
硬核!我花5小时肝出这篇Redis缓存解决方案,带你起飞!
写在前面
对于缓存穿透,雪崩相信很多小伙伴都有听过,不管是工作中还是面试都热点问题,本文重点带大家分析这些问题,给位看官请往下看!
同时用XMind画了一张导图记录Redis的学习笔记和一些面试解析(源文件对部分节点有详细备注和参考资料, 已经完善更新):

一、缓存穿透
1. 什么是缓存穿透?
为了缓解持久层数据库的压力,在服务器和存储层之间添加了一层缓存;
一个简单的正常请求: 当客户端发起请求时,服务器响应处理,会先从redis缓存层查询客户端需要的请求数据,如果缓存层有缓存的数据,会将数据返回给服务器,服务器再返回给客户端;如果缓存层中没有客户端需要的数据,则会去底层存储层查找,再返回给服务器;
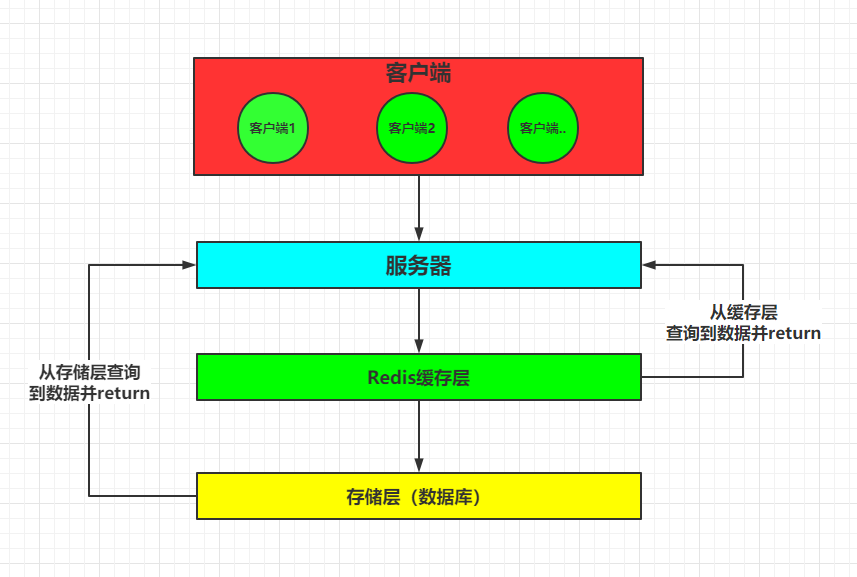
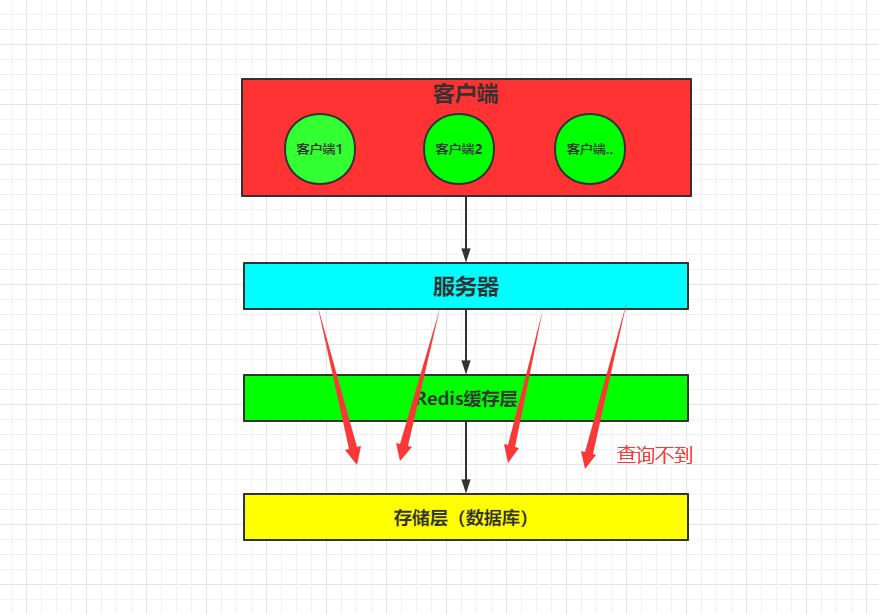
缓存穿透就是: 当客户端想要查询一个数据,发现redis缓存层中没有(即缓存没有命中),于是向持久层数据库查询,发现也没有,于是本次查询失败;当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库,此时会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
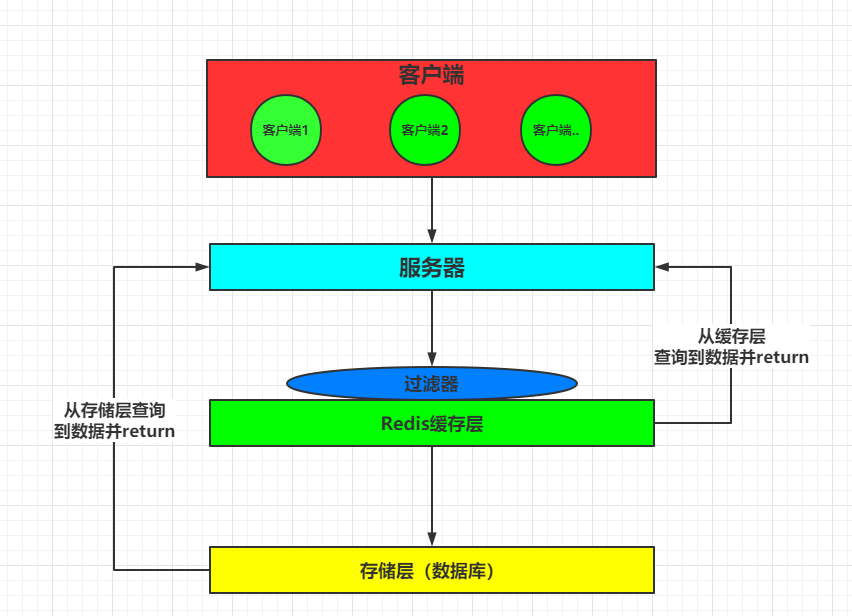
2. 解决办法
在缓存层加布隆过滤器,通俗简述一下其作用:将数据库中的 id ,通过某方式映射到布隆过滤器,当处理不存在的 id 时,布隆过滤器会将该请求过直接过滤出去,不会到数据库做操作。
3. 布隆过滤器
1)概述: 布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,实际上是一个很长的二进制向量和一系列随机映射函数,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
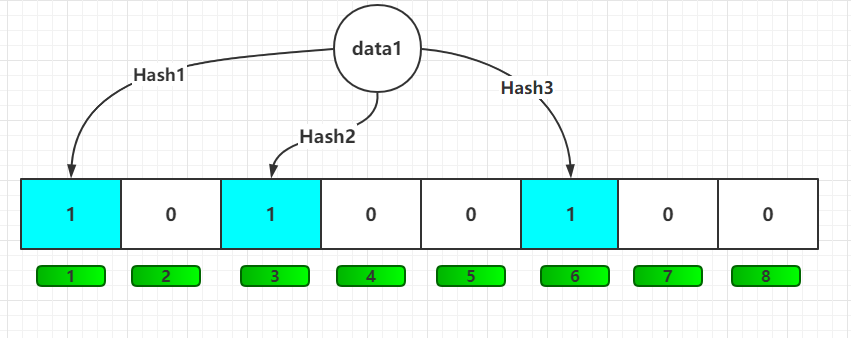
2)返回结果的不确切性: 布隆过滤器是一个 bit 向量或者说 bit 数组:假设有8位
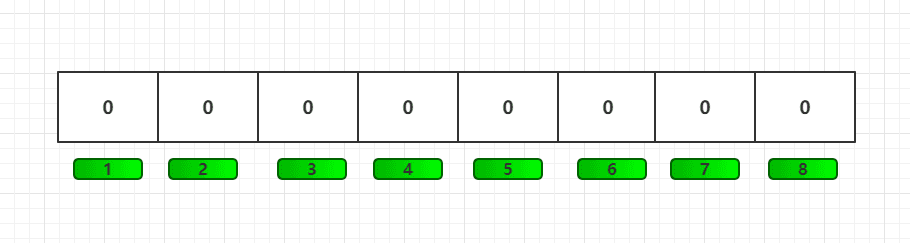
映射数据1: 使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置为 1,比如三次hash完后,data1 将1、3、6位,置为1;
映射数据2: data2 将2、3、6位,置为1,此时由于hash为随机性,所以6位和 data1 有重复的,便会覆盖 data1 的第6位的1;
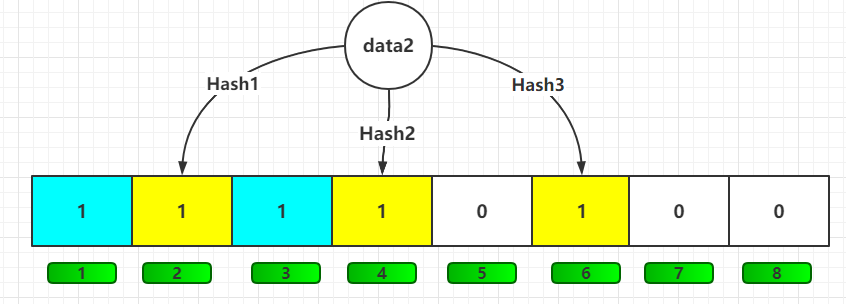
