
SQL调优之十:访问路径(Access Path)二
一,Direct Path Reads
直接路径读,这种情况下,数据库会绕过SGA,从磁盘把缓存读进PGA。
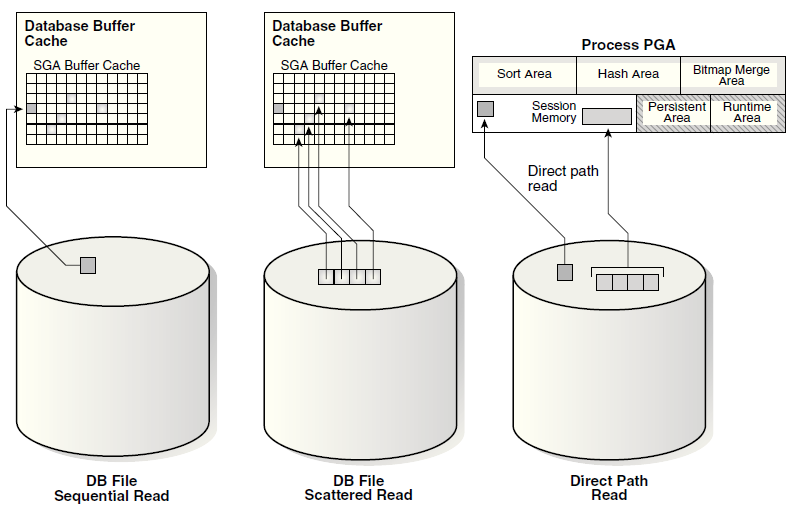
下面的图显示了scattered和sequential读的不同之处,包括从SGA读缓存以及直接路径读。
可以看到:
scattered read是多块读入SGA
sequential read是单块读入SGA
Direct Path Read包含了单块和多块读,读入PGA,Session Memory中
在以下几种情况,数据库可能会使用直接路径读:
- CREATE TABLE AS SELECT语句
- ALTER REBUILD或者ALTER MOVE语句
- 从临时表空间读取数据
- 并行查询
- 从LOB段读取数据
二,Full Table Scans
全表扫描,顾名思义会读取表里的所有行,然后再给其他步骤过滤掉不符合条件的结果。
优化器什么时候会考虑使用全表扫描?
一是优化器没办法使用一个不同的访问路径,比如说索引失效;
二是其他访问路径成本过高。
| Reason | Explanation |
| 没有索引 | 如果没有索引的话,优化器只能选择全表扫描 |
| 查询谓词里对索引列使用了函数 | 除非索引本身是基于函数的索引,否则数据库不会使用该索引。 因为数据库是对索引列的值进行索引,而不是对应用了函数的值进行索引。 一个典型的应用错误就是,对一个数据类型为字符的列进行索引,比如说char_col列, 结果在查询的时候,使用的语句是char_col=1。 这种情况下,数据库会在这个谓词上隐式应用to_number函数,也就是会变成 to_number(char_col)=1。这种情况下,数据库不会使用原本的字符类型索引。 |
| 运行select count(*)语句, 有索引,但是索引列包含 null值 |
优化器在这种情况下无法使用索引,因为索引不会去索引null值。 |
| 查询谓词没有使用B树索引的前缘列 | 比如说,一个对employee(first_name,last_name)进行索引的索引。 如果一条SQL的谓词条件是WHERE last_name='KING',那么优化器可能不会使用该索引, 因为first_name不在谓词条件里面。 但是,这种情况下,优化器可能会选择index skip scan |
| 查询本身的选择性很差 | 如果优化器认为这次查询需要读取表里面的大多数数据块,那么即便索引是有效的,它也会 选择使用全表扫描。全表扫描会使用大的I/O请求。 使用比较大的I/O请求要优于很多次的小I/O请求。 |
