[学习笔记&教程] 信号, 集合, 多项式, 以及各种卷积性变换 (FFT,NTT,FWT,FMT)
信号, 集合, 多项式, 以及卷积性变换
写在前面的须知内容: 这篇博客主要讲的是板子以及一些理解变换本质的内容, 并没有几道例题.
卷积
理论上大家对卷积这个东西应该并不陌生了吧? 不过大家对于卷积都有什么理解?
- 多项式乘法?
- 狄利克雷卷积?
其实卷积可以统一成同一个形式:
给定两个 \(n\) 维向量 \(\vec a,\vec b\) 和一个下标运算 \(\circ\), 那么若 \(\vec c\) 满足下式:
那么称 \(\vec c\) 为 \(\vec a\) 和 $\vec b $ 的离散卷积, 简称卷积(题外话: 连续卷积是个积分的形式), 记作 \(\vec c = \vec a *_{\circ} \vec b\). 在不引起混淆的情况下可记作 \(\vec c = \vec a * \vec b\), 其中 \(*\) 称为卷积算子. (所以不要在 \(\LaTeX\) 里乱用 \(*\) ...老老实实打 \(\times\) ...)
我们将下标集合设为 \(S\), 则 \((S,\circ)\) 组成了一个代数系统, 我们称为卷积的下标系统.
常见的卷积:
- 多项式的乘积: 等价于下标系统为 \(\mathbb{Z}\) 上 (OI中其实一般是 \(\mathbb{N}\) ) 的加法运算 (这是FFT/NTT要做的事情).
- 循环卷积: 下标系统为模 \(n\) 意义下的加法. (这(大概)也是FFT/NTT要做的事情)
- 位运算卷积: 下标系统为 \(n\) 位二进制数的运算 (与, 或, 异或...) (这是FWT要做的事情)
- 子集卷积: 下标是集合, 下标运算对于两个交集非空的集合无定义, 对于两个不相交集合定义为二者的并. (这是FMT要做的事情)
- 狄利克雷卷积: 下标系统即为正整数乘法. (
这是Chaiki_Cage要做的事情)
卷积性变换
