
SQL调优之十:访问路径(Access Path)五
Table Cluster Access Paths
表的聚簇是将一组表的相同列的数据存储在同一个数据块中的操作,聚簇表就是以这种方式存储的表的组合。
当表被聚簇的时候,单个数据块可以存储来自不同表的数据。
一,Cluster Scans
一个聚簇索引是一个聚簇表用来定位数据的索引。
它是以B树索引的方式对聚簇键进行索引。
聚簇扫描(Cluster Scans)就是从索引化的聚簇表中获取聚簇键的值相同的所有数据的扫描方式。
优化器什么时候会考虑使用Cluster Scans?
当需要访问一个索引化的聚簇表的时候。
Cluster Scans的工作机制
在一个索引化聚簇中,数据库把有相同聚簇键值的所有行存储在同一个数据块中。
比如说,如果把hr.employee2和hr.department2两个表聚簇为emp_dept_cluster,聚簇键是department_id列,然后数据库把department为10的所有employee存储在同一个数据块中,20的所有employee存储在另一个数据块中,以此类推。
B树聚簇索引会把聚簇键值和数据库数据块地址(DBA,database block address)关联起来。比如说:
30,AADAAAA9d
当一个用户请求聚簇里面的数据的时候,数据库会扫描索引来获取包含数据的数据块的DBA,然后再基于DBA来定位相关的行。
例子:
创建聚簇:
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4)) SIZE 512;
在聚簇上创建索引:
CREATE INDEX idx_emp_dept_cluster
ON CLUSTER employees_departments_cluster;
往聚簇中添加表:
CREATE TABLE employees2
CLUSTER employees_departments_cluster (department_id)
AS SELECT * FROM employees;
CREATE TABLE departments2
CLUSTER employees_departments_cluster (department_id)
AS SELECT * FROM departments;
然后查询以下语句:
SELECT *
FROM employees2
WHERE department_id = 30;
执行计划如下,先通过第二步进行索引扫描获取rowid,然后再通过第一步使用rowid进行聚簇扫描。
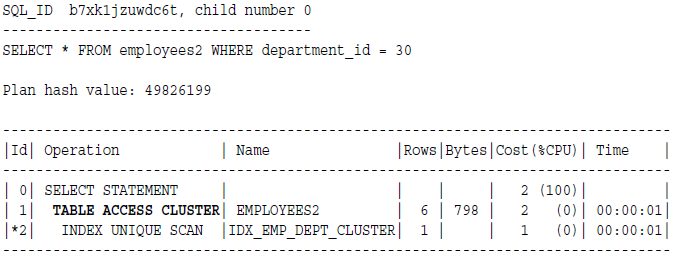
二,Hash Scans
一个哈希聚簇跟索引聚簇类似,除了用hash函数取代了索引,没有额外的单独索引存在。
优化器什么时候会考虑使用Hash Scans?
当数据库要访问一个哈希聚簇里面的表的时候。
Hash Scans的工作机制
在一个哈希聚簇中,拥有同一个哈希值的所有数据会存储在同一个数据块中。
在进行哈希扫描的时候,数据库首先会对语句中指定的聚簇键值应用哈希函数来获取一个哈希值,然后再去扫描那些包含了这个哈希值的数据块。
例子:
创建哈希聚簇:
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4)) SIZE 8192 HASHKEYS 100;
创建哈希聚簇中的表:
CREATE TABLE employees2
CLUSTER employees_departments_cluster (department_id)
AS SELECT * FROM employees;
CREATE TABLE departments2
CLUSTER employees_departments_cluster (department_id)
AS SELECT * FROM departments;
运行查询语句:
SELECT *
FROM employees2
WHERE department_id = 30;
执行计划如下,数据库对30应用哈希函数,获取哈希值,然后在第一步会用这个哈希值来扫描数据块来获取数据。
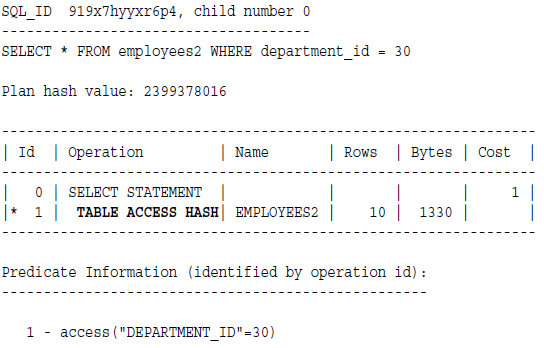

 浙公网安备 33010602011771号
浙公网安备 33010602011771号