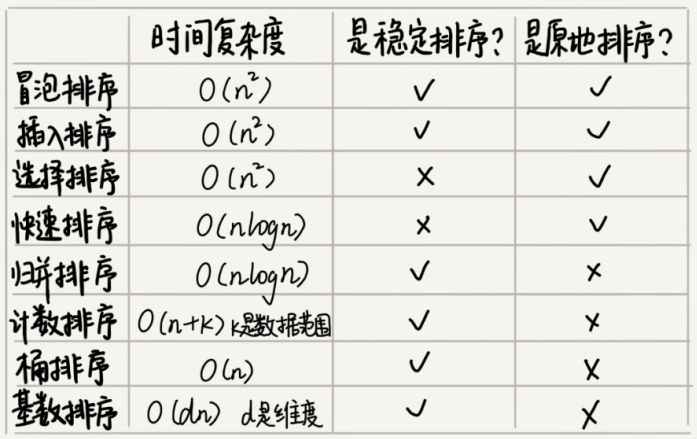
算法笔记-桶排序、计数排序、基数排序
三种时间复杂度是 O(n) 的排序算法:桶排序、计数排序、基数排序。因为这些排序算法的时间复杂度是线性的,所以我们把这类排序算法叫作线性排序(Linear sort)。
桶排序(Bucket sort)
将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。
桶排序对要排序数据的要求是非常苛刻的。首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
//先引用之前的 快排的代码 function quickSort(array &$a) { $n = count($a); quickSortInternally($a, 0, $n - 1); } function quickSortInternally(array &$a, int $l, int $r) { if ($l >= $r) return; $q = partition($a, $l, $r); quickSortInternally($a, $l, $q - 1); quickSortInternally($a, $q + 1, $r); } function partition(&$a, $l, $r): int { $pivot = $a[$r]; $i = $l; for ($j = $l; $j < $r; ++$j) { if ($a[$j] < $pivot) { [$a[$j], $a[$i]] = [$a[$i], $a[$j]]; ++$i; } } [$a[$r], $a[$i]] = [$a[$i], $a[$r]]; return $i; } /** * 桶排序 * 假设一个桶只能放置10个元素 * 当一个桶内元素过多,需要继续分桶 * @param array $numbers * @param [type] $size * * @return void * @date 2018/11/25 * @author yuanliandu */ function bucketSort(array $numbers) { $min = min($numbers); $max = max($numbers); $length = count($numbers); $bucketNumber = ceil(($max-$min)/$length) + 1; $buckets = []; foreach($numbers as $key => $value) { $index = ceil(($value-$min)/$length); $buckets[$index][] = $value; } $result = []; for($i=0;$i<$bucketNumber;$i++) { $bucket = $buckets[$i]; $length = count($bucket); //如果桶内元素为空,跳过这个桶 if($length == 0) { continue; } if( $length > 10) { $bucket = bucketSort($bucket,$length); } quickSort($bucket,0,count($bucket)-1); $result = array_merge($result,$bucket); } return $result; } $numbers = [11, 23, 45, 67, 88, 99, 22, 34, 56, 78, 90, 12, 34, 5, 6, 91, 92, 93, 93, 94, 95, 94, 95, 96, 97, 98, 99, 100]; $size = 10; print_r(bucketSort($numbers, 10));
计数排序(Counting sort)—— 其实是桶排序的一种特殊情况
当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
问题:如何根据年龄给100万用户数据排序?
我们假设年龄的范围最小 1 岁,最大不超过 120 岁。我们可以遍历这 100 万用户,根据年龄将其划分到这 120个桶里,然后依次顺序遍历这 120 个桶中的元素。这样就得到了按照年龄排序的 100 万用户数据。
<?php /** * 计数排序 * 五分制 * 13个人 */ $score = [0, 1, 5, 3, 2, 4, 1, 2, 4, 2, 1, 4, 4]; print_r(countingSort($score)); function countingSort(array $score) { $length = count($score); if ($length <= 1) { return $score; } /** * 统计每个分数的人数 */ $temp = []; $countScore = []; foreach ($score as $key => $value) { @$countScore[$value]++; } /** * 顺序求和 */ for ($i = 1; $i <= 5; $i++) { $countScore[$i] += $countScore[$i - 1]; } /** * 排序 */ foreach ($score as $key => $value) { $countScore[$value]--; $temp[$countScore[$value]] = $value; } //copy for ($i = 0; $i < $length; $i++) { $score[$i] = $temp[$i]; } return $score; }
基数排序(Radix sort)
假设有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
有这样的规律:假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a手机号码已经比 b 手机号码大了,那后面的几位就不用看了。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
<?php /** * 基数排序 * 先根据个位排序、百位、千位........ */ $numbers = [ 1234, 4321, 12, 31, 412, ]; $max = (string)max($numbers);//求出最大数字 $loop = strlen($max);//计算最大数字的长度,决定循环次数 for ($i = 0; $i < $loop; $i++) { radixSort($numbers, $i); } print_r($numbers); /** * 基数排序 * @param array $numbers * @param [type] $loop */ function radixSort(array &$numbers, $loop) { $divisor = pow(10, $loop);//除数 主要决定比较个位数、百位..... $buckets = (new \SplFixedArray(10))->toArray(); foreach ($numbers as $key => $value) { $index = ($value / $divisor) % 10;//计算该数字在哪个桶中 $buckets[$index][] = $value; } /** * 从桶中取出数字 */ $k = 0; for ($i = 0; $i < 10; $i++) { while (count($buckets[$i]) > 0) { $numbers[$k++] = array_shift($buckets[$i]); } } }
如何实现一个通用的、高性能的排序函数?
快速排序比较适合来实现排序函数,如何优化快速排序?最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多。为了提高排序算法的性能,要尽可能地让每次分区都比较平均。
- 1. 三数取中法
①从区间的首、中、尾分别取一个数,然后比较大小,取中间值作为分区点。
②如果要排序的数组比较大,那“三数取中”可能就不够用了,可能要“5数取中”或者“10数取中”。
- 2.随机法:每次从要排序的区间中,随机选择一个元素作为分区点。
- 3.警惕快排的递归发生堆栈溢出,有2种解决方法,如下:
①限制递归深度,一旦递归超过了设置的阈值就停止递归。
②在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈过程,这样就没有系统栈大小的限制。
通用排序函数实现技巧
1.数据量不大时,可以采取用时间换空间的思路
2.数据量大时,优化快排分区点的选择
3.防止堆栈溢出,可以选择在堆上手动模拟调用栈解决
4.在排序区间中,当元素个数小于某个常数是,可以考虑使用O(n^2)级别的插入排序
5.用哨兵简化代码,每次排序都减少一次判断,尽可能把性能优化到极致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号