对于变换 \(T\) 以及向量(数列) \(\vec a,\vec b\) , 如果满足:
那么称变换 \(T\) 满足卷积定理, 这种性质被称为卷积性.
我们接下来要讲的 DFT, FFT, NTT, FWT, FMT, BFT, FST 都是卷积性变换, 用途就是根据上式将卷积转化为点积来加速卷积的计算.
傅里叶变换与信号
引入: 信号分析
讲FFT怎么能直接从多项式开始讲呢
以下内容截取自 3Blue1Brown 的视频 形象化展示傅立叶变换. 原视频超棒的! 如果有条件的话一定要看看!
首先我们先从一个看起来和OI毫不相关的(然而其实炒鸡重要的)研究课题开始.
给定一个波, 如何将它分解为若干正弦波的叠加?
或者说现在给定了一个信号, 我们要把它分解成几个频率的叠加.
(其实这就是FFT原本要做的事情)
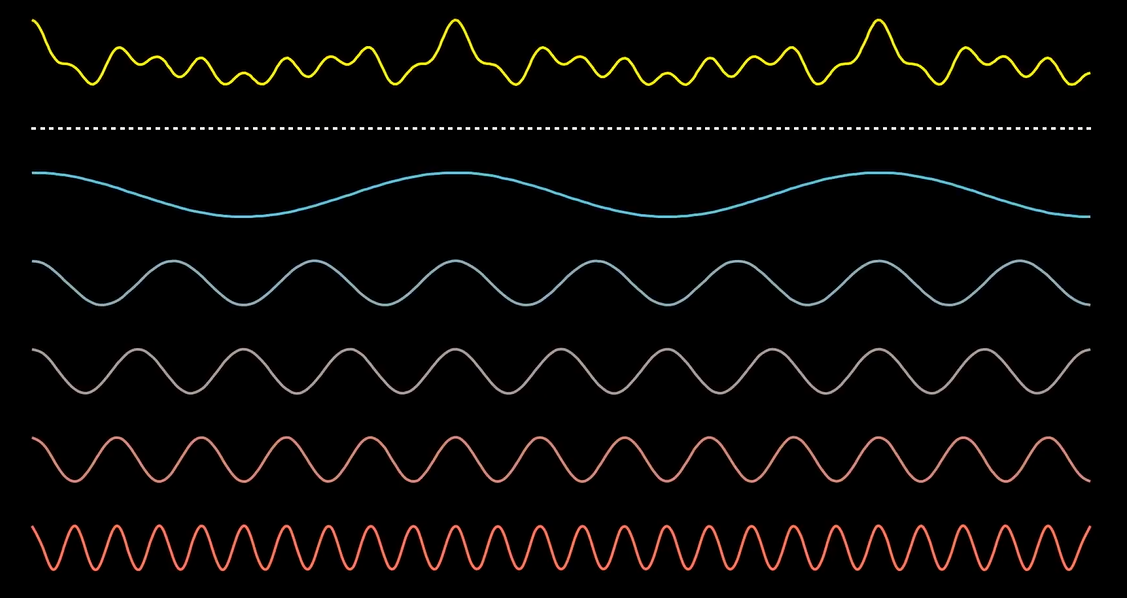
比如下面这两个信号:
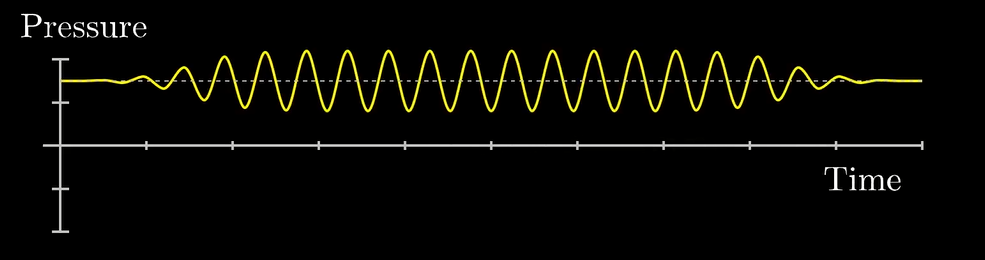
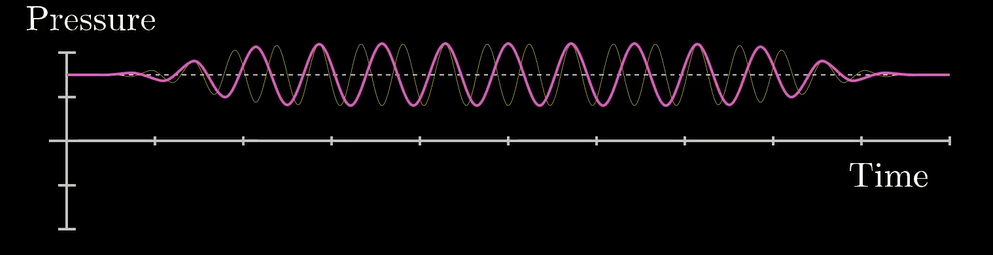
它们叠加起来就是下面这个鬼东西:
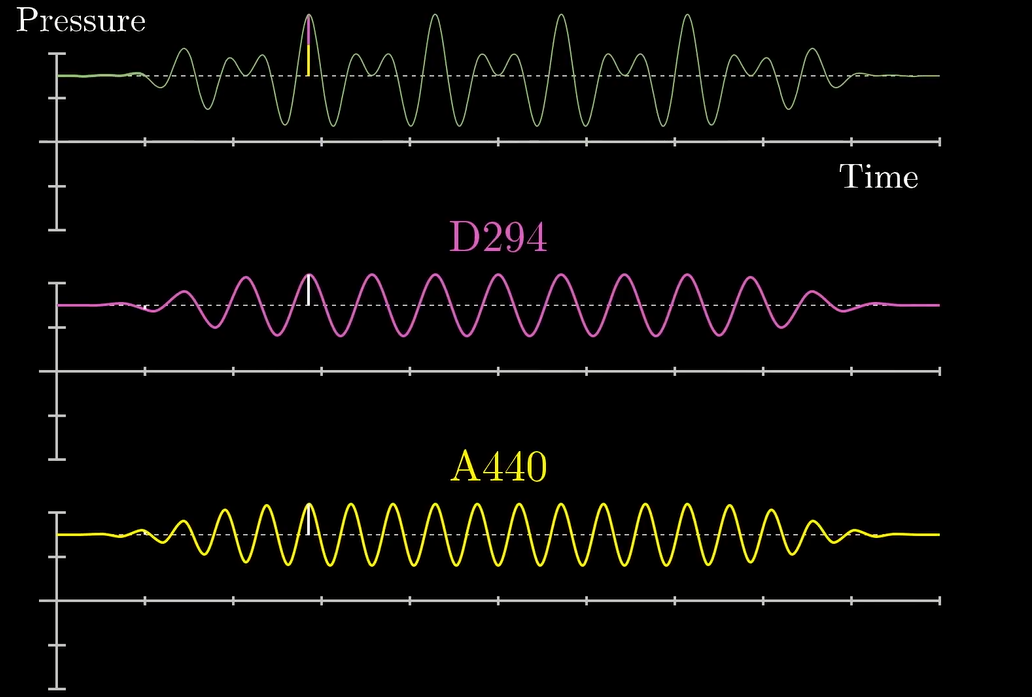
其实这两个波的情况最后叠加出来的还是能看出些许规律的. 然而如果是长这样的:
当场去世.png
按照常理, 我们肯定只能探测到最上面的那个波. 那么我们要怎么根据它来反推出它的组成成分呢?
这个时候我们需要想办法引入另一个频率, 并且让这个波在特定组分频率下能体现出不同.
怎么体现频率?
要频率, 就得有周期.
怎么要周期? 循环?
对!
让这个信号转圈圈!
比如对于下面这个 3bps 的纯正弦波, 我们把它以 0.5rps 的速度卷在原点附近:
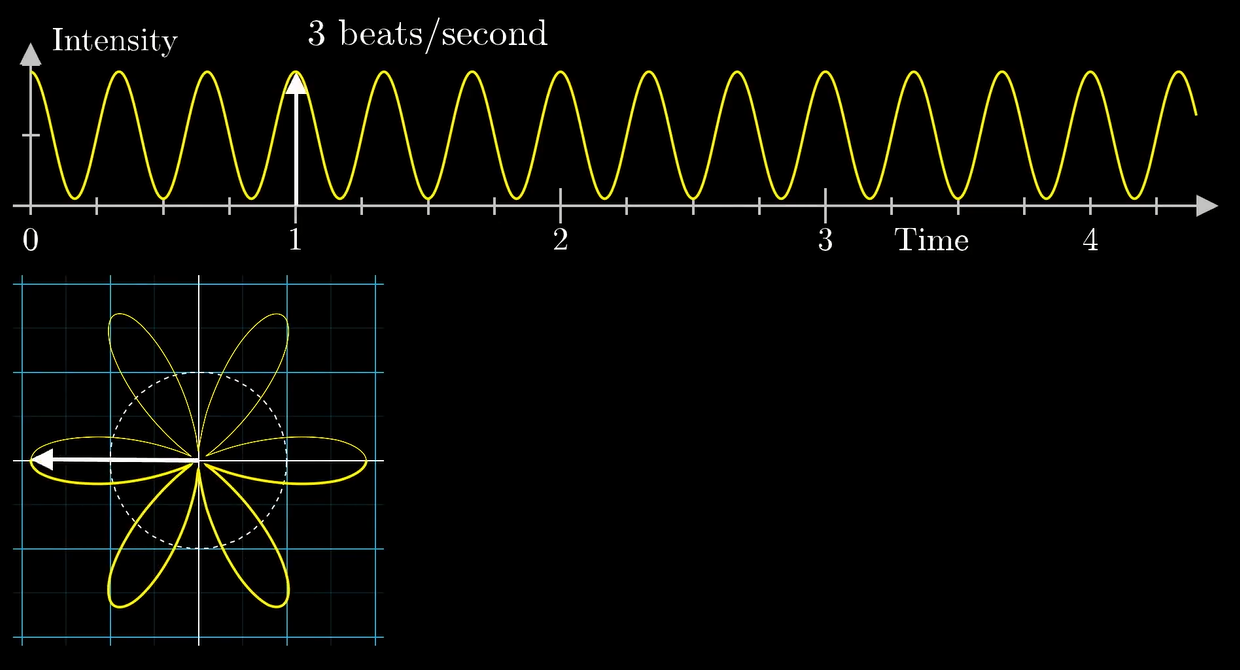
因为 3 正好是 0.5 的整倍数所以看起来好像变少了...实际上:
没错, 它真的是卷起来的...
于是我们现在完成了第一步: 引入一个频率.
