第四周小组作业:WordCount优化
本次项目github地址:https://github.com/wzfhuster/software_test_tasks.git
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计任务需要多少时间 | 30 | 60 |
| Development | 开发 | 180 | 240 |
| Analysis | 需求分析 | 20 | 30 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 | 30 | 10 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 30 | 40 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试 | 50 | 10 |
| Reporting | 报告 | 90 | 240 |
| Test Report | 测试报告 | 30 | 120 |
| Size Measurement | 计算工作量 | 20 | 50 |
| Postmortem | 总结 | 20 | 60 |
| 合计 | 360 | 520 |
模块编写
- 本次小组作业我所负责的模块是输入和输出控制,在java中分别是wcProInput.java和wcProOutput.java
- 输入模块接口的实现:public static BuffereadReader getInput(String[] args)
输入模块检验文件名的最后四个字符是否是.txt,在代码中已经使用toLowerCase()将大写字母自动转换为小写字母,即在.txt中出现大写依然是正确的。
- 输出模块接口的实现:public static String output(Map<String, Integer> map,String filename)
具体实现见代码注释。
- 输入模块
代码如下:
package wordCountPro; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; public class wcProInput { public static BufferedReader getInput(String[] args) { if(args.length==0) System.out.println("You input nothing!"); else if(args.length>1) System.out.println("You can only input one name!"); else{ int len = args[0].length(); String name = args[0]; if(len>4 && name.toLowerCase().charAt(len-1)=='t'&&name.toLowerCase().charAt(len-2)=='x' && name.toLowerCase().charAt(len-3)=='t' && name.toLowerCase().charAt(len-4)=='.') { try { BufferedReader in = new BufferedReader(new FileReader(name)); return in; } catch (FileNotFoundException e) { e.printStackTrace(); System.out.println("文件读入错误或者没有该文件"); } } else System.out.println("不是一个合法的txt文件!"); } return null; } }
- 输出模块
代码如下:
package wordCountPro; import java.io.FileWriter; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; import java.util.Map; public class wcProOutput { /* * 次函数用来将单词统计的情况输出到指定的result.txt文件中 * 该函数传入的参数为:一个map,统计了每个单词和单词对应的个数的一个map * 然后对map进行排序后写入文件中 * * */ public static String output(Map<String, Integer> map,String filename) { FileWriter w = null; List<Map.Entry<String, Integer>> list = null; String s = ""; try { w = new FileWriter(filename); //通过ArrayList构造函数把map.entrySet()转化成list list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet()); // 通过比较器实现比较排序 Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> map1, Map.Entry<String, Integer> map2) { //在这里优先使用单词的个数由大到小的排序 if(map1.getValue()>map2.getValue()) return -1; else if(map1.getValue()<map2.getValue()) return 1; else //单词的词频相同时,按照单词字母排序 return map1.getKey().compareTo(map2.getKey()); } }); int i=0; int len = list.size(); //这里按照顺序写入文件,当单词个数超过100个时候,写入前100个 for(;i<len-1&&i<99;i++) { // System.out.println(list.get(i).getKey().toLowerCase() + " " + list.get(i).getValue()); // System.out.println(); w.write(list.get(i).getKey() + " " + list.get(i).getValue()+"\r\n\r\n"); s+=(list.get(i).getKey() + " " + list.get(i).getValue()+" \n "); } //输出文件末尾多余的换行符应去除 if(len>0) { // System.out.println(list.get(i).getKey().toLowerCase() + " " + list.get(i).getValue()); w.write(list.get(i).getKey() + " " + list.get(i).getValue()); s+=(list.get(i).getKey() + " " + list.get(i).getValue()); } } catch (IOException e) { e.printStackTrace(); System.out.println("文件写入错误!"); }finally{ try { w.close(); } catch (IOException e) { e.printStackTrace(); } } return s; } }
测试用例的设计
因为我负责的是input和output的编写,所以我的测试用例主要针对io的正确性进行测试

单元测试
- 输入测试代码如下:
package wordCountProTest; import static org.junit.Assert.*; import java.io.BufferedReader; import org.junit.Test; import wordCountPro.wcProInput; public class wcProInputTest { @Test public void testGetInput1() { String s[] = {"testtxt"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput2() { String s[] = {"test.txt"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput3() { String s[] = {"test.txt","jf"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput4() { String s[] = {"testtxt--"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput5() { String s[] = {"testtxt-","hdsjf"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput6() { String s[] = {}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput7() { String s[] = {"test1.Txt"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput8() { String s[] = {"test.java"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput9() { String s[] = {"test_1.txt"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } @Test public void testGetInput10() { String s[] = {"test_2t.txt"}; assertEquals(BufferedReader.class, wcProInput.getInput(s).getClass()); } }
相应的测试脚本运行结果如下:
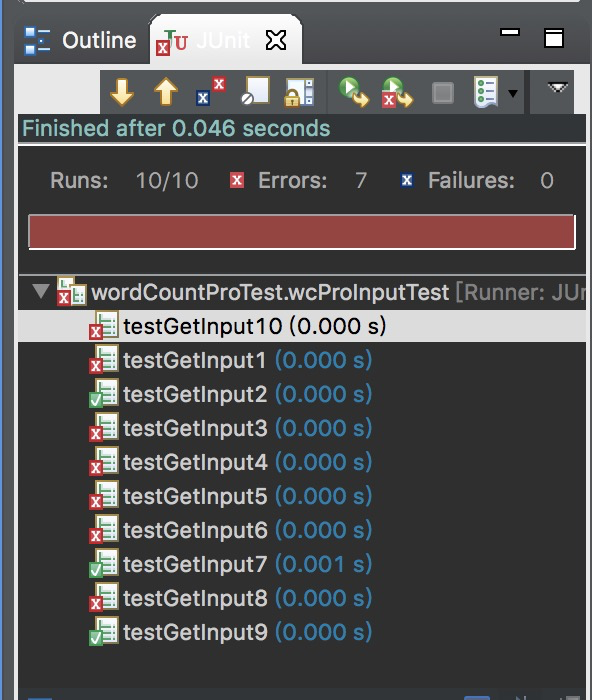
- 输出测试代码如下:
package wordCountProTest; import static org.junit.Assert.*; import java.util.HashMap; import java.util.List; import java.util.Map; import org.junit.Before; import org.junit.Test; import wordCountPro.wcProOutput; public class wcProOutputTest { Map<String, Integer> map = new HashMap<String, Integer>(); List<Map.Entry<String, Integer>> list = null; @Before public void setUp() { map.clear(); } @Test public void testOutput1() { //因为单词在wcProMain中的wordCount函数已经转换成小写了 //所以这里写入测试用例的时候,只需要测试小写字母的单词即可! map.put("i", 180); map.put("this", 200); map.put("the", 180); map.put("ij", 180); //期待输出的结果,不同单词和词频对之间用"\n"来隔开表示换行 String expectResult = "this 200 \n i 180 \n ij 180 \n the 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput2() { map.put("dfj", 200); map.put("faien", 345); map.put("ij", 180); map.put("hehe", 180); String expectResult = "faien 345 \n dfj 200 \n hehe 180 \n ij 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput3() { map.put("dfj", 200); map.put("ij", 345); map.put("i", 180); map.put("hehe", 180); String expectResult = "ij 345 \n dfj 200 \n hehe 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput4() { map.put("dfj", 200); map.put("ij", 345); map.put("i", 180); map.put("hh", 180); String expectResult = "ij 345 \n dfj 200 \n hh 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput5() { map.put("dfj", 200); map.put("mm", 345); map.put("i", 180); map.put("hehe", 180); String expectResult = "mm 345 \n dfj 200 \n hehe 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput6() { map.put("dfj", 200); map.put("zz", 3095); map.put("i", 180); map.put("hehe", 180); String expectResult = "zz 3095 \n dfj 200 \n hehe 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput7() { map.put("dfj", 200); map.put("ij", 345); map.put("i", 180); map.put("hehe", 180); String expectResult = "ij 345 \n dfj 200 \n hehe 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput8() { map.put("dfj", 200); map.put("ij", 345); map.put("i", 180); map.put("hehe", 180); String expectResult = "ij 345 \n dfj 200 \n hehe 180 \n i 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput9() { map.put("dfj", 200); map.put("i", 345); map.put("iout", 180); map.put("ii", 180); String expectResult = "i 345 \n dfj 200 \n ii 180 \n iout 180"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } @Test public void testOutput10() { map.put("dfj", 200); map.put("i-j", 345); String expectResult = "i-j 345 \n dfj 200"; assertEquals(expectResult,wcProOutput.output(map, "result.txt")); } }
相应的测试脚本运行如下:
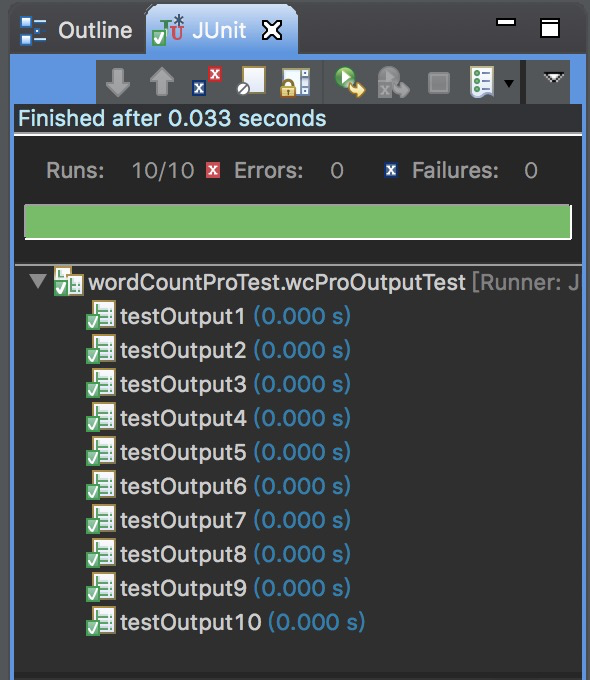
- 测试评价
由测试的结果来看目前给出的输入和输出10个测试用例都已经通过了测试,测试质量还不错,错误的也报出了正确的错误提示。被测试模块的质量基本符合要求但这不代表程序一
定正确,可能还有其它小小的问题没有被发现,之后可以增加测试情况的种类来测试程序,发现问题并修改,来增加程序的健壮性。
小组贡献率
根据小组讨论,自己的贡献率约为0.2
参考文献链接
http://www.cnblogs.com/ningjing-zhiyuan/p/8654132.html
https://www.cnblogs.com/avivahe/p/5657070.html
https://blog.csdn.net/wiebin36/article/details/51912794

 浙公网安备 33010602011771号
浙公网安备 33010602011771号