SQL调优之九:堆组织表,索引组织表以及表聚簇
说在最前头,一切快慢都是相对来说的
一,堆组织表(heap-organized table)
默认情况下,我们用Create table创建出来的表就是堆组织表,在往这种表里面插入/导入数据的时候不会按某种特殊排列方式的。
表中的每一行都有一个独一的ROWID,当行移动的时候ROWID也会跟着变化,即便是在同一个heap里面移动。
举例来说,你从汉语词典撕了几页出来,然后把它们堆到你面前的桌子上,这个时候你就得到一个堆"表"。
1,你不用进行排序,这就是堆表的无序
2,你拿到一张纸就往上扔,所以插入很快
3,你要改一张纸的页码,所以你要从这堆纸里面找到你要的那一张,因为无序,所以查找很慢
4,改完你又把它往前面一扔就好了,所以存入很快
5,你更改的纸的位置在”堆”里面变了,所以ROWID会随着位置改变
6,为了快点找到纸的位置,你要写一个目录,就跟词典的目录一样,这就是索引
7,索引写着纸的位置,你通过索引找数据的时候,就是先看索引确定位置“ROWID”,然后再去表里找数据
8,你要找到其中的几页纸,因为位置随机,所以通过全表扫描获取到的数据的先后顺序也是随机的
总结:随机I/O,插入快,查找慢,这也就是为什么我们平时建议要走索引的原因(一般情况)
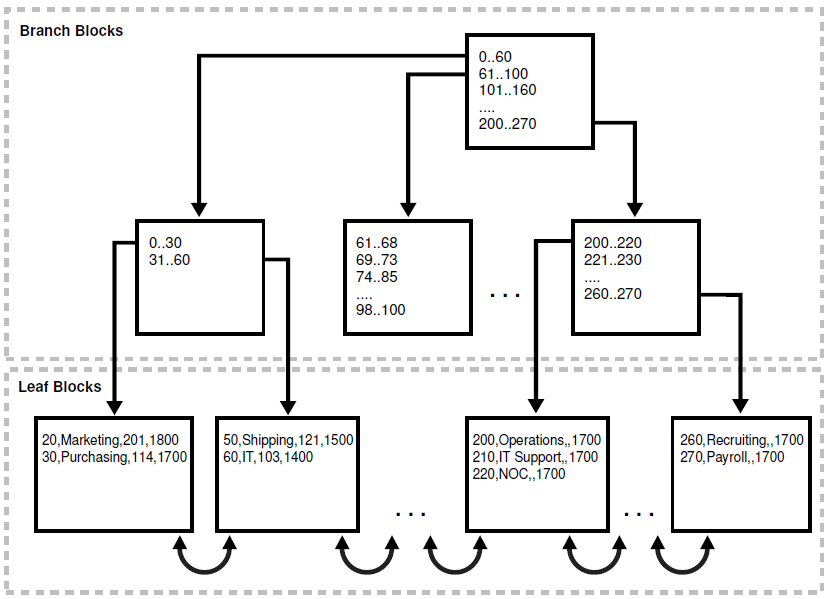
二,索引组织表 Index Organized Tables (IOT)
索引组织表是以类似于B树索引结构存储的一种表结构。
1,在索引组织表中,行数据是和主键索引存放在一起的。因此该表适用于经常检索主键的情况
2,每一个B数索引里面的记录含有其他非索引列的数据,因此可以减少存储,同时也可以减少I/O
3,对索引组织表做DML操作的时候,等同于对索引做操作,它在插入的过程需要进行定位,找到指定的叶块,然后再插入数据,某些极端情况下,它可能还要进行分块,分枝干的操作,所以DML操作相对于堆表来说要慢,不适合用于频繁更新的表
4,索引组织表适用于文献检索,空间数据以及OLAP应用:
- 不常更新
- 主要对主键查询
- 适合使用索引扫描的查询,既选择性好的范围扫描,唯一扫描
- 特定的数据结构需求,排序
创建语法:
CREATE TABLE locations
(id NUMBER(10) NOT NULL,
description VARCHAR2(50) NOT NULL,
map BLOB,
CONSTRAINT pk_locations PRIMARY KEY (id)
)
ORGANIZATION INDEX
TABLESPACE iot_tablespace
PCTTHRESHOLD 20
INCLUDING description
OVERFLOW TABLESPACE overflow_tablespace;
Row Overflow Area:
因为IOT表的索引和数据同时存在,所以有时候行数据可能出现溢出的情况,也就是太大了的情况,这个时候可以配置一个row overflow area。
如果指定了行溢出空间,数据库会把IOT表分为两部分:
- 索引条目:
这一部分包含了所有主键列的值,以及一个指向溢出部分(在另一个位置)的物理ROWID,以及一部分非主键列的值。这一部分存储在索引段上
- overflow部分:
这一部分则存储剩下的非主键列的值,存储在创建表时指定的溢出空间:OVERFLOW TABLESPACE overflow_tablespace;