| 统计信息过旧 | 比如一个小表增长成大表,统计信息错误的以为它还是小表,这种情况下,优化器可能觉得 索引的效率没有全表扫描的效率高。 |
| 表很小 | 如果一个表在高水位以下的数据块少于DB_FILE_MULTIBLOCK_READ_COUNT参数设置 的值n,那么一次全表扫描的成本可能会比索引范围扫描还要低。 扫描的成本可能会比读取其中的碎片或者索引更低。 |
| 表设置高并行 | 一个高并行的表会使优化器倾向于使用全表扫描而不是范围扫描。表的并行度可以查询 ALL_TABLES.DEGREE列 |
| 使用了hint来指定使用全表扫描 | FULL(表别名) |
全表扫描的工作机制
在一次全表扫描里,数据库会顺序读取高水位以下的每一个格式化了的数据块。每个数据块只读一次。
下图显示了数据库是怎么扫描的,以及怎么跳过非格式化的数据块的:
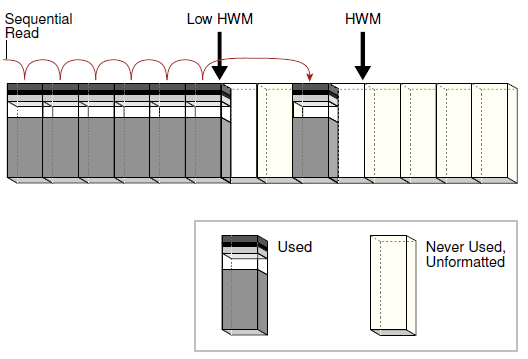
因为数据块是相连的,因此数据库可以使用更大的I/O请求来替代单块读来加快扫描速度,也就是多块读。
一次读多少个数据块是由参数DB_FILE_MULTIBLOCK_READ_COUNT控制。比如说,但这个参数值为4的时候,单次读请求里面,数据库就会去读4个数据块。
全表扫描对数据块进行缓存的算法很复杂,它会因为表的大小不同而不同。
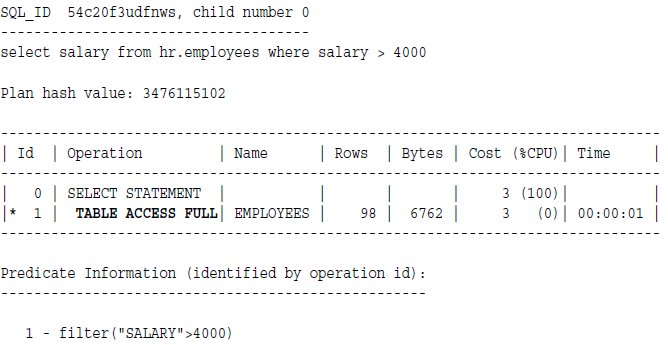
全表扫描例子,没有索引:
三,Table Access By Rowid
rowid是数据存储位置的内部体现。它代表了行在哪个数据文件的哪个数据块,以及该行在数据块里面的位置。
使用rowid来定位某一行的位置是获取单行数据最快速的方式。
优化器什么时候会考虑使用rowid来访问表?
在大多数情况下,数据库会在使用索引扫描后使用rowid来访问表。
但是,并不是每一次索引扫描后都需要接着使用rowid来访问表。
如果索引包含了所有需要的列,那么通过rowid来访问表可能不会发生(Index Fast Full Scan)。
通过rowid访问表的工作机制
1,获取rowid,可能是where条件,或者是从索引扫描返回的结果
2,基于rowid来定位数据
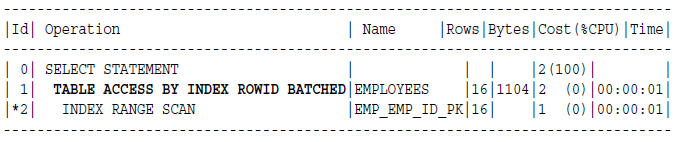
例子:
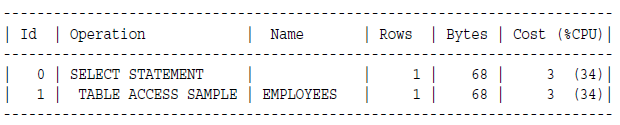
四,Sample Table Scans
表取样扫描会从数据集中获取随机的采样数据。
优化器什么时候会考虑使用表取样扫描?
