MySQL系列 | 索引数据结构大全
MySQL系列 | 索引数据结构大全
文章来源:https://cloud.tencent.com/developer/article/1742842
C/C++Linux服务器开发/架构师学习:https://ke.qq.com/course/417774?flowToken=1031343
索引是帮助MySQL高效获取数据的排好序的数据结构
二叉树 Binary Search Trees
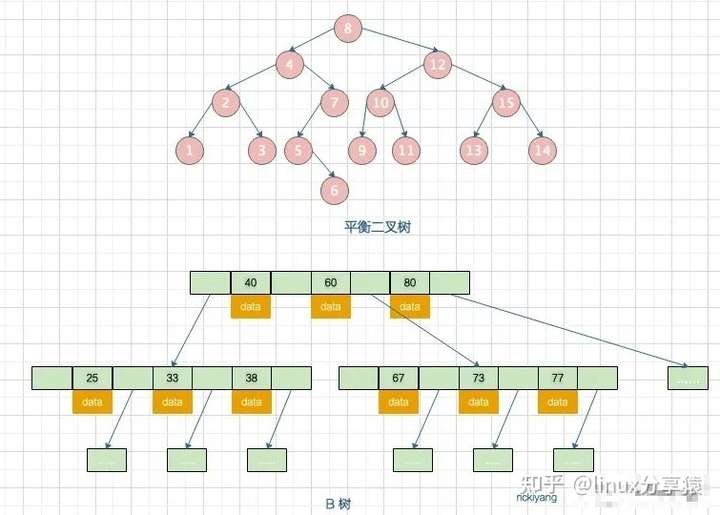
对于二叉树而言,每个节点只能有两个子节点,如果是一颗单边二叉树,查询某个节点的次数与节点所处的高度相同,时间复杂度为 O(n);如果是一颗平衡二叉树,查找效率高出一半,时间复杂度为 O(Log2n)。
并且二叉树还有另一个坏处,二叉树上的每一个节点都是数据节点,那么对于一个比较高的数如果要获取最下面的数据遍历的节点数将会很消耗性能。
红黑树 Red/Black Tree
当单边的节点大于3时候,就会自动调整,这样可以解决二叉树的弊端;红黑树也叫平衡二叉树。
Hash 表
散列表的好处是散列查询单条数据比较快,但是坏处也比较多,比如 Hash 碰撞的解决,范围查找等等。
B 树
B 树是二叉树的升级版,又叫平衡多路查找树。它和平衡二叉树的区别在于:
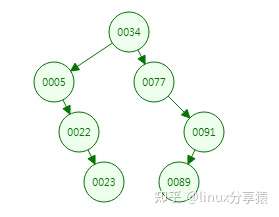
- 平衡二叉树最多两个子树,而 B 树每个节点都可以有多个子树,M 阶 B 树表示每个节点最多有 M 个子树。
- 平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B 树每个「中间节点」有 k-1 个关键字(可以理解为数据)和 k 个子树( k 介于阶数 M 和 M/2 之间,M/2 向上取整)。
- 所有叶子节点均在同一层、叶子节点除了包含关键字和关键字记录的指针外也有指向其子节点的指针,只不过其指针地址都为 null 。
另外,它们相同的点是节点数据也是按照左小右大的顺序排列。我们用一张图来对比它们的区别:
B+ 树
说到 B 树就连着 B+树一起说了。B+ 树是应文件系统所需而产生的一种 B 树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据)非叶子节点只保存索引,不保存实际的数据)。
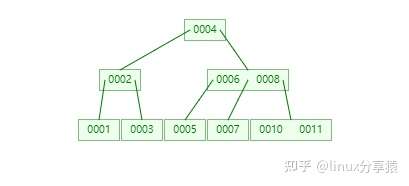
MyISAM 和 InnoDB 索引组织的区别
在 MYSQL 中索引属于存储引级别的概念,存储引擎不同,索引的实现方式也不一样。我们分别看看看 MyISAM 和 InnoDB 中都是如何实现索引功能。
MyISAM 实现
MyISAM 也是使用 B+ 树作为索引存储结构,他的叶子节点 data 域存放的是数据的物理地址,即索引结构和真正的数据结构其实是分开存储的。
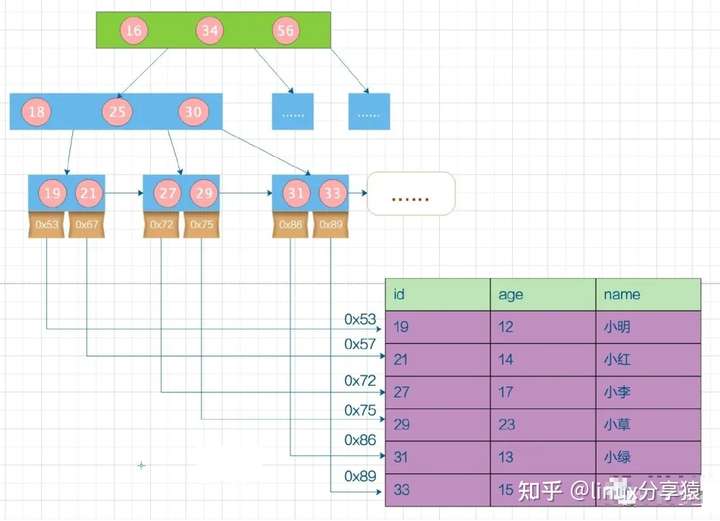
InnoDB 索引实现
MyISAM 索引和数据是分离的,但是在 InnoDB 中却大不相同,InnoDB 中采用主键索引的方式,所有的数据都保存在主键索索引中。
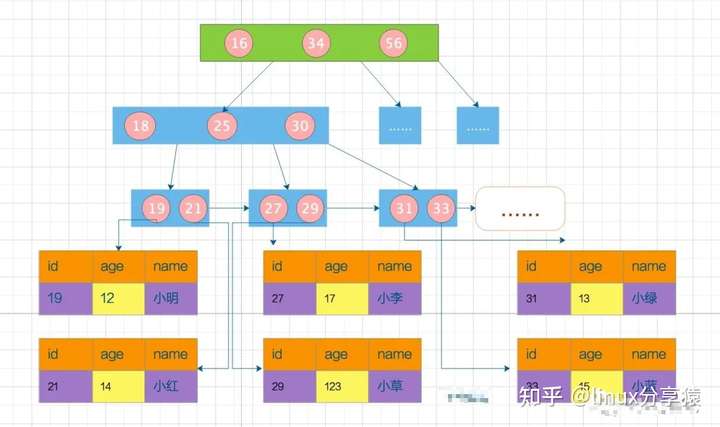
所以这也是为什么 InnoDB 要求每个表都必须要有主键的原因。本身就是基于主键来组织的数据存储。
索引类型
以下所有索引类型都是基于 InnoDB 引擎。
主键索引
主键索引也就是我们说的聚集索引。上面说过主键索引是基于主键来创建的 B+ 树索引结构,如果没有指定主键,也找不到任何一列不重复的列可以作为主键的情况下,InnoDB 会新增一个隐藏列 RowId 作为主键继而创建聚集索引。
二级索引(非主键索引)
二级索引就是指除了主键索引外的索引。主键索引和所有的二级索引都是各自维护各自的 B+ 树结构,但是有个不同的地方在于,二级索引的叶子节点存储的不是数据,而是主键索引对应的主键值。