碎片化处理:
对于IOT表变得碎片化的情况,可以用以下命令移动表:
没有启用overflow:
ALTER TABLE table_name MOVE INITRANS 10;
ALTER TABLE table_name MOVE ONLINE INITRANS 10;
启用了overflow:
ALTER TABLE table_name MOVE TABLESPACE iot_tablespace OVERFLOW TABLESPACE overflow_tablespace;
堆组织表和索引组织表的比较:
| 堆组织表 | 索引组织表 |
| rowid唯一识别行数据, 主键约束可以选择性创建或者不 |
主键唯一识别行数据, 主键约束必须创建 |
| ROWID列里的物理rowid允许创建第二个索引 | ROWID列里的逻辑rowid允许创建第二个索引 |
| 单独的行可以通过rowid直接访问 | 单独的行可以通过主键非直接访问 |
| 顺序全表扫描可以以某种顺序返回所有行 | 全索引扫描或者快速全索引扫描可以以某种顺序返回所有行 |
| 可以和其他表一起存在一个表聚簇里面 | 不可以 |
| 可以有一个LONG类型的列以及多个LOB数据类型的列 | 可以有LOB数据类型,但不能有LONG类型 |
| 可以包含虚拟列(仅有关系型堆组织表支持) | 不可以含有虚拟列 |
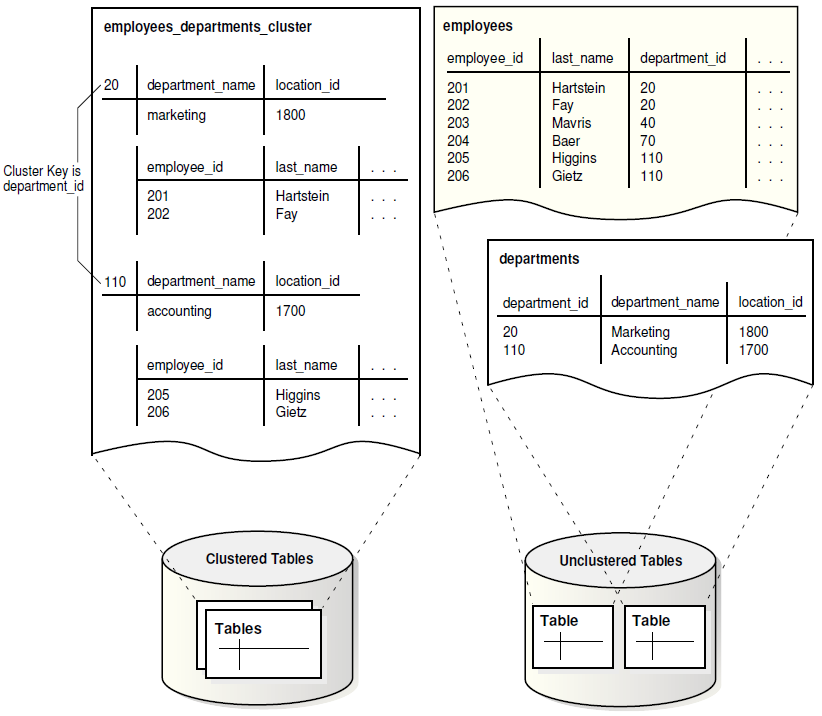
三,表集群/表聚簇 Table Cluster
一个表聚簇是指共享同一/一些列的几个表的组合,并且相关的数据会存储在相同的数据块里面。
即几个table,以相同的一个或多个列作为cluster key,来创建一个table cluster。
例子:
一个HR管理着两个书柜,
其中一个书柜上的盒子放着雇员的相关文件夹,--employee表
另一个书柜上的盒子则放着部门的相关文件夹,--department表
用户经常要找某个部门里面所有雇员的信息,--经常按某种关联关系来查询数据
为了能更容易拿到想要的数据,HR决定把所有的盒子放到一个书柜上。--创建Table Cluster
这一次是按部门编号来划分盒子,--Cluster Key, department_id列
比如,编号20的部门的所有相关文件,比如说雇员的相关信息以及部门本身的信息,都会被放到同一个盒子里面;编号100的部门的所有相关文件夹,则会放到另一个盒子。--相关数据会放到相同的数据块里面,并且department_id只存放一次
优点:
- 以Cluster Key作为连接条件的查询,磁盘I/O减少
- 获取数据的时间变快
- 使用空间变少,因为Cluster Key的值不会会单独每一行存放
不适合使用的情况:
- 频繁更新的表
- 经常需要做全表扫描的表
- 需要做truncate的表
索引化的聚簇
索引化的聚簇,是指在cluster key上的建立索引的聚簇,其必须在数据插入之前创建。
这种索引跟非聚簇的表上的索引是一样的,是单独管理的,同时也可以指定一个单独的表空间。
哈希聚簇
哈希聚簇跟索引聚簇是一样的,只不过索引键替换成了一个哈希函数。
这种情况下没有单独的索引,数据即索引。
关于聚簇可以看下这个链接做的实验:http://blog.itpub.net/17203031/viewspace-774405/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号