当from后面跟了SAMPLE关键字的时候数据库就会使用采样扫描:
1,SAMEPLE(sample percent)
数据库从表读取指定的百分比的行数
2,SAMPLE(sample block)
数据库读取指定的百分比的表数据块
取值范围从.000001到100(不包括100),实际执行只是大概值,不是准确值。
数据块采样只有在全表扫描或者索引快速全扫描的时候才能使用。如果存在一个更高效的执行计划的话,数据库是不会采取数据块采样的。
如果要确保使用数据块采样,则需要加hint来指定使用全扫或索引快速全扫。
例子:
SELECT * FROM hr.employees SAMPLE BLOCK (1);
五,In-Memory Table Scans
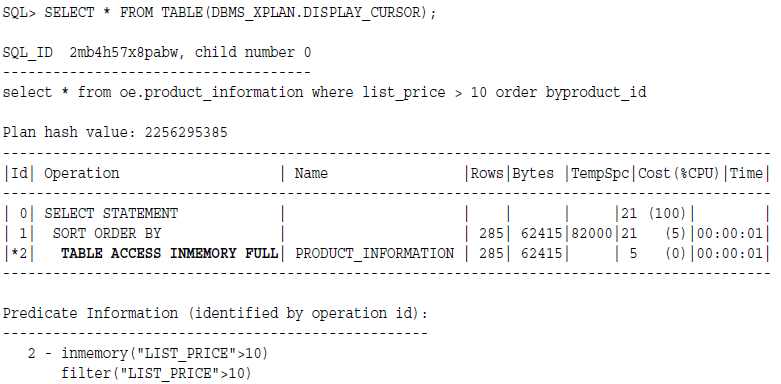
从Oracle 12c(12.1.0.2)开始,In-Memory scan会从In-Memory Column Store(内存列式存储)那里获取数据。
IM column store是在SGA区域中以特殊的列式方式存储表或者分区的副本,用以快速扫描使用。它和普通的缓存不冲突,可以作为补充并存。
优化器什么时候会考虑使用内存表扫描?
初始化参数影响In-Memory特性:
1,INMEMORY_QUERY
该参数可以在会话层面或者系统层面启用或者禁用in-memory查询。这个参数在测试内存列式存储的负载和性能的时候很有用。
2,OPTIMIZER_INMEMORY_AWARE
配置这个参数可以选择优化器在计算成本的时候是不是考虑in-memory对性能的提升。
3,OPTIMIZER_FEATURE_ENABLE
当把这个值设成低于12.1.0.2的版本的时候,就相当于把OPTIMIZER_INMEMORY_AWARE设置成false。
启用或者禁用in-memory查询也可以通过添加hint:INMEMORY或者NO_INMEMORY,这种方式和设置INMEMORY_QUERY参数是等同的。
假如在使用INMEMORY提示来指定使用内存表查询的时候,该对象还没有加载在内存列式存储里面的话,数据库不会等待加载该对象。
但是,在访问该对象的同时就会触发加载该对象的操作。
例子:
SELECT *
FROM oe.product_information
WHERE list_price > 10
ORDER BY product_id;
六,B-Tree Index Access Paths
索引是一个和表/表聚簇相关的可选结构,在获取表里随机分布的行的时候,索引一般情况下可以减少磁盘I/O。
B树索引是Oracle数据库里面最常见的索引类型,它会对值进行排列,并且按照范围进行划分。
因此,对于范围扫描,以及准确匹配的查询,B树索引能够提供很好的性能。
B树索引的结构
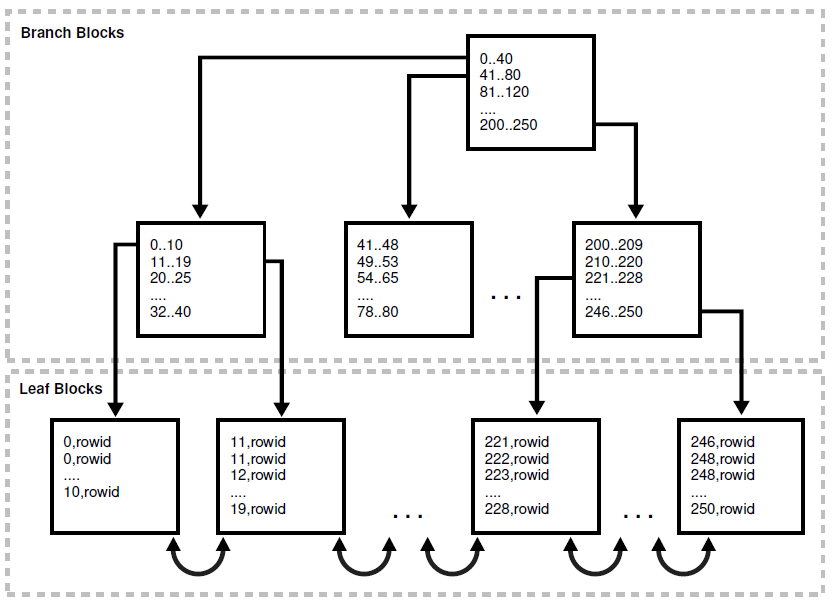
一个B树索引有两种类型的数据块:用于搜索的枝干块和用于存储数值的叶子块。
