
SQL调优之十:访问路径(Access Path)三
一,Index Unique Scans
索引唯一扫描最多只会返回一行数据。
优化器什么时候会考虑使用索引唯一扫描?
索引唯一扫描要求是等式查询。数据库只有在满足以下两个条件的时候才会使用索引唯一扫描:
- 查询谓词包含了唯一索引的所有列,使用等式条件,比如WHERE prod_id=10
- SQL语句包含了一个列的等式条件,该列上有唯一索引
需要注意的是,仅仅靠唯一约束或者主键约束是不会导致索引唯一扫描的,因为它们没有创建唯一索引。
例子:
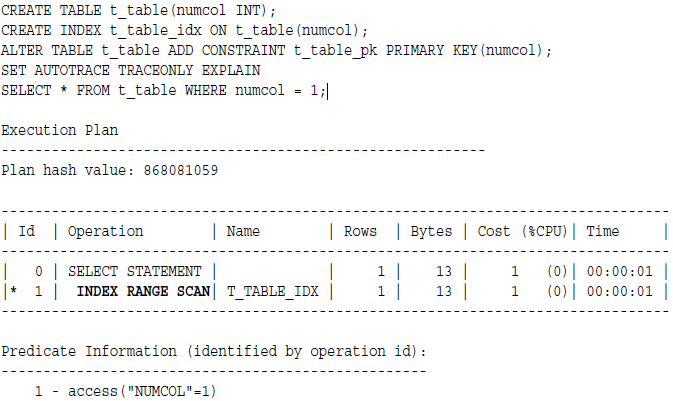
你可以使用INDEX(alias index_name)来指定使用哪个索引,但没办法指定访问路径,即指定使用唯一扫描。
索引唯一扫描的工作机制
唯一扫描在找到一条记录之后就会立马停止,因为不会有第二条记录。
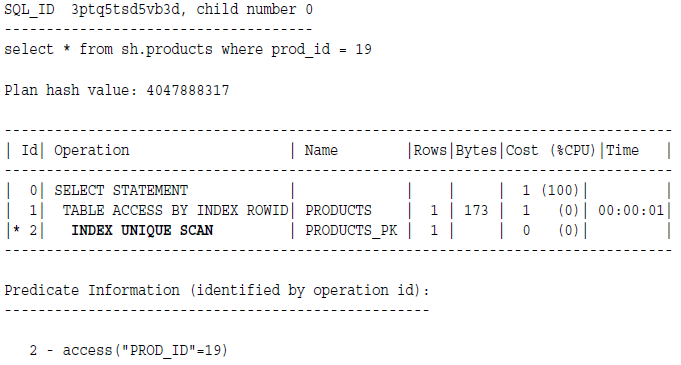
下图是获取prod_id=9的记录的图解:

例子:唯一索引,PRODUCTS_PK,第二步,access by PROD_ID=19
二,Index Range Scans
索引范围扫描是对数值的按序扫描。
范围扫描可以从任意位置开始,对于选择性的查询,数据库可能会选择这种方式。
默认的,索引的存储顺序是升序的,然后以同样的顺序扫描他们。
比如说对department_id>=20这种查询,范围扫描和返回的顺序是20,30,40这样子。
如果有多个相同的值,那么数据库则会按rowid的升序来扫描和返回。
对于索引降序范围扫描,它跟范围扫描一样,除了返回数据的顺序是降序之外。
一般来说,当你以降序排列数据的时候,并且查找低于某个值的数据的时候,数据库就会选择降序范围扫描。
优化器什么时候会考虑使用索引范围扫描?