即二级索引不再保存一份 data 数据,而是去主键索引中查数据。那么对于二级索引查找一条数据索要做的操作就是:
- 首先在二级索引中找到叶子节点对应的数据主键值;
- 根据这个主键值去聚集索引中找到真正对应的数据行。
所以这里需要两次 B+ Tree 查找。
覆盖索引
覆盖索引简单来说就是只查询索引就能获取到数据不必再回表查询,换句话说要查询的列已经被索引列覆盖。
使用覆盖索引有如下优点:
- 索引项通常比记录要小,所以 MySQL 访问更少的数据;
- 索引都按值的大小顺序存储,相对于随机访问记录,需要更少的 I/O;
- 大多数据引擎能更好的缓存索引。比如 MyISAM 只缓存索引;
- 覆盖索引对于 InnoDB 表尤其有用,因为 InnoDB 使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。
- 覆盖索引不能是任何索引,只有 B Tree 索引存储相应的值。而且不同的存储引擎实现覆盖索引的方式都不同,并不是所有存储引擎都支持覆盖索引( Memory 和 Falcon 就不支持)。
联合索引
有的时候我们会对多个列建立一个索引,这种索引被称为联合索引。而关于联合索引的建立和使用,从工作开始你的各位 “师长” 都在教导你要遵循 “左前匹配原则”,那到底是为什么呢?什么是左前匹配原则呢?
比如我们有这样一张表:
CREATE TABLE `test_tb` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`a` varchar(10) NOT NULL,
`b` varchar(10) NOT NULL,
`c` varchar(10) NOT NULL,
`d` int(10) NOT NULL,
`e` int(10) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_a_b_c` (`a`,`b`,`c`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;上表建立了一个联合索引:idx_a_b_c。下面给出一个 SQL, 大家看它会不会走索引查询:
select * from test_tb where b = '10';很显然根据 “左前匹配原则” 肯定不会走索引查询,最终还是全表扫描。
原因就在于联合索引的结构上。上面对 a,b,c 三个字段建立索引,那么对应的 B+ Tree 索引结构每个节点其实是按照三个字段的前后顺序排列的,即 a 字段检索在最前面,然后是 b,然后是 c。如果你的查询不是按照这个顺序来检索,是不会被这个索引识别的。
左前匹配原则
上面说到联合索引会遵循左前匹配原则,那么什么是左前匹配呢?
其实就是字面意义上的从建立索引的第一个字段开始先匹配查询条件,如果当前查询条件不是第一个字段那么就不会走该索引。
另外对于联合索引的使用也有一些限制,比如说:
「遇到范围查询 ( > ,<, between, like) 就会停止匹配」
比如哦我们看这个 SQL:
select * from test_tb where a = '1' and b = '3' and d< 20 and c = '5';大家觉得这个 SQL 会如何使用索引呢?
其实这 SQL 在前面 a,b 的查询中是会走联合索引的,但是在经历了 d 的查询之后,到了 c 就不会使用索引了,因为 d 的查询已经将索引的顺序打乱了,从 d 条件过后就没有办法直接使用联合索引。
Linux、C/C++技术交流群 整理了一些个人觉得比较好的学习书籍、大厂面试题、和热门技术教学视频资料共享在里面(包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等等.),有需要的可以自行添加哦!~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号