问题来了!!
6 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了,当我们如果想查询 data3这个值是否存在,假设哈希函数返回了 1、5、6三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 data3 这个值不存在。而当我们需要查询 data1 这个值是否存在的话,那么哈希函数必然会返回 1、3、6,然后我们检查发现这三个 bit 位上的值均为 1,那么我们是否可以说 data1 存在了么?答案是不可以,只能是 data1 这个值可能存在!因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 data4 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他位置位了 1 ,那么程序还是会判断 data4 这个值存在。
所以: 布隆过滤器的长度会直接影响误报率,布隆过滤器越长且误报率越小。
3)简单剖析布隆过滤器源码
导入guava的包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
源码: BloomFilter一共四个create方法,最终都是走向第四个方法;
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long) expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
......
}
参数类型: funnel:数据类型;expectedInsertions:期望插入的值的个数;fpp:错误率(默认值为0.03);strategy:哈希算法。
总结: 错误率越大,所需空间和时间越小;反之错误率越小,所需空间和时间越大!
二、缓存击穿
1、什么是缓存击穿?
在平常高并发的系统中,大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿
2、问题排查
- Redis中某个key过期,该key访问量巨大
- 多个数据请求从服务器直接压到Redis后,均未命中
- Redis在短时间内发起了大量对数据库中同一数据的访问
3、如何解决
1. 使用互斥锁(mutex key)
这种解决方案思路比较简单,就是只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据就可以了。如果是单机,可以用synchronized或者lock来处理,如果是分布式环境可以用分布式锁就可以了(分布式锁,可以用memcache的add, redis的setnx, zookeeper的添加节点操作)。

