
SQL调优之五:哈希连接(Hash Joins)
哈希连接
数据库一般使用hash join来连接更大的数据集。
优化器会使用两个数据集中比较小的那个,在连接列上创建一个摆放在内存里的hash表,然后使用唯一性的hash函数来指定每一行在hash表里的存放位置。
然后数据库会扫描大的那个数据集,探测hash表,找到匹配的行。
优化器什么时候会考虑使用hash join?
一般来说,在需要等式连接数据量更大的两个数据集的时候,Oracle会考虑使用hash join(或者一个小表但是很大比例的数据需要被连接的时候)。
在做哈希连接的时候,如果较小的数据集能够完全放到内存里面,这个时候它是最高效的(低成本高效益)。在这个情况下,它成本主要是在两个数据集之间传递的单次读。
因为hash表是存在PGA中的,数据库可以不需要加闩锁直接访问数据,这样子能够避免重复性地加闩锁再从缓存读数据块,从而减少逻辑I/O。
如果数据集无法整个放到内存里面,那么数据库就会对数据集进行分区,然后一个分区一个分区进行连接。这种情况会使用很多内存排序区域,以及temporary表空间的大量I/O。
尽管如此,hash join仍然可以是最高成本效益比的,尤其是当数据库使用并行查询服务的时候。
哈希连接怎么工作的?
一个哈希算法会获取输入的数据集,然后通过一个hash函数来生成一个在1到n之间的hash值,n是hash表的大小。在一次哈希连接中,输入的值是连接列的值,输出的值则是在一个数组阵列里面的索引(插槽),也就是哈希表。
哈希表
为了描述hash表,让我们假设在一次deparments表和employees表的连接中,哈希表是hr.departments,然后连接列是department_id。
deparments表的前5行是:

数据库会使用哈希函数,对每一个department_id进行哈希运算,生成一个哈希值。
在这次描述里,hash表有5个插槽(可以更多或者少),也就是n=5,hash值得范围是1到5。
所以哈希函数生成得哈希值如下:
f(10) = 4
f(20) = 1
f(30) = 4
f(40) = 2
f(50) = 5
你可能会注意到,10跟30的哈希值是一样的,这个叫做哈希冲突。在这种情况下,数据库会把10和30的记录给放到同一个插槽(4)里面,用一个链接列表把他们放在一起。
理论上来说,hash表看起来会是:
1 20,Marketing,201,1800
2 40,Human Resources,203,2400
3
4 10,Administration,200,1700 -> 30,Purchasing,114,1700
5 50,Shipping,121,1500
哈希链接:基础步骤
优化器使用比较小的数据集在内存中基于连接列生成一个哈希表,然后扫描较大的表,来找到匹配的行。
基础步骤如下:
1,数据库对比较小的数据集进行一次全扫描,然后在连接列上的每一行应用哈希函数,在PGA里面创建一个哈希表。
伪代码如下:
FOR small_table_row IN (SELECT * FROM small_table)
LOOP
slot_number := HASH(small_table_row.join_key);
INSERT_HASH_TABLE(slot_number,small_table_row);
END LOOP;
2,数据库探测第二个数据集,也叫做探测表,使用的是最低成本访问机制。
通常来说,数据库会对两个数据集进行一次全扫描,无论是大的还是小的数据集。它的伪代码如下:
FOR large_table_row IN (SELECT * FROM large_table) --针对大表里的每一行,循环
LOOP
slot_number := HASH(large_table_row.join_key); --对大表的行进行哈希运算,获得slot值
small_table_row = LOOKUP_HASH_TABLE(slot_number,large_table_row.join_key); -- 根据连接条件,到对应的slot里面查找是否有匹配的小表的行
IF small_table_row FOUND --如果找到匹配的
THEN
output small_table_row + large_table_row; --输出小表的行
END IF;
END LOOP;
对于从大表返回的每一行数据,数据库会做以下操作:
a. 在连接列,应用相同的哈希函数,然后计算出在哈希表里对应的slot值(插槽)。比如说,去探索哈希表里有没有department ID等于30的,数据库会对30应用哈希函数,计算出来的插槽的值为4.
b. 探查哈希表,看看插槽里是否有数据,如果插槽里没有数据,那么数据库就会循环大表里的下一行,如果插槽里有数据,数据库就会进行下一步。
c. 检查连接列,看看是不是有匹配的数据。如果有匹配到的,那么数据库就会返回这些行,或者把这些行传递到执行计划的下一步,然后继续处理大表的下一行。
如果插槽里面有多行数据,那么数据库会沿着链接列表往下查找,直到找到匹配的数据。
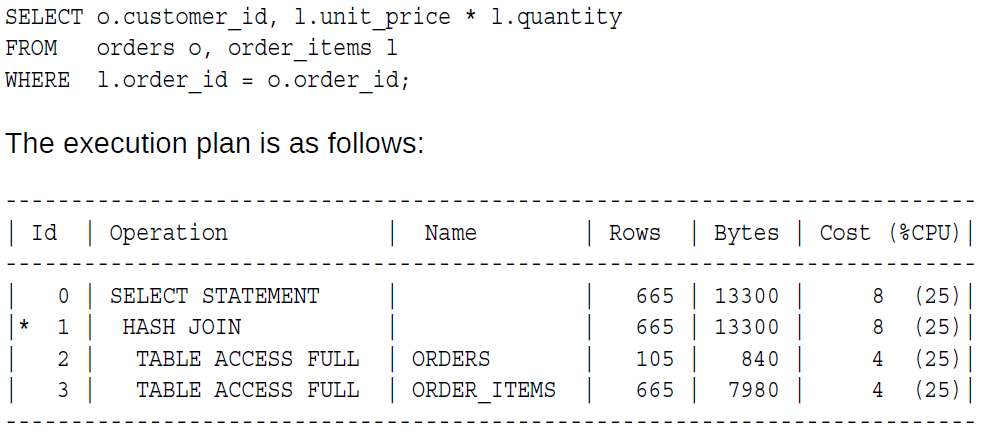
看看下面这个执行计划,order_items表的估算返回行数是665,是orders表105的6倍多,所以数据库会用orders表来建哈希表。在执行计划里面,先执行的那一步,在这里是第2步,是用来构建哈希表的数据集,而下一个表,则是来探测哈希表的。
当哈希表无法整个存到PGA里面的时候,哈希连接是怎么做的?