枝干块包含了能够分辨叶子块存储值的最短前缀,叶子块则包含了索引的数值以及指向行实际位置的rowid。
每个索引记录都是按(键值,rowid)排序。
索引的存储是怎么影响索引扫描的
位图索引块可以出现在索引段的任何一个位置。
上图中显示叶子块和其他块是连续的。比如说,存储了键值0到10的叶子块排在了11到19的前面。但是这个显示的是索引记录的链接列表。
实际上,索引段里面的索引数据块不需要按顺序存储。也就是说246到250的数据块在存储上可能排在了0到10的索引块的前面。
这就引出了一个结果,排序了的索引扫描必须或者说只能是单块I/O,因为数据库必须读上一个索引块之后,才能知道接着读哪个索引块。
索引块的主体部分会以堆的形式存放记录,跟表存放行数据是一样的。
比如说,如果值10最先插入到表里面,那么10的索引记录就会插入到索引数据块的底部。接着数值0被插入表中,那么在索引里面,0的索引记录会放在10的索引记录上面,依此类推,一个接着一个往上堆。
因此,在索引块内部,数据并不是排序的。但是,行头里的记录则是按序排列的,比如说第一个记录会指向键值0,最后的记录指向键值10。
所以索引扫描的过程中可以从行头判断从哪个记录开始读,以及读到哪里结束,能够避免读所有的记录。
唯一和非唯一索引
在非唯一索引里,数据库把rowid作为一个额外的列附加到键值后面。每一条记录会增加一个长度比特来让键值唯一,然后数据库会按键值排序,再按rowid排序。
比如说:
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
在唯一索引里,键值不会包含rowid。数据库直接按键值排序。
B树索引和空值
B树索引不会存储空值,这个特性也会影响优化器对访问路径的选择。
但是,如果是复合索引,只要不是所有列都是空值,B树索引就还会存储该键值。
例子:
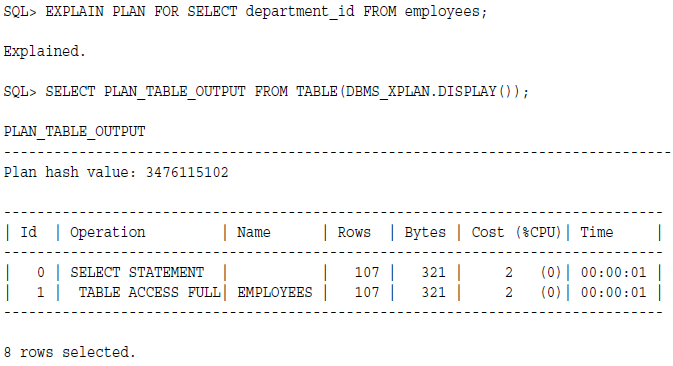
假设employee表在employy_id这一列有个主键,也就是唯一加非空,然后再department_id这一列有个唯一索引,也就是允许空值。
1,select department_id from employees;这个语句要返回所有的department_id,因为这一列有空值,所以走索引是不会返回所有值的,因此优化器只能走全表扫描。
2, select department_id from employees where department_id=10; 这个语句指定了过滤条件为10,也就是非空值,可以走索引。
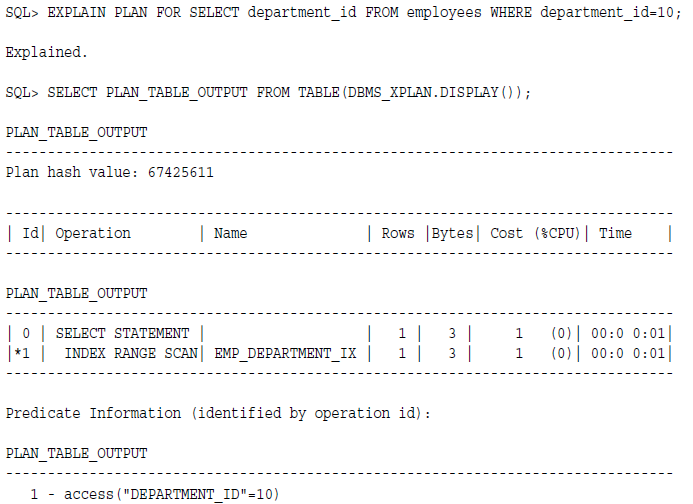
3,SELECT department_id FROM employees WHERE department_id IS NOT NULL; 返回所有非空值,所以直接全扫整个索引即可。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号