索引的一个或多个前缘列出现在条件里面。
- 这个条件可以是一个或多个表达式,逻辑操作和返回trure,false,unknow的结合。比如说:
department_id = :id
department_id < :id
department_id > :id
department_id > :low AND department_id < :hi
注意:通配符查询像col like '%ASD'不能出现在前缘位置
- 索引键有可能是0,1或者多个值
Tips:如果你使用order by对数据进行排序,但是没有依赖于任何索引。这个时候,如果有某个索引刚好符合你的排序需求,那么优化器就会使用这个选项来避免排序。
当你的语句使用了order by desc的时候,优化器会考虑使用index range scan descending。
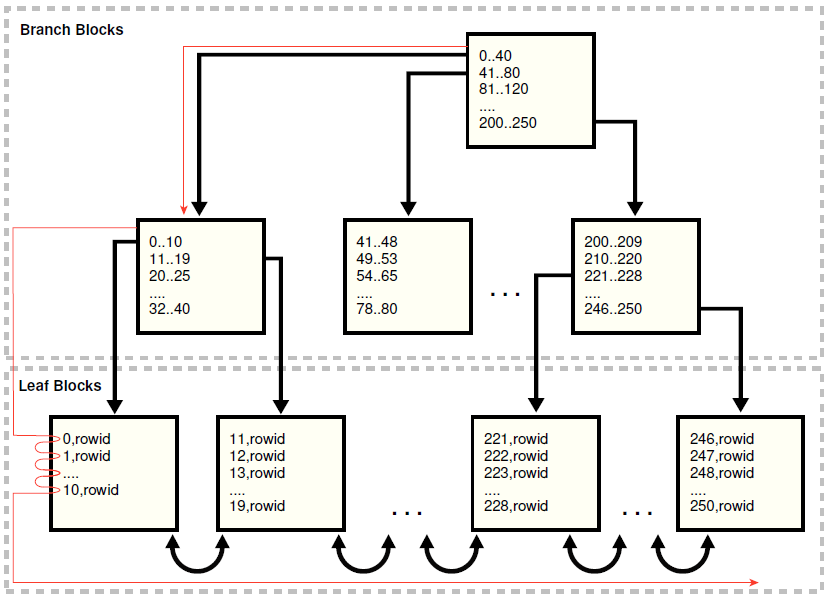
索引范围扫描的工作机制
在一次索引范围扫描里面,数据库从根节点读到枝干节点:
1,读根节点数据块
2,读枝干节点数据块
3,执行以下两步,直到所有数据被返回:
a. 读叶子节点数据块来获取rowid
b. 读表数据块来获取行数据
注意:在某些情况下,一次索引范围扫描会读取一批索引数据块,对rowid进行排序,然后读取一批表数据块。
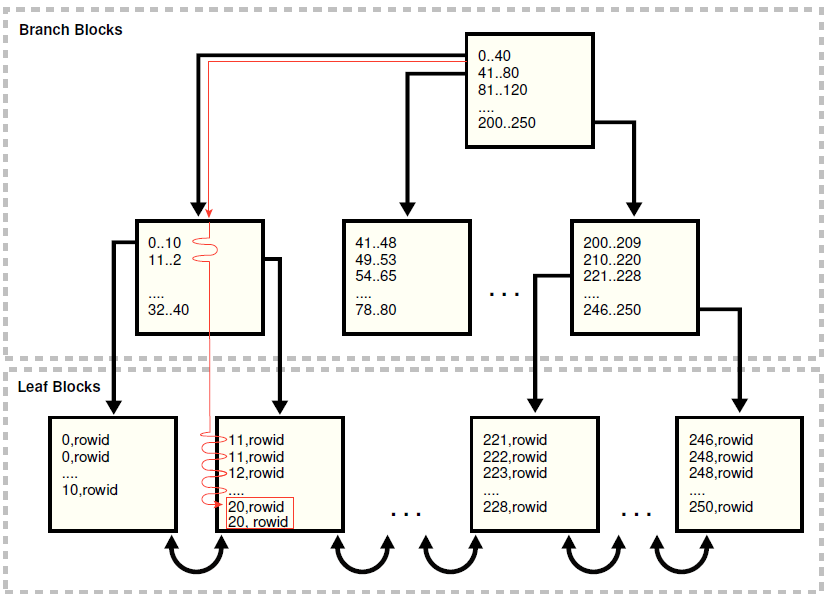
在扫描索引的时候,数据库会从叶子块往前或后扫描。比如说,扫描20-40之前的数据,数据库会先定位到最低值20或者比20更高(没有20的情况下),然后从链接列表里面水平扫描,直到找到比40大的数据,然后停下来。
例子:
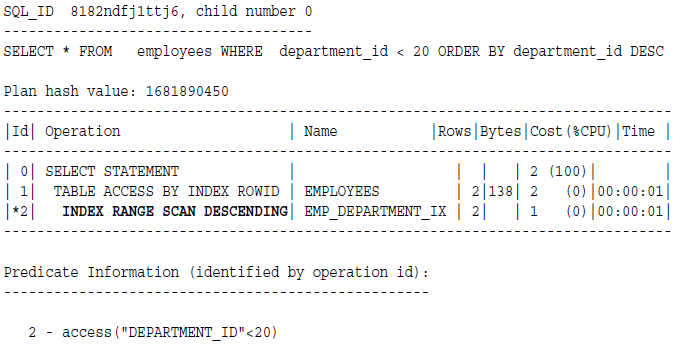
下图是查找department_id=20的记录,因为不是唯一索引,所以会做范围扫描。
索引范围扫描升序例子:
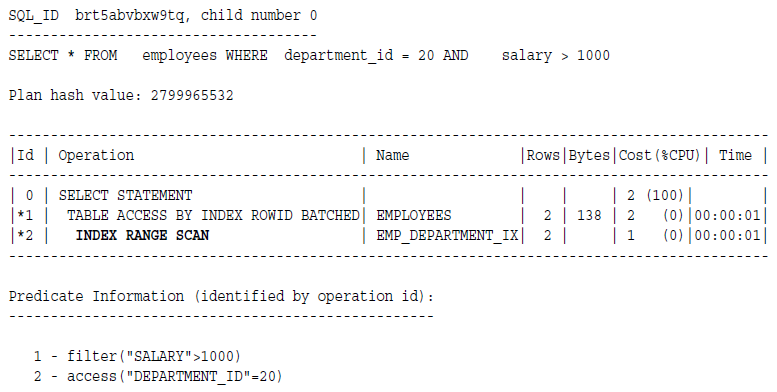
索引范围扫描降序例子:
数据库是先查找到最高值,然后往左边扫描
三,Index Full Scans
索引全扫描会按顺序读取整个索引。这种访问方式可以避免单独的排序操作。
优化器什么时候会考虑使用索引全扫描?
- 索引列在谓词条件里面,但这个列不能是前缘列
- 没有指定谓词条件,但满足以下所有条件:
——查询里面涉及的所有列都在索引里面
——至少有一列是非空的
- 一个查询里对被索引了的非空列有order by操作
索引全扫描的工作机制
数据库会先读根节点数据块,然后从索引的最左边一直往下,直到找到第一个叶节点数据块,如果是降序查询的话,则是最右边。
然后数据库会按顺序扫描到索引的底部,每一次读一个数据块。也就是说,数据库使用单块读而不是多块读。
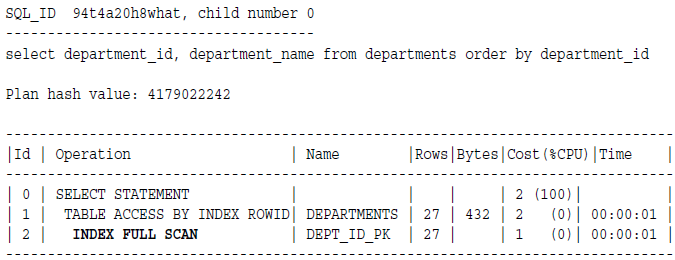
例子:
这个例子里面,如果没有order by,其实全表扫描的成本要更低,只不过有个排序需求,使用索引能够避免排序操作。毕竟排序的成本很高。
另外,因为返回的包含了两个列,一个不在索引里面,所以数据库先获取所有的rowid,然后再access by index rowid来获取行数据。
四,Index Fast Full Scans
索引快速全扫描会不按排列的顺序来读取索引,因为它们在磁盘上。这种方式不会使用索引来探查表,但是会把索引本身当成表来读。
优化器什么时候会考虑使用索引快速全扫描?