2. "提前"使用互斥锁(mutex key)
在value内部设置1个超时值(timeout1), timeout1比实际的redis timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中
3. "永远不过期"
-
从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
-
从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
![img]()

4. 缓存屏障
class MyCache{
private ConcurrentHashMap<String, String> map;
private CountDownLatch countDownLatch;
private AtomicInteger atomicInteger;
public MyCache(ConcurrentHashMap<String, String> map, CountDownLatch countDownLatch,
AtomicInteger atomicInteger) {
this.map = map;
this.countDownLatch = countDownLatch;
this.atomicInteger = atomicInteger;
}
public String get(String key){
String value = map.get(key);
if (value != null){
System.out.println(Thread.currentThread().getName()+"\t 线程获取value值 value="+value);
return value;
}
// 如果没获取到值
// 首先尝试获取token,然后去查询db,初始化化缓存;
// 如果没有获取到token,超时等待
if (atomicInteger.compareAndSet(0,1)){
System.out.println(Thread.currentThread().getName()+"\t 线程获取token");
return null;
}
// 其他线程超时等待
try {
System.out.println(Thread.currentThread().getName()+"\t 线程没有获取token,等待中。。。");
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 初始化缓存成功,等待线程被唤醒
// 等待线程等待超时,自动唤醒
System.out.println(Thread.currentThread().getName()+"\t 线程被唤醒,获取value ="+map.get("key"));
return map.get(key);
}
public void put(String key, String value){
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
// 更新状态
atomicInteger.compareAndSet(1, 2);
// 通知其他线程
countDownLatch.countDown();
System.out.println();
System.out.println(Thread.currentThread().getName()+"\t 线程初始化缓存成功!value ="+map.get("key"));
}
}
class MyThread implements Runnable{
private MyCache myCache;
public MyThread(MyCache myCache) {
this.myCache = myCache;
}
@Override
public void run() {
String value = myCache.get("key");
if (value == null){
myCache.put("key","value");
}
}
}
public class CountDownLatchDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache(new ConcurrentHashMap<>(), new CountDownLatch(1), new AtomicInteger(0));
MyThread myThread = new MyThread(myCache);
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
executorService.execute(myThread);
}
}
}
4.总结
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度较高,配合雪崩处理策略即可。
三、缓存雪崩
1. 什么是缓存雪崩?
缓存雪崩是指: 某一时间段,缓存集中过期失效,即缓存层出现了错误,不能正常工作了;于是所有的请求都会达到存储层,存储层的调用量会暴增,造成 “雪崩”;
比如:双十二临近12点,抢购商品,此时会设置商品在缓存区,设置过期时间为1小时,当到了1点时,缓存过期,所有的请求会落到存储层,此时数据库可能扛不住压力,自然 “挂掉”。
2. 解决办法
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据预热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
四、缓存预热
1.什么是缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户直接查询事先被预热的缓存数据。如图所示:

如果不进行预热, 那么 Redis 初识状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
2.问题排查
- 请求数量较高
- 主从之间数据吞吐量较大,数据同步操作频度较高
3.有什么解决方案?
前置准备工作:
-
日常例行统计数据访问记录,统计访问频度较高的热点数据
-
利用LRU数据删除策略,构建数据留存队列
例如:storm与kafka配合
准备工作:
- 将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
- 利用分布式多服务器同时进行数据读取,提速数据加载过程
- 热点数据主从同时预热
实施:
- 使用脚本程序固定触发数据预热过程
- 如果条件允许,使用了CDN(内容分发网络),效果会更好
4.总结
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据
五、缓存降级
降级的情况,就是缓存失效或者缓存服务挂掉的情况下,我们也不去访问数据库。我们直接访问内存部分数据缓存或者直接返回默认数据。
举例来说:
对于应用的首页,一般是访问量非常大的地方,首页里面往往包含了部分推荐商品的展示信息。这些推荐商品都会放到缓存中进行存储,同时我们为了避免缓存的异常情况,对热点商品数据也存储到了内存中。同时内存中还保留了一些默认的商品信息。如下图所示:

降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号