当哈希表无法整个存到PGA里面的时候,数据库会使用临时表空间来存储哈希表的一部分(也就是分区)以及有些时候大表用来探查哈希表的一部分(分区)。
其基本步骤是:
1,数据库会对较小的数据集做一次全扫描,然后在PGA以及磁盘上创建哈希bucket(桶)的数组。
当PGA哈希区域满了的时候,数据库会找到当前哈希表里最大的部分,把它写到磁盘上的临时空间,相当于把现有最占PGA的那个bucket给写到了磁盘上,然后后续属于这个bucket的数据,都会直接写到磁盘上。如果PGA后来又满了,则会重复这个过程。因此,哈希表的一部分在PGA里面,一部分在磁盘上。
2,数据库在读取另一个数据集的时候会做一次重要传递:
针对每一行:
a,应用相同的哈希函数,计算出相关的哈希bucket的数值
b,探查哈希表,确定这一行在不在内存里的hash bucket里面
如果哈希值指向了内存里面的行,那么数据库就完成了这一次连接并返回这一行。如果哈希值指向的值是在磁盘上的分区里,那么,数据库会使用同样的分区方案,把这一行存到临时表空间里
c,数据库会一个一个地读取在磁盘上的临时空间
d,数据库会把每一个分区里的数据,和在磁盘上临时分区里面的数据进行连接
如果对更详细的内容感兴趣,可以看一下这个link
http://www.dbsnake.net/oracle-hash-join.html
稍微总结一下这个link的几个补充:
1,一个Hash Table是由多个Hash Partition所组成,而一个Hash Partition又是由多个Hash Bucket所组成
2,在做哈希计算的时候,会生成两个哈希值,第二个哈希值在将磁盘上的分区写回内存的时候被用来构建哈希表
3,在创建哈希分区的时候,会同时创建一个位图,这个位图用来标记bucket是否有记录
3,在构建完哈希分区后,Oracle会对这些哈希分区进行排序,尽可能保证更多的分区在内存里
4,当在探查哈希表的时候没有找到需要的bucket,那么数据库会去位图里查找,如果位图显示bucket里面有数据,那么数据库就会同样用哈希函数在磁盘上创建同样的哈希分区,然后把数据和第二个哈希值放进去。
如果位图上显示这个buket没有数据,那么数据库就不需要再去做接下来的操作,直接过滤掉这部分,这就是位图过滤
5,对于在磁盘上的哈希分区,数据库会将第一个数据集和第二个数据集的相同分区进行连接,选择两者之间较小的数据集根据第二个哈希值,到内存里面构建新的哈希表。因为哪个数据集做哈希表不是固定的,所以这也叫“动态角色互换”
6,哈希连接不一定会排序,或者说绝大多数情况下不会排序
7,哈希连接用来构建哈希表的选择列的选择性要尽可能的好,因为这个选择性会决定哈希bucket里面的记录数,而bucket里面的记录数数量又会影响哈希遍历的效率。如果哈希bucket里面的数据太多,可能会严重影响哈希连接的效率。此时典型的表现就是,哈希连接执行了很长时间没有结束,然后数据库的CPU消耗很高,但是逻辑读却很低,因为此时大部分时间都消耗在了遍历哈希bucket上,而哈希表又是在PGA中,所以逻辑读很低
8,哈希连接只适用于等式连接,就算是反式连接也会被先转换成等式连接
9,哈希连接很适合于一个小表和一个大表之间的连接,特别是小表的可选择性很好的情况下,这个时候哈希连接的可近似看作是和全扫大表的时间相当
10,如果基于小的数据集构建的哈希表能够整个放入到PGA中,执行效率会很好
哈希连接的控制
使用USE_HASH hint来指定优化器使用哈希连接
适用10104事件观察哈希连接的过程:
oradebug setmypid
oradebug event 10104 trace name context forever, level 1
set autotrace traceonly
实际执行目标SQL(必须要实际执行该SQL,不能用explain plan for)
oradebug tracefile_name
例子:
“Number of in-memory partitions (may have changed): 8”、“Final number of hash buckets: 2048”、“Total buckets: 2048 Empty buckets: 1249 Non-empty buckets: 799”、“Total number of rows: 1000”、“Maximum number of rows in a bucket: 4”、“Disabled bitmap filtering: filtered rows=0 minimum required=50 out of=1000”等,这说明上述哈希连接驱动结果集的记录数为1000,共有8个Hash Partition、2048个Hash Bucket,这2048个Hash Bucket中有1249个是空的(即没有记录)、799个有记录,包含记录数最多的一个Hash Bucket所含记录的数量为4以及上述哈希连接并没有启用位图过滤
哈希连接一些相关的参数:
hash_multiblock_io_count
hash_area_size

 浙公网安备 33010602011771号
浙公网安备 33010602011771号