只有当仅仅访问索引的属性的时候,优化器才会考虑使用这个方式。
要注意的是,和索引全扫描不一样的是,快速全扫描不能够消除排序操作,因为它的读取本身就是无序的。
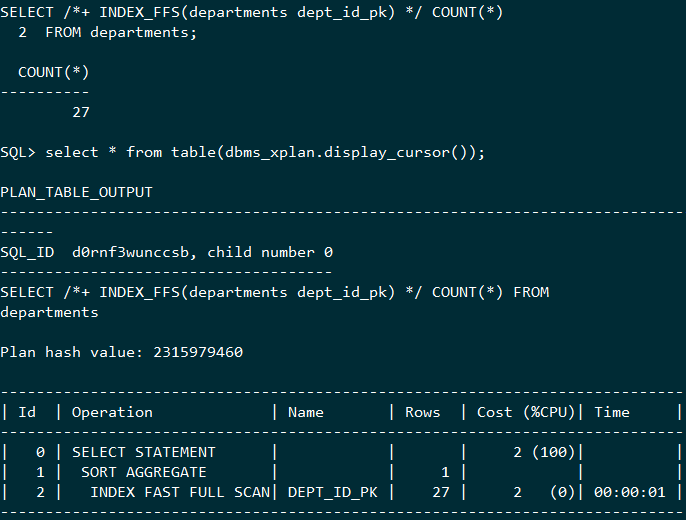
可以使用hint:INDEX_FFS(table_name index_name)来强制使用快速全扫描。
索引快速全扫描的工作机制
数据库使用多块读的方式来读取整个索引,它会忽略掉根块和枝干块来读取叶子块的所有记录。
例子:
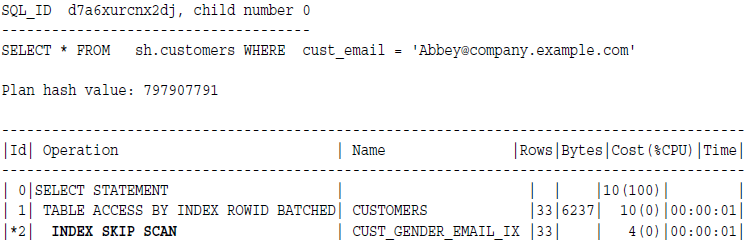
五,Index Skip Scans
当复合索引的前缘列,比如说index(a,b),a列被跳过了,或者说查询里面没有指定a列的时候,就会发生索引跳跃扫描。
优化器什么时候会考虑使用索引跳跃扫描?
通常来说,跳跃扫描索引要比扫描表数据块以及索引全扫描要快。
优化器会在以下两种情况的时候考虑跳跃扫描:
- 复合索引的前缘列没有出现在查询谓词里面
- 复合索引的前缘列里只有少数非重复值,但是在后置列里面有大量的非重复值,比如说index(a,b),a列只有2个非重复值,但是b列有上千个
索引跳跃扫描的工作机制
索引跳跃扫描可以从逻辑上将一个符合索引分裂成多个更小的子索引。
前缘列的非重复值的数量决定了有多少个子索引,数量越少,效率越高。
例子:
六,Index Join Scans
索引连接扫描是多个索引共同返回查询的所有列的哈希连接。
数据库不需要访问表,因为所有的数据都包含在了索引里面。
优化器什么时候会考虑使用索引连接扫描?
- 多个索引的哈希连接能够满足查询需要返回的所有列,不需要访问表
- 从表中读取数据的成本高于单单从索引读取数据的成本的时候。比如说,扫描两个索引然后把它们连接起来的成本,一般要低于扫描一个高选择性的索引,然后再去驱动表
可以通过INDEX_JOIN(table_name)来指定索引连接
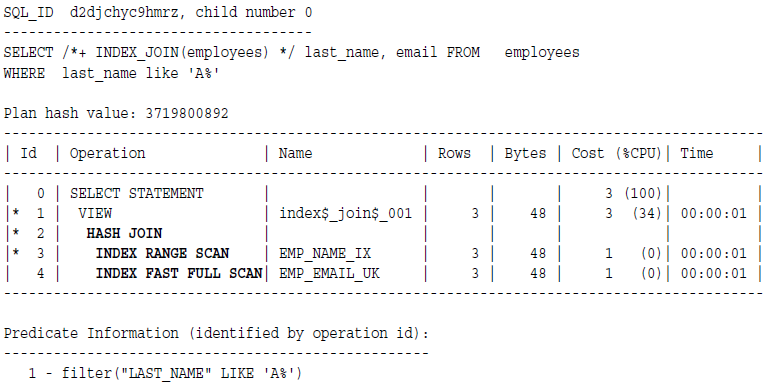
索引扫描连接的工作机制
索引扫描连接涉及了多个索引的扫描,然后对这些rowid进行哈希连接来返回行数据。
1,扫描第一个索引获取rowid
2,扫描第二个索引索取rowid
3,对rowid进行哈希连接,返回行
例子:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号