SQL调优之六:排序合并连接(Sort Merge Joins)
排序合并连接
排序合并连接是嵌套循环连接的变种。
如果两个数据集还没有排序,那么数据库会先对它们进行排序,这就是所谓的sort join操作。
对于数据集里的每一行,数据库会从上一次匹配到数据的位置开始探查第二个数据集,这一步就是Merge join操作。
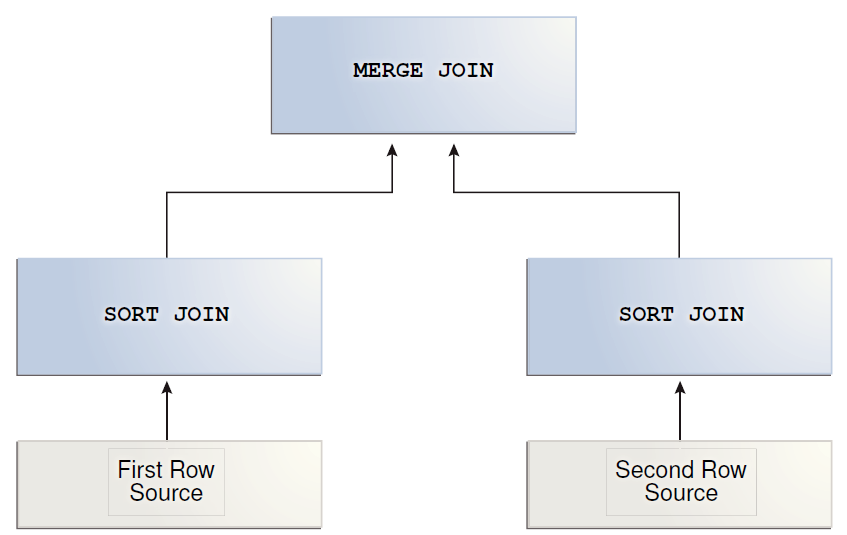
优化器什么时候会考虑使用排序合并连接?
哈希连接会要求构建一个哈希表,然后探查它。而排序合并连接则要求两个排序了的数据集。
在以下情况,优化器在连接大数据集的时候会考虑使用排序合并连接来替代哈希连接:
- 连接条件是不等式,比如:<,<=,>或者>=,相对应的,哈希连接要求是等式条件。
- 因为其他的一些操作要求排序,优化器会认为使用排序合并连接的成本更低。同时,如果有索引的话,那么第一个数据集就能够避免使用排序。但是,第二个数据集不论有没有索引,都会要求排序
相对于嵌套循环连接来说,排序合并连接和哈希连接有着同样的优点:直接在PGA里面拿数据,不需要在SGA里面反复加闩锁,然后再读取缓存,减少了不必要的I/O。
一般情况下,哈希连接的性能是要比排序合并好的,因为排序的成本很高。
但是,排序合并也有它的优点:
- 经过初始的排序后,合并过程是已经经过优化的了,在生成输出行的时候要更快
- 当哈希连接过程中的哈希表无法一次性完整构建在PGA里面的时候,排序合并的成本性能比要优于哈希连接。
当内存无法存放整个哈希表,然后必须把一部分数据拷贝到磁盘的时候。数据库可能需要多次从磁盘上读取数据。而在排序合并连接的过程中,如果内存无法容纳两个数据集,那么数据库会把它们都写到磁盘上,但每个数据集不会读取超过一次。
排序合并连接是怎么工作的?
