.getAttribute('company') >>> value 'xx科技'
2)设置多个属性
>>> root.setAttribute('name', 'gloryroad科技') >>> value = root.getAttribute('name') >>> value 'gloryroad科技'
(16)添加文本节点
#coding=utf-8 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() print(doc) #创建一个根节点Managers对象 root = doc.createElement('company') print(u"添加的xml标签为:", root.tagName) # 给根节点root添加属性 root.setAttribute('name', '光荣之路教育科技有限公司') # 给根节点添加一个叶子节点 ceo = doc.createElement('CEO') #给叶子节点name设置一个文本节点,用于显示文本内容 ceo.appendChild(doc.createTextNode('吴总')) print(ceo.tagName) print(u"给叶子节点添加文本节点成功")
(17)某一节点下的xml打印
print(ceo.toxml())
(18)添加子节点
#encoding=utf-8 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() #创建一个根节点company对象 root = doc.createElement('companys') # 给根节点root添加属性 root.setAttribute('name', u'公司信息') #将根节点添加到文档对象中 doc.appendChild(root) # 给根节点添加一个叶子节点 company = doc.createElement('gloryroad') # 叶子节点下再嵌套叶子节点 name = doc.createElement("Name") # 给节点添加文本节点 name.appendChild(doc.createTextNode(u"光荣之路教育科技公司")) ceo = doc.createElement('CEO') ceo.appendChild(doc.createTextNode(u'吴总')) # 将各叶子节点添加到父节点company中 # 然后将company添加到跟节点companys中 company.appendChild(name) company.appendChild(ceo) root.appendChild(company) print(doc.toxml())
(19)写到文件里
#encoding=utf-8 import codecs#需要引入包 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() #创建一个根节点company对象 root = doc.createElement('companys') # 给根节点root添加属性 root.setAttribute('name', u'公司信息') #将根节点添加到文档对象中 doc.appendChild(root) # 给根节点添加一个叶子节点 company = doc.createElement('gloryroad') # 叶子节点下再嵌套叶子节点 name = doc.createElement("Name") # 给节点添加文本节点 name.appendChild(doc.createTextNode(u"光荣之路教育科技公司")) ceo = doc.createElement('CEO') ceo.appendChild(doc.createTextNode(u'吴总')) # 将各叶子节点添加到父节点company中 # 然后将company添加到跟节点companys中 company.appendChild(name) company.appendChild(ceo) root.appendChild(company) fp = codecs.open('e:\\company.xml', 'w','utf-8') doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding="utf-8") fp.close() ***********************************************
(20)open的方式打开文件
#coding=utf-8 import xml.dom.minidom #在内存中创建一个空的文档 doc = xml.dom.minidom.Document() #创建一个根节点Managers对象 root = doc.createElement('Managers') #设置根节点的属性 root.setAttribute('company', 'xx科技') root.setAttribute('address', '科技软件园') #将根节点添加到文档对象中 doc.appendChild(root) managerList = [{'name' : 'joy', 'age' : 27, 'sex' : '女'}, {'name' : 'tom', 'age' : 30, 'sex' : '男'}, {'name' : 'ruby', 'age' : 29, 'sex' : '女'} ] for i in managerList : nodeManager = doc.createElement('manager') nodeName = doc.createElement('name') #给叶子节点name设置一个文本节点,用于显示文本内容 nodeName.appendChild(doc.createTextNode(str(i['name']))) nodeAge = doc.createElement("age") nodeAge.appendChild(doc.createTextNode(str(i["age"]))) nodeSex = doc.createElement("sex") nodeSex.appendChild(doc.createTextNode(str(i["sex"]))) #将各叶子节点添加到父节点Manager中, #最后将Manager添加到根节点Managers中 nodeManager.appendChild(nodeName) nodeManager.appendChild(nodeAge) nodeManager.appendChild(nodeSex) root.appendChild(nodeManager) #开始写xml文档 fp = open('e:\\company.xml', 'w',encoding='utf-8') doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding="utf-8") fp.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号