

redis 为什么这么快
前言
Redis 是一个开源的内存数据结构存储,广泛用于缓存、消息队列和实时数据处理等场景。Redis 之所以能够实现高性能和低延迟,主要归功于其设计和实现中的一些关键技术和优化策略。
Redis以性能著称,很快,到底有多快呢,我们来看一下官网提供的数据:
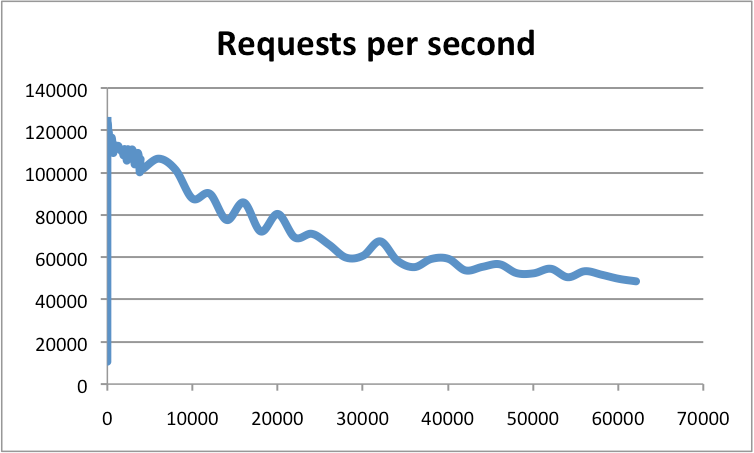
QPS可以达到100000,是什么原因让Redis这么快?主要有以下四点:
- Redis是基于内存的数据库
- IO多路复用
- 高效的数据结构
- 单线程模型
基于内存
Redis是基于内存的数据库,这样就减少了不必要的磁盘IO操作,大大提升了读写速度,下图是各种介质的处理时间
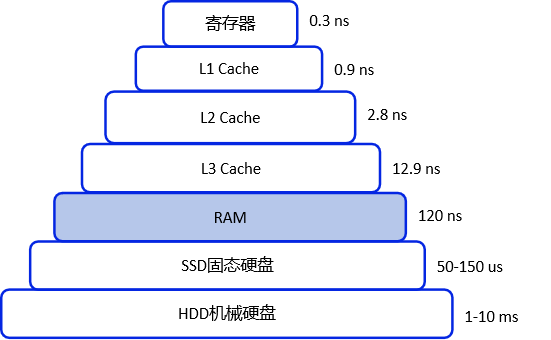
由上图可见,内存的存取时间大约为120纳秒,而硬盘的存取时间最快也要50微秒,换算下来,内存的速度至少是硬盘的400多倍。注:1ms=1000us,1us=1000ns,ms表示毫秒,us表示微秒,ns为纳秒。
IO多路复用
在Linux系统中有五种IO模型:阻塞IO,非阻塞IO,IO复用,信号驱动IO和异步IO。Linux内核使用文件描述符(File Descriptor, FD)来标识一个文件或者其他的IO资源(比如网络套接字),这些IO模型都使用FD来读写文件。
而IO多路复用中的“多路”是指多个网络连接,“复用”是共用同一个线程。它在单个线程中监听多个IO事件的状态变化,一旦IO就绪就进行处理。当多个socket客户端与服务端连接时,Redis的IO多路复用程序将对应的FD注册到队列中,而文件事件派发器监听该队列,它根据不同的事件选择不同的处理器。
高效数据结构
Redis采用高效的数据结构来提升性能,比如动态字符串、压缩列表、跳跃表等。
动态字符串:
动态字符串(SDS,Simple Dynamic String)是Redis存储字符串的底层实现,它可以动态调整大小,高效的进行字符串的追加、删除等操作
SDS本身包含了长度信息,能够以O(1)的复杂度获取字符串的长度信息。另外,SDS的空间分配策略和惰性空间释放策略,让字符串的操作更加高效。当然,SDS需要额外的空间存储这样的信息,导致它占用的内存较大。
struct sdshdr {
long len;
long free;
char buf[];
};buf是保存实际数据的字节数组,而len为buf的实际长度,free表示额外的可用字节大小。压缩列表:压缩列表(ziplist)是一种紧凑型的数据结构,它比较适合用来存储一些较小的元素,比如字符串、整数或者浮点数等。压缩列表由一系列的条目组成,每个条目表示一个元素,它包括以下几个部分:
Prevlen:前一个条目的长度
Entrylen:当前条目的长度
Content:元素的实际内容列表中的这些元素都是连续的,这意味着不需要额外的元数据或者指针来记录元素间的关系。与其它的数据结构相比,比如双向链表,压缩列表减少了额外的内存开支。同时,这些元素是连接存放的,所以按序号访问时,用时都是常数时间。另外,Redis会自动在压缩列表和其他数据结构之间进行切换,比如双向链表,哈希表等。切换的标准与元素的大小和个数有关。跳表:
跳表(skiplist)是一种有序的数据结构,能够进行快速查找。通过层级的链表结构,实现了元素的快速操作,包括插入、删除等。
跳表在多个层级上建立索引,可以在O(logN)的时间内完成查找。通过跳跃这些元素的上层指针,可以跳过很多元素,从而实现快速的查找、插入和删除操作。
Redis还支持三大扩展数据类型:位图Bitmaps、基数统计HyperLogLog、地理位置GEO、Streams等。
单线程
Redis是一款内存数据库,绝大部分的操作都是在内存中进行的,所以它的性能瓶颈主要是内存操作和网络通信,而不是CPU。在这样的场景下,多线程就未必比单线程要快,因为CPU在一个时间片里只能执行一个线程,线程切换的时候就需要保存当前线程的上下文,包括一些额外的线程调度、同步等操作,这样就会降低Redis性能。
Redis不是CPU密集型的系统,单个线程足以满足计算要求,这样就避免了多线程带来的性能损耗,同时也让操作更加稳定。
Redis 使用单线程来处理客户端的请求,这是因为:
- 避免锁竞争:多线程编程中常见的锁竞争问题会导致性能下降。使用单线程可以避免这一问题,从而提供更高的性能和一致性。
- 简化编程:单线程模型使得代码更简单,没有复杂的线程同步问题,更容易维护和调试。
Redis 的单线程模型是指其主要的网络 I/O 和命令执行部分是由一个单线程来处理的。但这并不意味着 Redis 完全依赖单线程来处理所有的操作。实际上,Redis 利用了多种优化技术和机制来确保高效的性能。
Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
多线程的使用
虽然 Redis 的核心操作是单线程的,但它在某些场景下也利用了多线程来优化性能。例如:
- 异步 I/O 操作:
- Redis 使用非阻塞 I/O 多路复用技术(如 epoll、kqueue 等)来处理网络连接和 I/O 操作。这使得即使单线程也能够高效地处理大量并发连接。
- 持久化操作:
- Redis 提供了 RDB(快照)和 AOF(追加文件)两种持久化机制。在执行这些持久化操作时,Redis 会通过后台子进程或线程来处理,以避免阻塞主线程。
- 例如,RDB 快照的生成是在一个子进程中进行的,而 AOF 重写则可以在后台线程中进行。
- 模块扩展:
- Redis 4.0 引入了模块系统,允许开发者编写自定义的 Redis 扩展。模块可以使用多线程来实现一些复杂的计算或 I/O 操作,而不会阻塞 Redis 的主线程。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-08-08 js 解析 JSON 数据
2019-08-08 Mysql按日、周、月进行分组统计
2019-08-08 linux中yum与rpm区别
2019-08-08 linux查看 LAMP环境安装路径