类似于嵌套循环连接,排序合并连接一样要连接连个数据集,只不过会对它们进行排序。
对于第一个数据集里的每一行,数据库会在第二个数据集找到一个起始行,然后往下读,直到读不到匹配的行为止(这里会有些混淆,不要纠结,继续往下看)。
伪代码类似于:
READ data_set_1 SORT BY JOIN KEY TO temp_ds1
READ data_set_2 SORT BY JOIN KEY TO temp_ds2
READ ds1_row FROM temp_ds1
READ ds2_row FROM temp_ds2
WHILE NOT eof ON temp_ds1,temp_ds2
LOOP
IF ( temp_ds1.key = temp_ds2.key ) OUTPUT JOIN ds1_row,ds2_row
ELSIF ( temp_ds1.key <= temp_ds2.key ) READ ds1_row FROM temp_ds1
ELSIF ( temp_ds1.key => temp_ds2.key ) READ ds2_row FROM temp_ds2
END LOOP
例子1
普通排序合并连接,两个数据集为 temp_ds1和temp_ds2
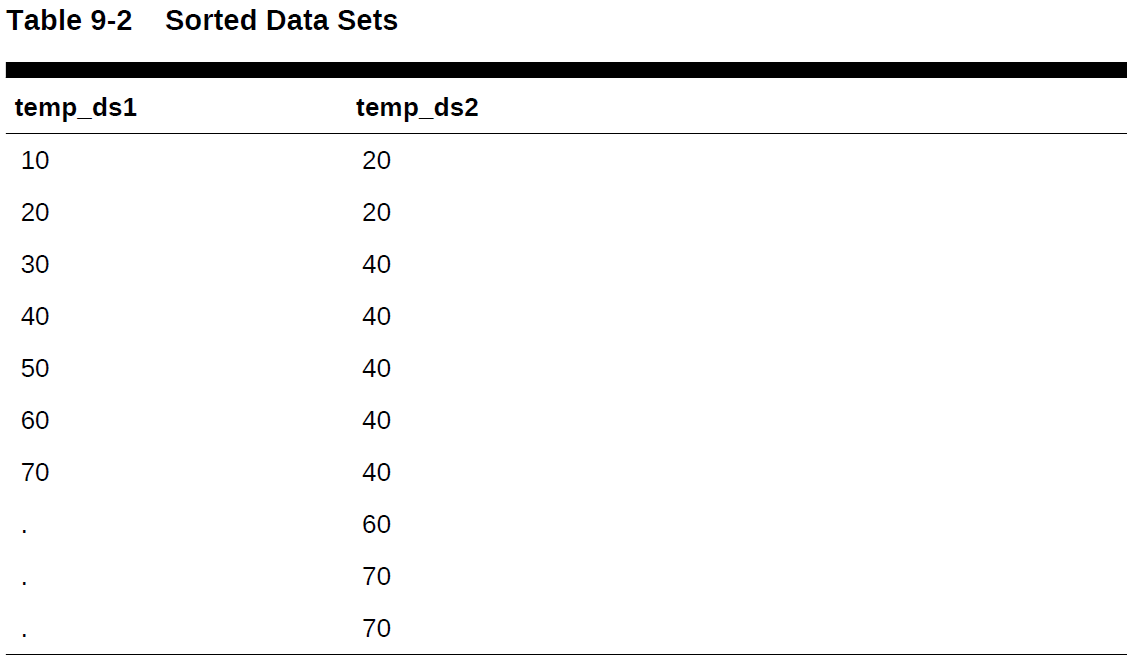
从上表来看,排序操作已经完成了,现在开始做匹配,数据库先读temp_ds1数据集的第一行10,然后去temp_ds2的表读第一行20,因为20比10大,而且数据是排序了的,证明temp_ds2后面的数据都比20大,所以已经没有必要再往下读数据了。
接下来,数据库开始读temp_ds1的下一行数据20,然后开始读temp_ds2的数据,第一行是20,匹配到了,继续读下一行,直到读到40这一行的时候,发现不匹配了,数据库就停下来了。
接着,数据库开始读temp_ds1的下一行数据30,这个时候它再去读temp_ds2,就不是从第一行开始读了,而是从上一次最后一个匹配的那一行开始,也就是最后一个20。然后再读到40的时候,发现不匹配,就又停下来了。