第二步是想办法让这个信号在对应组分频率上表现得特别一些(不然我们怎么知道当前频率是不是这个信号的一个组分)
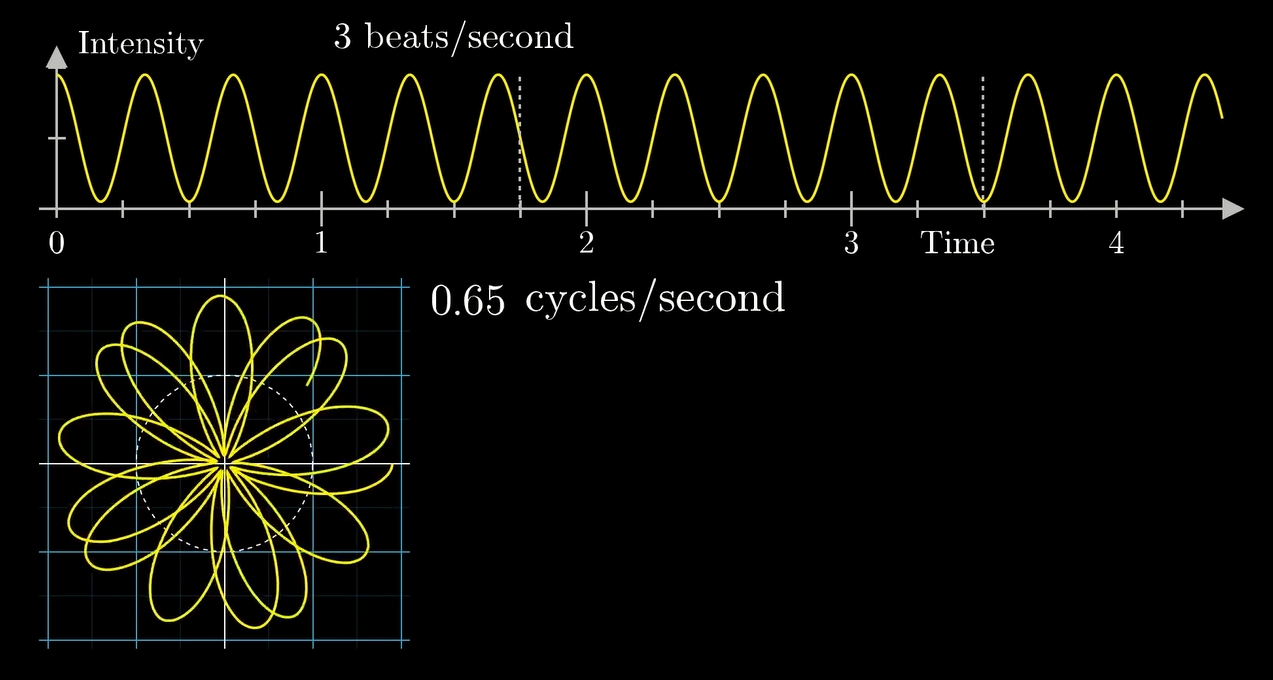
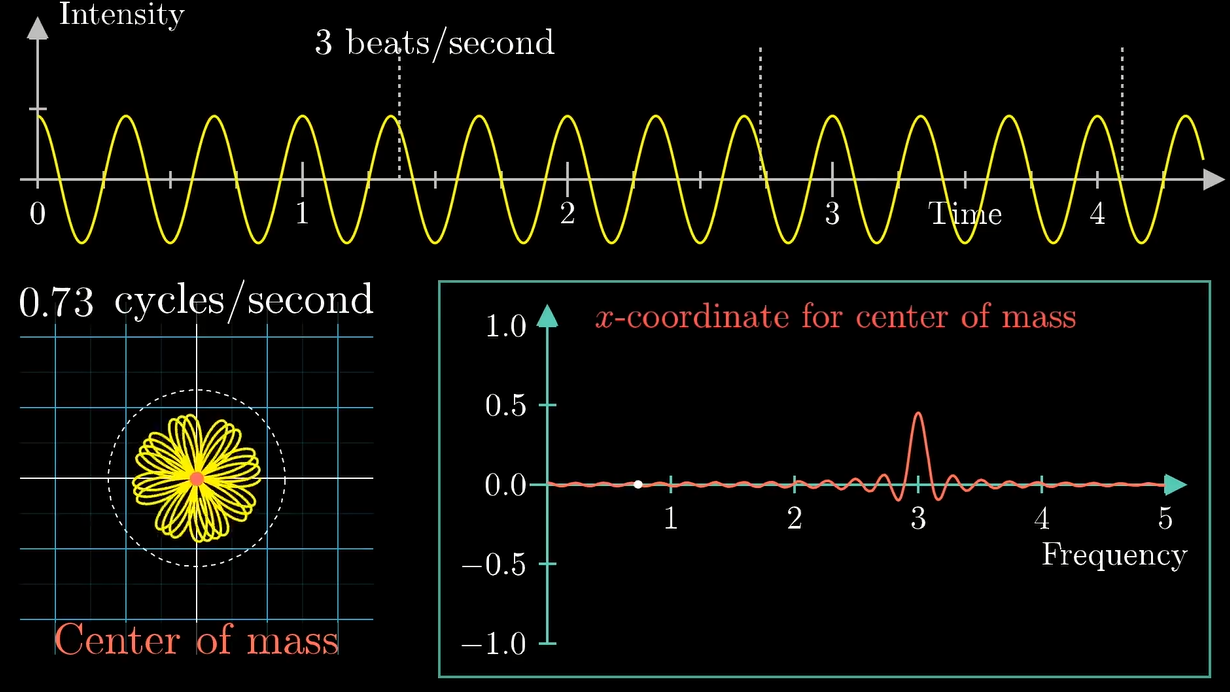
我们首先看看如果转圈的频率和信号组分频率一样会发生什么:
额密密麻麻...
它现在有啥特征?
之前缠绕频率和组分频率不同的时候信号在相对原点的各个方向上分布得比较均匀, 而现在这个图像明显要偏向右侧.
为啥?
你看当缠绕频率和组分频率一致的时候, 我们每次转完一圈的, 波峰和波谷都在同一条穿过原点的直线上. 当然他们要整个偏向右侧啦
那么我们怎么表示这个特征?
我们先用通俗一点的概念来表示它: 重心!
想象这个波是些有质量的东西 (比如铁丝), 然后我们就可以用重心距离原点的距离来度量整个波卷起来之后偏离中心的程度.
