Spark Job调优(Part 1)
原文链接:https://wongxingjun.github.io/2016/05/11/Spark-Job%E8%B0%83%E4%BC%98-Part-1/
Spark应用的执行效率是所有程序员需要关心的问题,单纯从代码层面去了解和优化明显是不够的,本文介绍Spark的底层执行模式,并给出了一些经验性的调优建议。本文是对Cloudera一篇博文的译文。
学习调优你的Spark Job获得最优的效率
当你通过公共API写Spark代码的时候,你会遇到诸如transformation,action和RDD这些字眼。在这个层面理解Spark对写Spark程序是很重要的。类似的,当情况变得糟糕时,或者你纠结于Web UI去搞清楚你的应用为什么跑得这么慢的时候,你就会遇到一些新的字眼,比如job,stage和task。在这个层面理解Spark对写好的Spark程序是很重要的,这个好当然指的就是快。为了写出执行效率高的Spark程序,理解Spark底层的执行模式是很有帮助的。
本文中你会学习到Spark程序到底如何在集群上执行的。然后有几点涉及Spark执行模式的如何写高效程序的经验性建议。
Spark怎么执行程序
一个Spark应用包含一个driver进程和一系列分布在集群节点上的executor进程。driver是上层负责控制工作流的进程。executor进程负责以task形式执行工作,同时也存储一些用户cache的数据。driver和executor在整个应用的生命周期中都保持运行,即使随后会有动态资源分配使之改变。单个executor有多个slot来执行task,并在其生命周期中并发执行。如何部署这些进程到集群中取决于使用的集群管理器(YARN,Mesos或者Standalone),但每个Spark应用中都有driver和executor。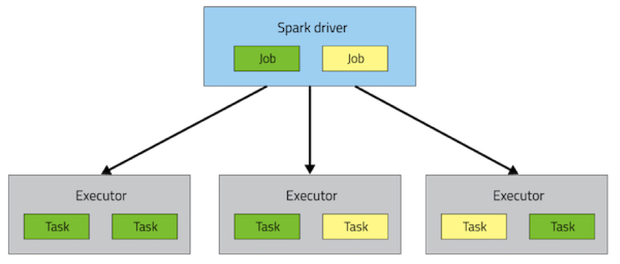
执行模式最上层是job。在Spark应用中调用一个action就会触发开始一个Spark Job来完成这个action对应的操作。为了解析这个job的全貌,Spark会检查action的RDD依赖关系图并由此生成一个执行计划。执行计划从后面最远的RDD,也就是那些不依赖其他RDD,或者引用一些已经缓存的数据的RDD,直到最后产生出action结果的RDD。
执行计划包括将job的transformations划分成stage。一个stage对应着执行相同代码的task集合,每个task负责不同的数据子集。每个stage包括一系列不需要shuffle数据就可以完成的transformations。
那么什么决定数据是否需要被shuffle呢?回忆一下,RDD是由固定数量的partition分区组成,每个分区又由一些record记录组成。对那些由被称作窄transformation(比如map和filter)返回的RDD,用来计算单个分区里的record所需的record都在父RDD的单个分区中,每个对象只依赖父RDD中的单个对象。coalesce之类的操作能够产生处理多个分区的task,但是这种transformation依旧被视作是窄transformation,因为用来计算任何一个单个的输出record的输入record依旧只能在有限的分区集合中。
但是Spark也支持诸如groupByKey和reduceByKey这种宽的transformation。在这些依赖中,用来计算单个分区中record的数据可能分布在父RDD的多个分区中。一个task处理的分区里所有相同key的tuple元组最后必须最终分到同一个分区中。为了满足这些操作,Spark就得shuffle了,shuffle操作可以将分散于集群中的数据和结果传进一个新的stage,这个新的stage由新的分区组成(这些分区就是shuffle的结果)。
比如说,看下面的代码:
|
1
2
3
4
5
|
sc.textFile("someFile.txt").
map(mapFunc).
flatMap(flatMapFunc).
filter(filterFunc).
count()
|
这段代码只执行一个action,这个action依赖于一个文本文件产生的RDD上的一系列操作。然后这个action可以在一个stage内完成,因为三个操作的输出所依赖的计算数据没有来自输入RDD的不同分区的。
对比一下,下面这段代码是用来找出在一个文本文件中出现次数超过1000次的所有单词中所有字母出现的次数
|
1
2
3
4
5
6
|
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))
val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
val filtered = wordCounts.filter(_._2 >= 1000)
val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).