接着,读temp_ds1的下一行,40,读temp_ds2的最后匹配的那一行,20,然后继续往下读,直到读到60才停止。
排序合并连接就是通过这种方式,直到读到temp_ds2的最后一个70。相对于嵌套循环连接来说,它的优点是,不需要每一次匹配都从头读到尾。
例子2
使用索引的排序合并连接,
SELECT e.employee_id, e.last_name, e.first_name, e.department_id,
d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
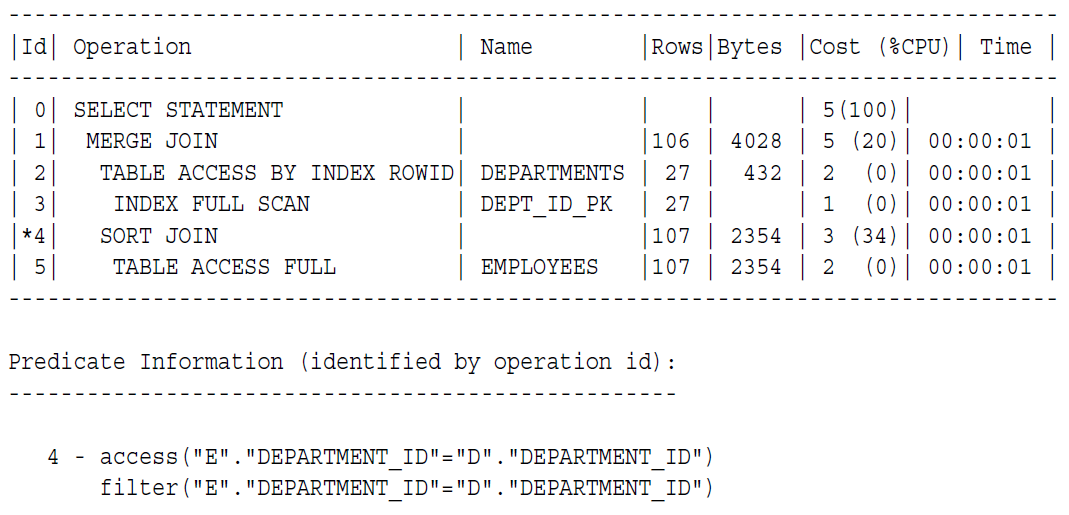
连接的两个表,一个是DEPARTMENTS表,一个是EMPLOYEES表,DEPT_ID_PK是department表上的索引,从执行计划可以看出,数据库在读departments表的时候使用了索引,避免了排序,单独对employees表做了排序,这一步会消耗很多CPU。
例子3
没有索引的排序合并连接,跟上个例子一样的语句,只不过这一次指定使用MERGE, 并且指定不使用索引。
SELECT /*+ USE_MERGE(d e) NO_INDEX(d) */ e.employee_id, e.last_name, e.first_name,
e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
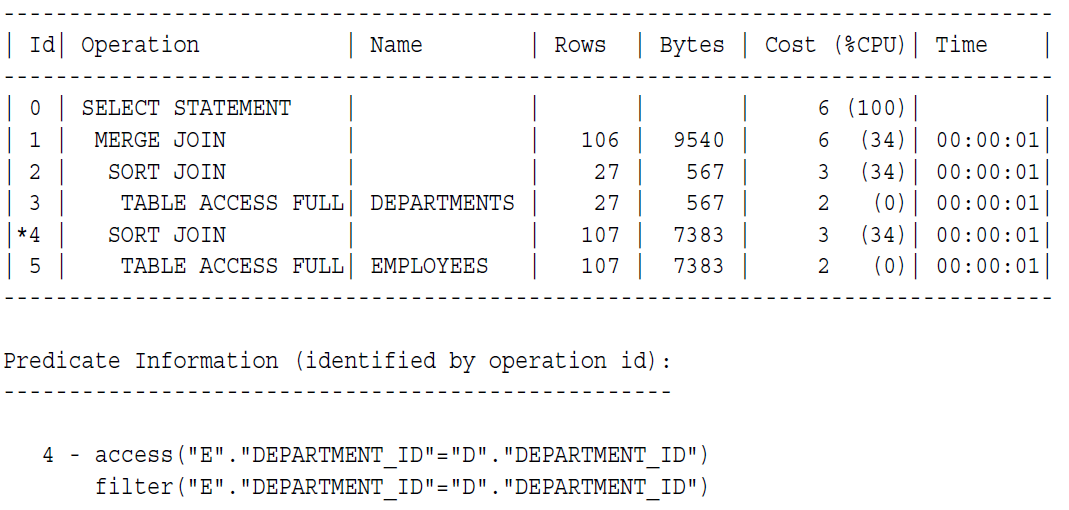
因为加了hint忽略索引,Step 2和Step 3的成本提高了67%
排序合并连接控制
使用USE_MERGE可以指定一条SQL用不用排序合并连接。
某些情况通过这个来覆盖优化器的选择是有好处的,比如优化器可以选择全表扫描来避免排序操作。
但是,如果是通过索引和单块读来全扫大表,而不是通过一个快速的全表扫描,则会导致成本的增加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号