当缠绕频率和组分频率不同的时候:
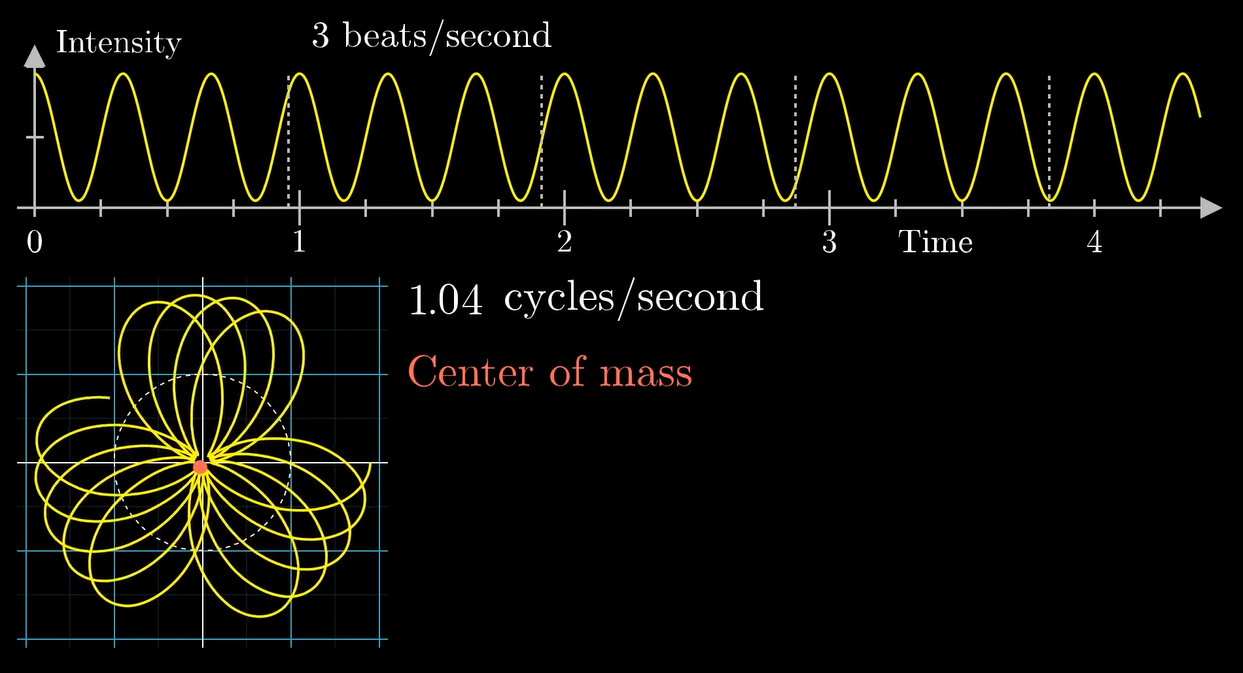
可以看到重心距离原点很近.
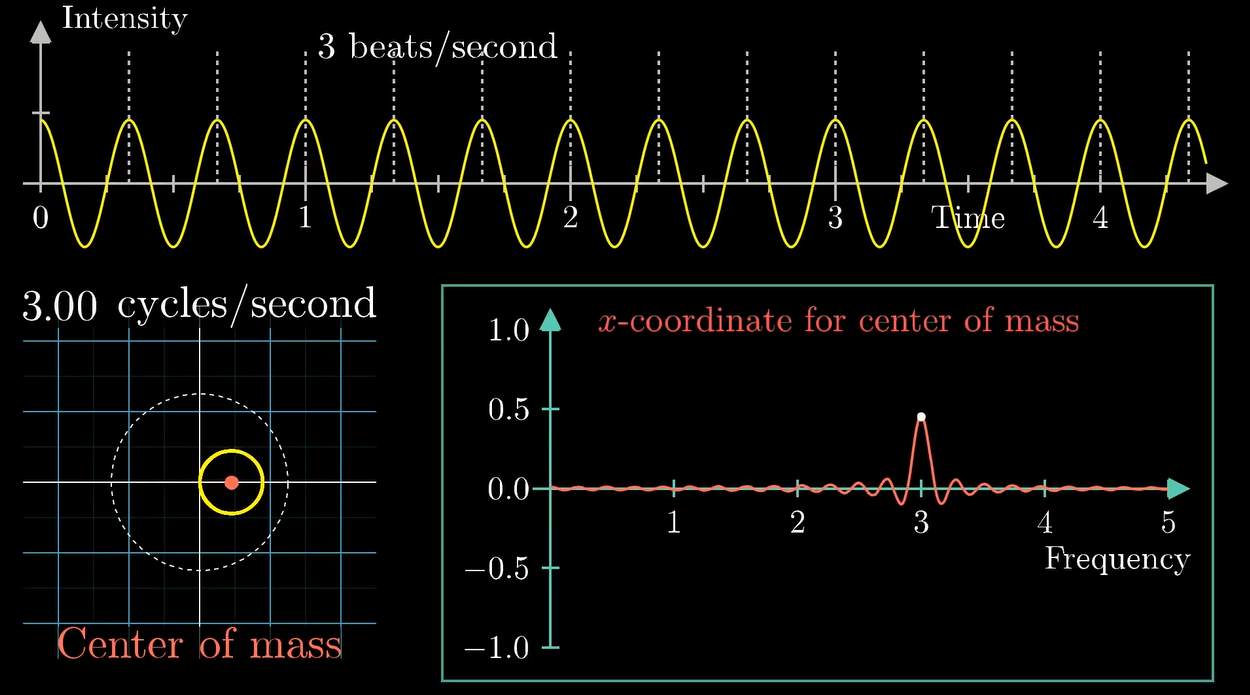
当缠绕频率和组分频率相同 (或者接近) 的时候:
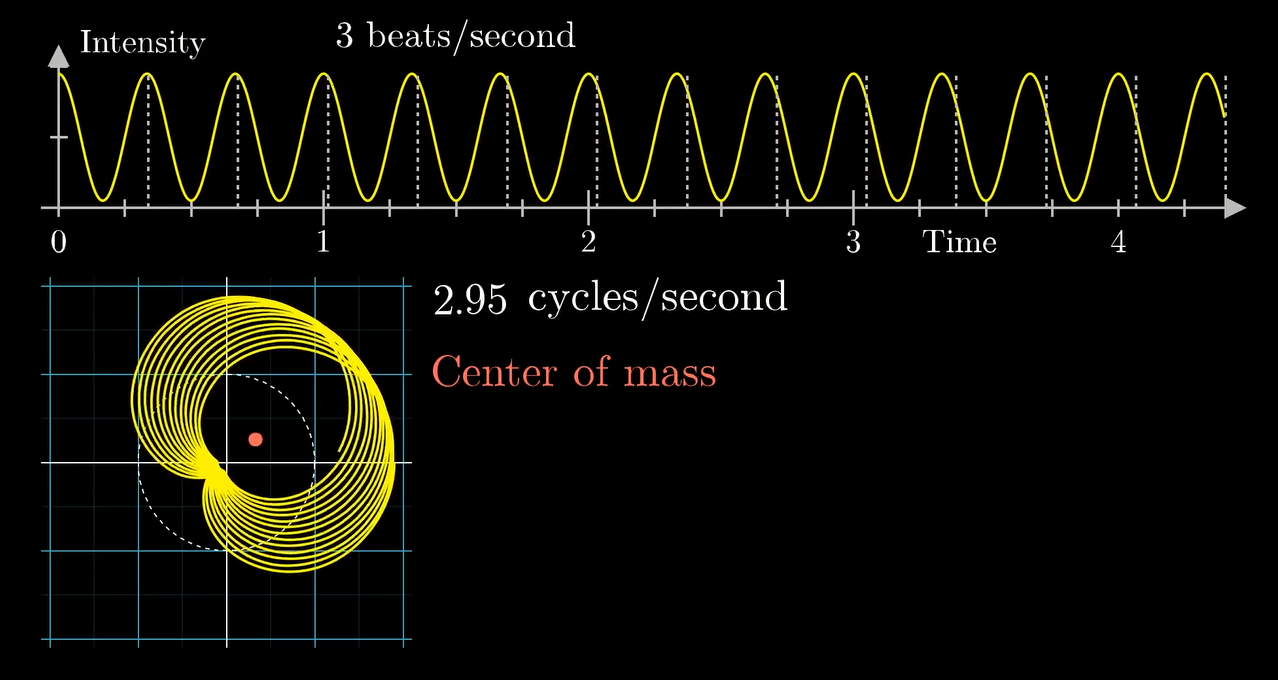
重心就距离原点比较远.