reduceByKey(_ + _)
charCounts.collect()
|
这个过程会被分解成3个stage。reduceByKey操作产生stage分界,因为计算它的输出需要根据key重新对数据分区。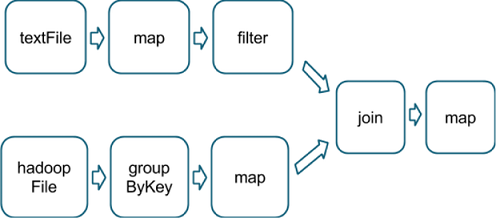
粉红色框中表示用于执行的stage图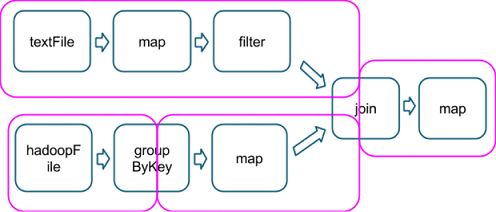
在每个stage边界,父stage将数据写入磁盘,然后子stage的task通过网络将之拉取。因为会产生严重的磁盘和网络IO开销,所以stage边界的代价是很高昂的,我们应该尽可能避免。父stage的数据分区数是可能和子stage分区数不同的。触发stage边界的transformation可以接受一个numPartitions参数来决定在子stage中将数据分成多少个分区。
和MapReduce Job中reducer个数是个很重要的参数一样,调整stage边界的分区数常常对应用性能起决定性作用。接下来将会深入介绍如何调优这个参数。
选择正确的操作符
当开发者试图用Spark来完成一些工作时总是倾向于选择一些产生同样结果的action编排方式和transformation,然而并不是所有的编排都有同样的性能:避免常见的陷阱和选择正确的编排可以对一个应用的性能产生很大的影响。有一些规则和建议可以帮你如何抉择。
最近在Spark-5097的工作开始增加了SchemaRDD来用Spark的核心API向开发者打开Spark的Catalyst optimizer,允许Spark在使用那些操作上做一些上层选择。当SchemaRDD成为一个稳定的组件时,用户可以避免再做一些这类决定了。
选择操作的编排方式根本目的就是为了减少shuffle数和shuffle的数据量。这是因为shuffle是代价相当高的操作,所有的shuffle数据必须被写到磁盘然后通过网络传输。repartition,join,cogroup和任何带有By,ByKey的转换操作都会产生shuffle。并非所有的操作代价都是相同的,但是一些Spark开发菜鸟们遇到的性能陷阱都是因为做了错误的选择:
- 进行关联的规约操作时避免使用groupByKey
比如说rdd.groupByKey().mapValues(_.sum)就可以和rdd.reduceByKey(+)产生出同样的计算结果。但是前者却需要将整个数据集通过网络传输,而后者只需要对每个分区中的每个key求本地和,然后在shuffle之后将之合并成一个更大的和。
- 当输入输出值类型不同时避免使用reduceByKey
比如说写一个操作找出每个key对应的不同字符串,一种方式就是使用map将每个元素转换成一个Set之后再通过reduceByKey来合并:
|
1
2
|
rdd.map(kv => (kv._1, new Set[String]() + kv._2))
.reduceByKey(_ ++ _)
|
这段代码会造成大量不必要的对象创建,因为每个record必须分配一个新的set。在这种情况下最好用aggregateByKey操作,它可以更高效地做map-side的聚合:
|
1
2
3
4
|
val zero = new collection.mutable.Set[String]()
rdd.aggregateByKey(zero)(
(set, v) => set += v,
(set1, set2) => set1 ++= set2)
|
- 避免使用flatMap-join-groupBy模式
当两个数据集已经通过key分组了然后你想保持他们分组的情况下将之连接起来,你可以就使用cogroup,这就可以避免所有group的拆解和重组造成的开销。
何时没有shuffle
知道上面的操作何时不会产生shuffle也是很有用的,Spark知道当前面的转换已经根据相同的partitioner分区器分好区的时候如何避免shuffle。看下面的代码:
|
1
2
3
|
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)
|
