PostgreSQL 如何优化索引效率
使用 gin() 创建全文索引后,虽然有走索引,但是当结果集很大时,查询效率还是很底下,
SELECT keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time
FROM keyword
WHERE
update_time is not null and plainto_tsquery('driver') @@ keyword_participle
ORDER BY avg_mon_search DESC
LIMIT 500 OFFSET 0;
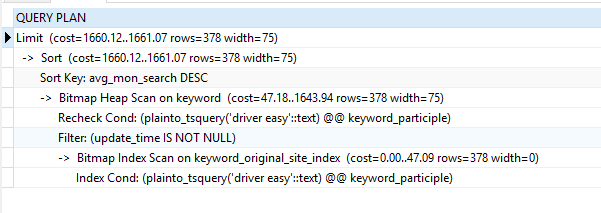
背景: keyword 表中有八千万行数据,建立了 gin( keyword_participle ) 索引,以及其他排序字段的 BTREE 索引
分析:当查询当个单词时,虽然有走全文索引,但是由于返回的结果集很大,有二十多万行数据,而且返回后需要再次进行排序,导致性能严重下降,
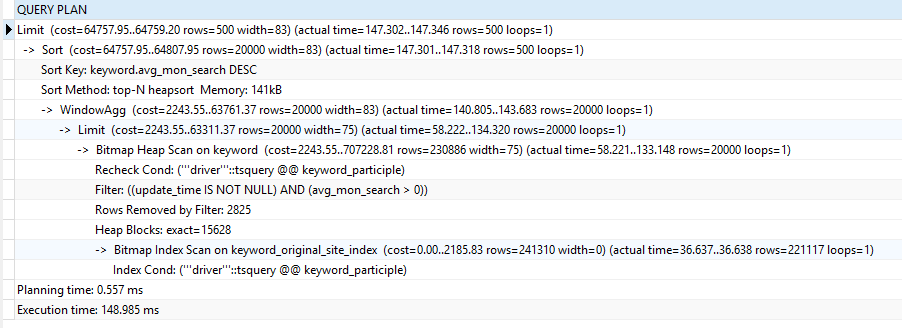
处理方法:限制全文索引返回的结果集行数,结果集变小了,也就减少了排序消耗的时间,况且全文索引分词返回的这么多数据,用户只是查看前面一部分,通过这种方式让用户完善搜索词,知道找到自己想要的结果。
SELECT keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time, count(*) over() as res_count FROM (SELECT keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time
FROM keyword WHERE update_time is not null AND avg_mon_search > 0 AND plainto_tsquery('english_nostop', 'driver') @@ keyword_participle limit 20000
) AS tmp ORDER BY avg_mon_search DESC LIMIT 500 OFFSET 0;
如何优化索引效率
有很多方法告诉你应该如何选择索引,但是没有提索引本身的优化,实际上数据分布会影响索引的效率。
根据索引的扫描特点,对数据进行重分布,可以大幅度优化索引查询的效率。
例如bitmap index scan(按BLOCK ID顺序读取)就是PostgreSQL用于减少离散IO的手段。
1、btree数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
2、hash数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
3、gin数据分布优化
如果是普通类型,则线性相关越好,扫描或返回多条数据的效率越高。
如果是多值类型(如数组、全文检索、TOKENs),则元素越集中(元素聚类分析,横坐标为行号,纵坐标为元素值,数据分布越集中),效率越高。
元素集中通常不好实现,但是我们可以有集中方法来聚集数据,1. 根据元素的出现频率进行排序重组,当用户搜索高频词时,扫描的块更少,减少IO放大。2. 根据(被搜索元素的次数*命中条数)的值进行排序,按排在最前的元素进行聚集,逐级聚集。
(以上方法可能比较烧脑,下次发一篇文档专门讲GIN的数据重组优化)
《索引扫描优化之 - GIN数据重组优化(按元素聚合) 想象在玩多阶魔方》
4、gist数据分布优化
如果是普通类型,则线性相关越好,扫描或返回多条数据的效率越高。
如果是空间类型,则元素越集中(例如数据按geohash连续分布),效率越高。
5、brin数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
6、多列复合索引数据分布优化
对于多列符合索引,则看索引的类型,要求与前面一样。
增加一个,多个列的线性相关性越好,性能越好。
多列线性相关性计算方法如下
《PostgreSQL 计算 任意类型 字段之间的线性相关性》
数据分布还有一个好处,对于列存储,可以大幅提升压缩比
《一个简单算法可以帮助物联网,金融 用户 节约98%的数据存储成本 (PostgreSQL,Greenplum帮你做到)》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号