或者说, 这个缠绕的过程可以想办法把波峰和波谷的影响在一条固定的直线上叠加 (波峰最大, 放在正方向上; 波谷最小, 放在负方向上, 于是影响叠加).
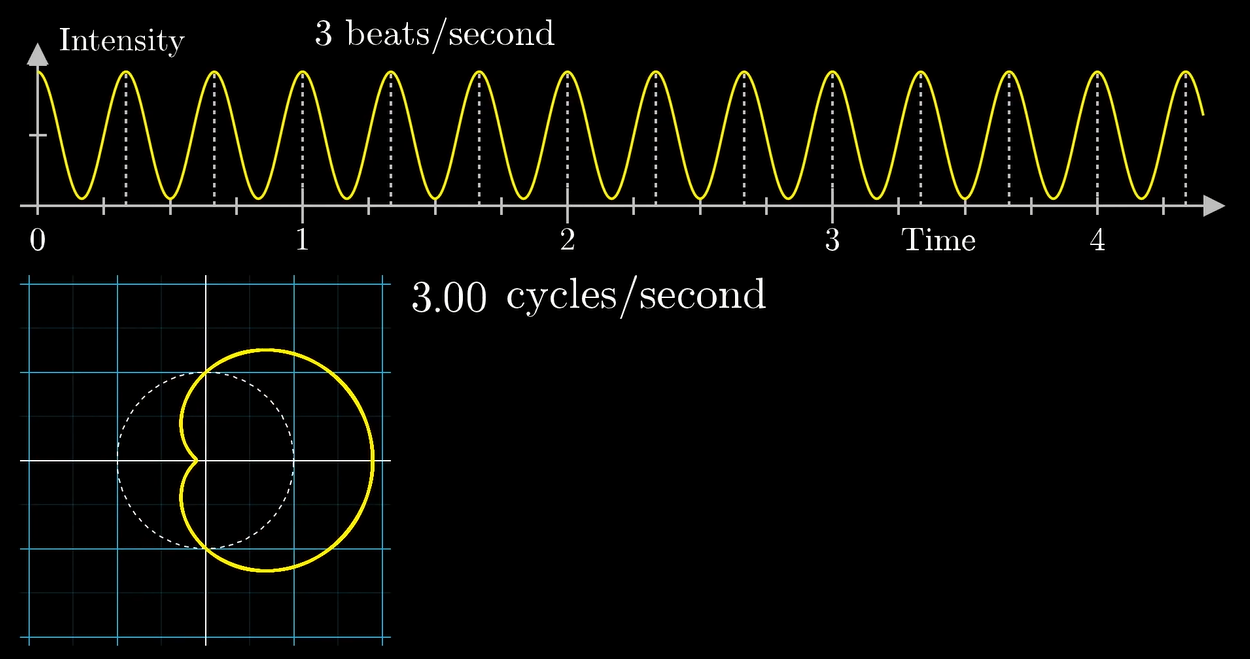
于是我们可以尝试用这个原理来对这个纯正弦波分解一下:
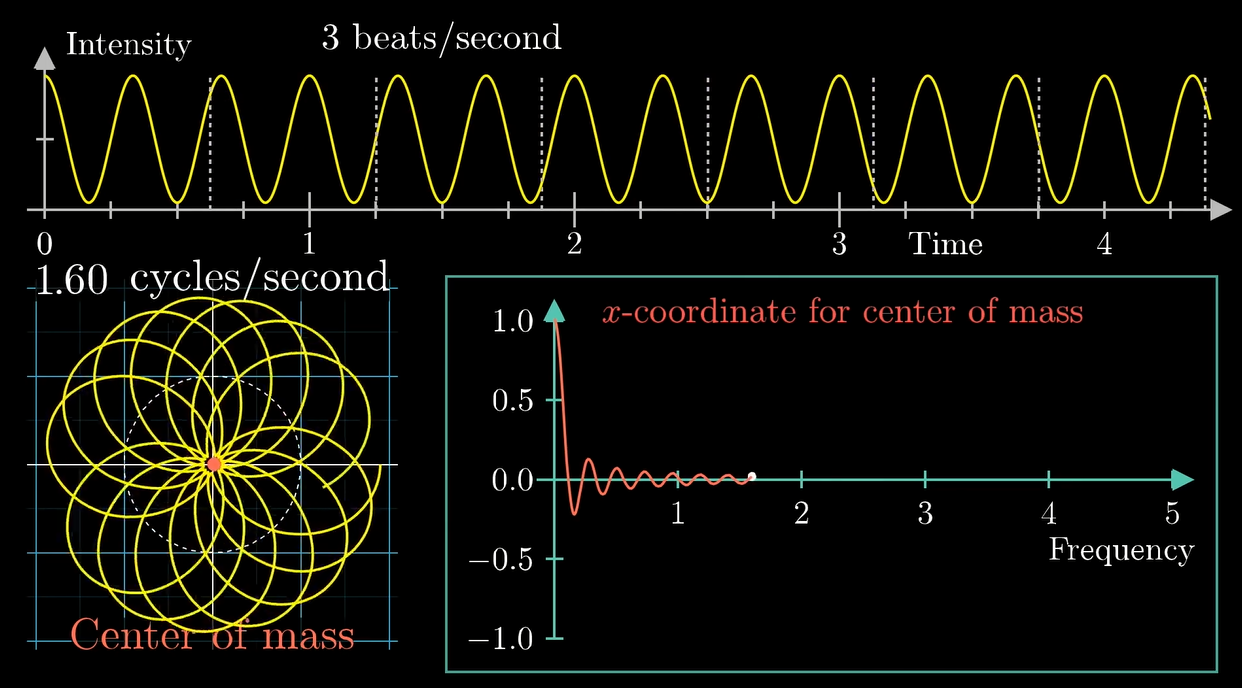