因为没有分区器传到reduceByKey,就会使用默认的分区器,最后导致rdd1和rdd2都是hash-partitioned(hash分区规则),这两个reduceByKey会产生两个shuffle。如果RDD有相同数目的分区,join操作不需要额外的shuffle操作。因为RDD是相同分区的,rdd1中任何一个分区的key集合都只能出现在rdd2中的单个分区中。因此rdd3中任何一个输出分区的内容仅仅依赖rdd1和rdd2中的单个分区,第三次shuffle就没有必要了。
比如说,如果somRdd有4个分区,someOtherRdd有两个分区,两个reduceByKey都用3个分区,那么执行的task集合就会像下面这样: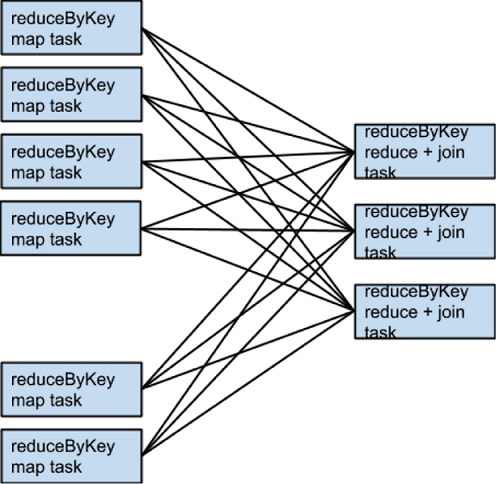
那如果rdd1和rdd2使用不同的分区器,或者使用默认的hash分区器但配置不同的分区数呢?那样的话,仅仅只有一个rdd(较少分区的RDD)需要重新shuffle后再join。
一样的转换,一样的输入但不一样的分区数,task执行如下: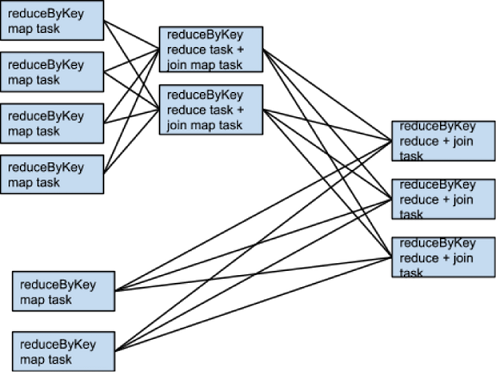
有一种当join两个数据集时避免shuffle操作的方法就是使用broadcast variables广播变量的优点。当一个数据集足够小,小到可以在单个executor的内存中存放时,可以将它在driver上载入一个hash table中然后广播给每个executor。然后map转换就可以参照hash table来查询。
何时shuffle越多越好
在尽力减少shuffle数的规则外有一个例外。额外的shuffle操作可以有利于增加并行度。比如说你的数据到了一些不可分割的文件里,InputFormat指定的分区方式可能将大量的record放进每个分区中,这样就不能产生足够多的分区来充分利用可用的core。在这种情况下在载入数据后通过重新分区来将数据分成更多的分区(这就会带来一次shuffle操作)就可以让之后的操作可以利用更多集群的CPU。
还有一个例外就是当用reduce或者aggregate action来聚合数据到driver时。当对大量分区进行巨厚的时候,在driver上单线程合并所有的结果很快就会变成计算的瓶颈。为了减少driver上的负载,可以先用reduceByKey或aggregateByKey来进行一次分布式的合并,这样可以将数据集分成更少的分区。在将结果发送到driver上进行最后的聚合之前分区的value之间两两并行合并。可以看一下treeReduce和treeAggregate是如何做的。(注意在1.2版本中,大多数最近的版本都被标记为开发者API,SPARK-5430开始试图将其作为稳定API加入core中)
当聚合数据已经根据一个key分组了的时候这个小窍门分外有效。比如说,一个应用想要统计一篇文章中所有单词出现的次数,然后将结果以map形式推送到driver上。一种方式可以通过aggregate action实现,具体就是每个分区进行一次本地的map,最后在driver上将所有的map合并。另一种方式可以通过aggregateByKey来实现,具体就是分布式进行count,然后简单地collectAsMap结果到driver上。
二次排序
另一个需要知道的重要的机制就是repartitionAndSortWithinPartitions转换,这个转换听起来挺神秘,但是出现所有排序的奇怪情况。它将排序push到shuffle的机器上,在那里大量数据可以被高效地溢写并且排序可以和其他操作结合起来。
比如Apache Hive on Spark在它的join实现中就使用了这种操作,这个转换还在二次排序模式中扮演了重要的模块,在二次排序中你希望将records按key分组然后当迭代到对应key的value上的时候将他们按照特定的顺序表现出来。这种情况需要根据user将events分组然后按照他们出现的时间顺序为每个用户分析events。充分利用repartitionAndSortWithinPartitions转换来做二次排序对用户来说有点难度,但是SPARK-3655即将大大简化一过程。
结论
现在你应该对影响Spark程序性能效率的基本因素有了较好的理解,在Part2中将会介绍怎么对资源请求、并行度和数据结构进行调优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号