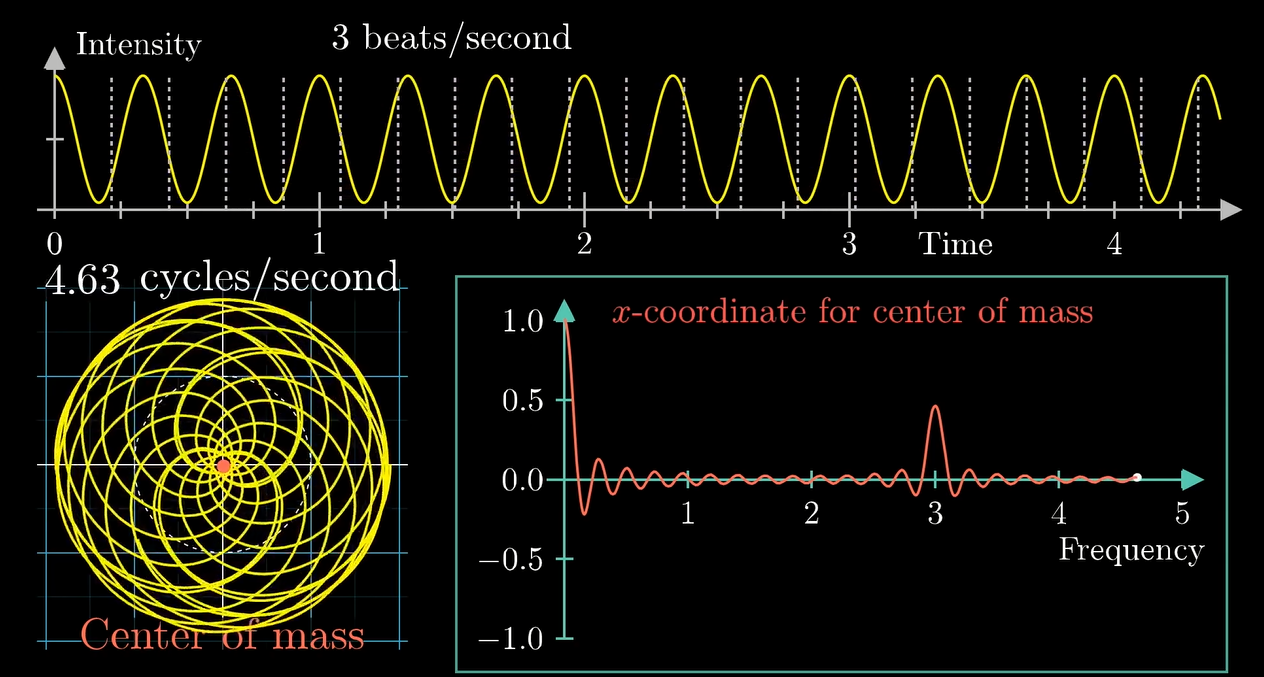
左下角的图中横坐标是缠绕频率, 纵坐标是重心的 \(x\) 坐标值.
可以看到在组分频率 \(3\) 那里产生了一个峰.
等等为啥 \(0\) 那里也有个大峰?
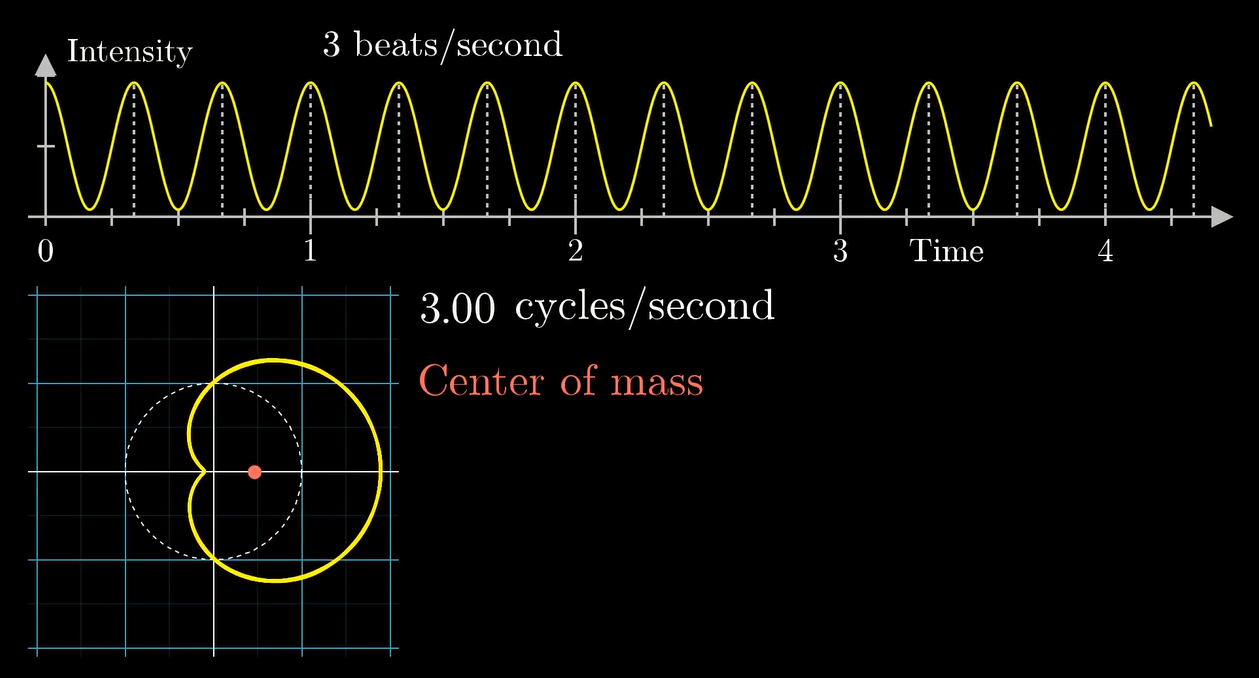
其实上面那个波并不是 "纯正弦波". 真正的纯正弦波应该是长这样的:
这样的话缠一缠就会变成这样:
(缠出来其实就是个圆, 因为波谷是负的)
显然我们只用单一组分的纯正弦波是无法体现出 "分解" 频率的过程的. 于是我们拿下面两个波的叠加来试验一下
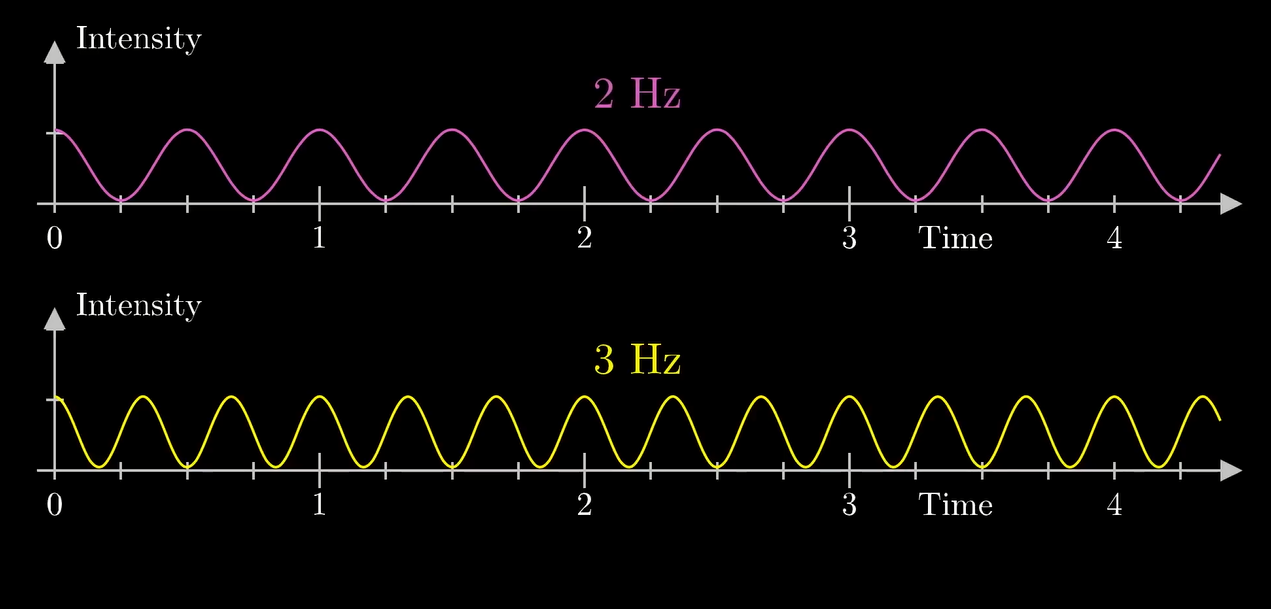
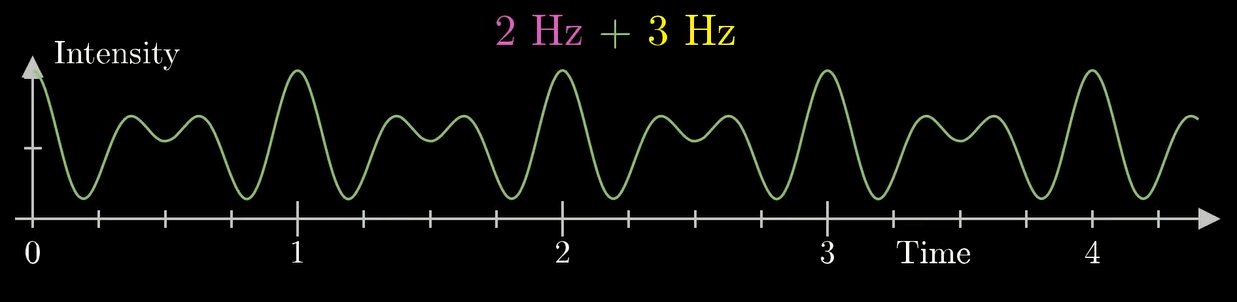
我们把它卷卷卷...
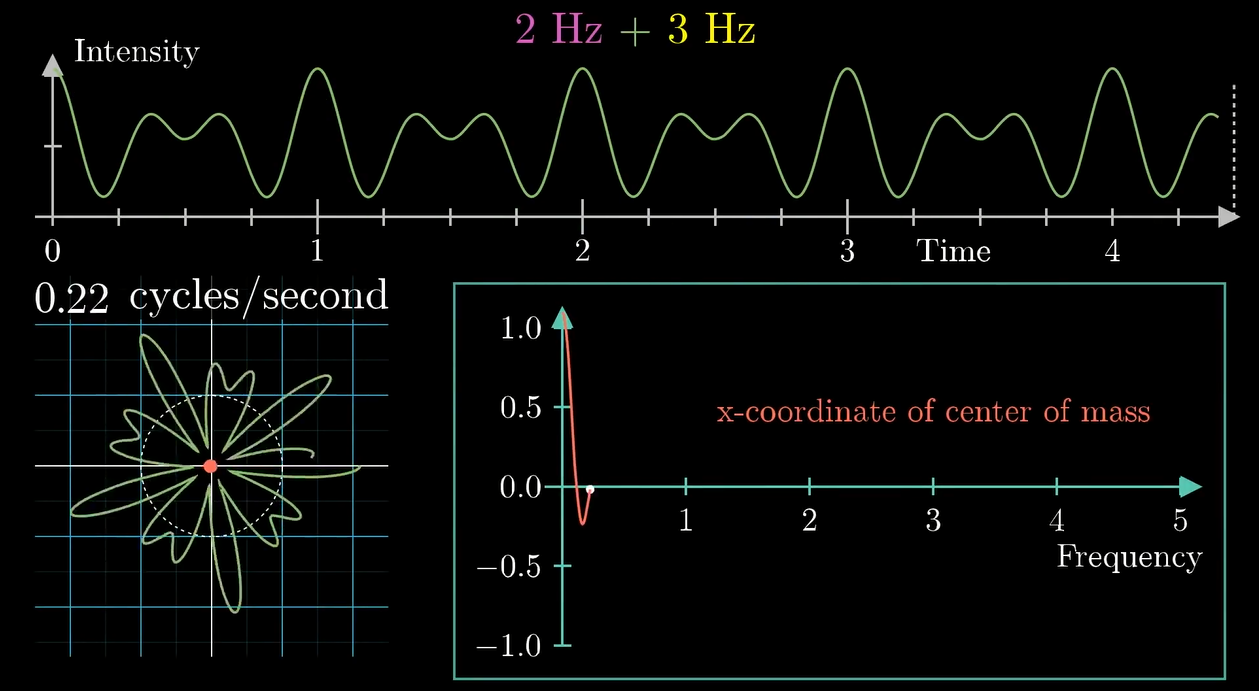
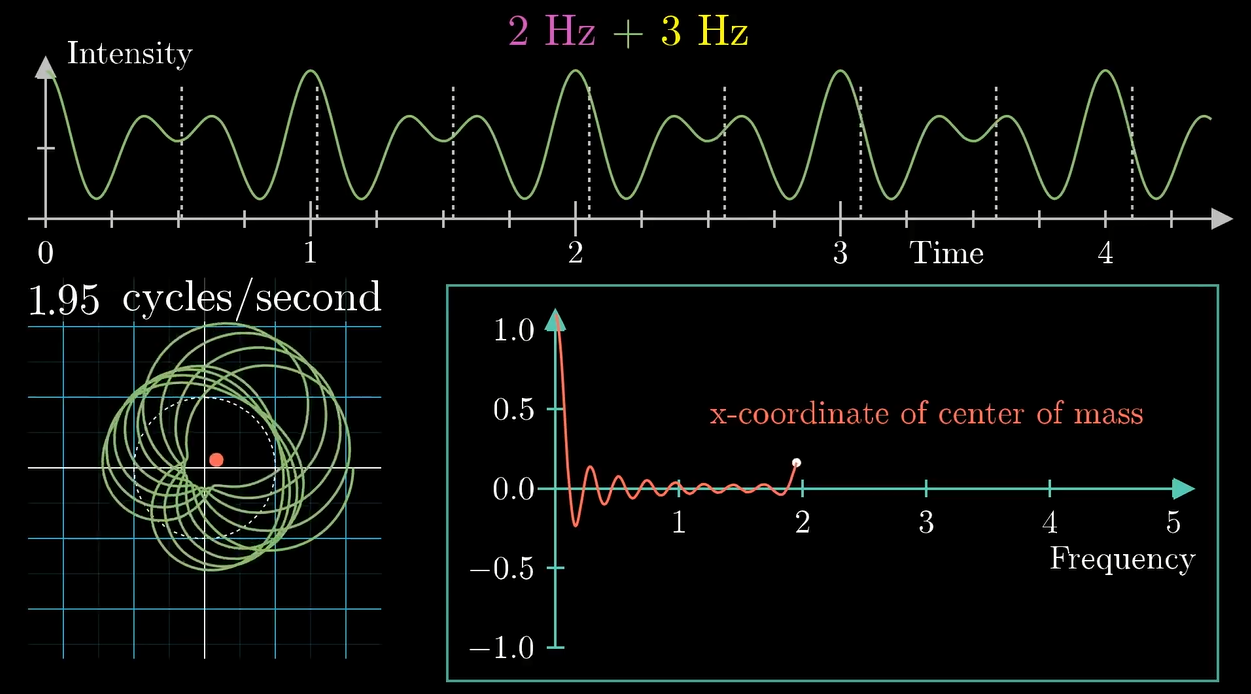
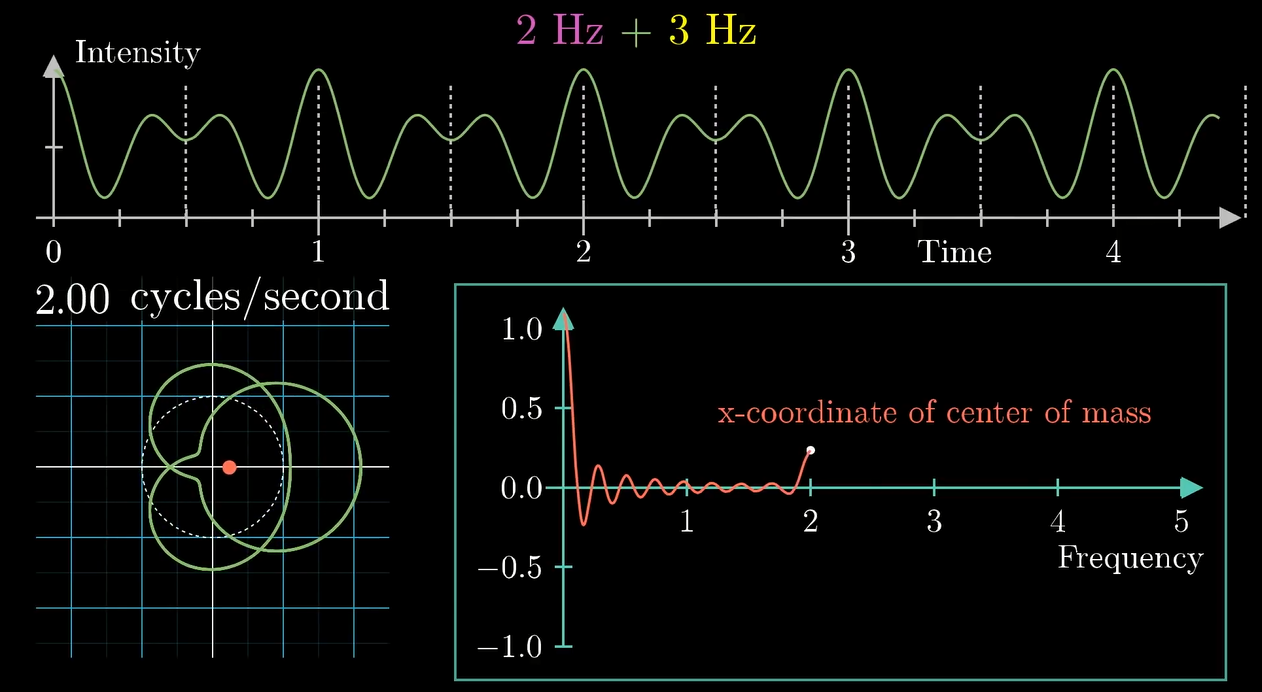
组分 \(2\texttt{Hz}\) 的波峰和波谷产生的贡献叠加了, 在最终的图像中产生了一个峰. 我们继续缠:
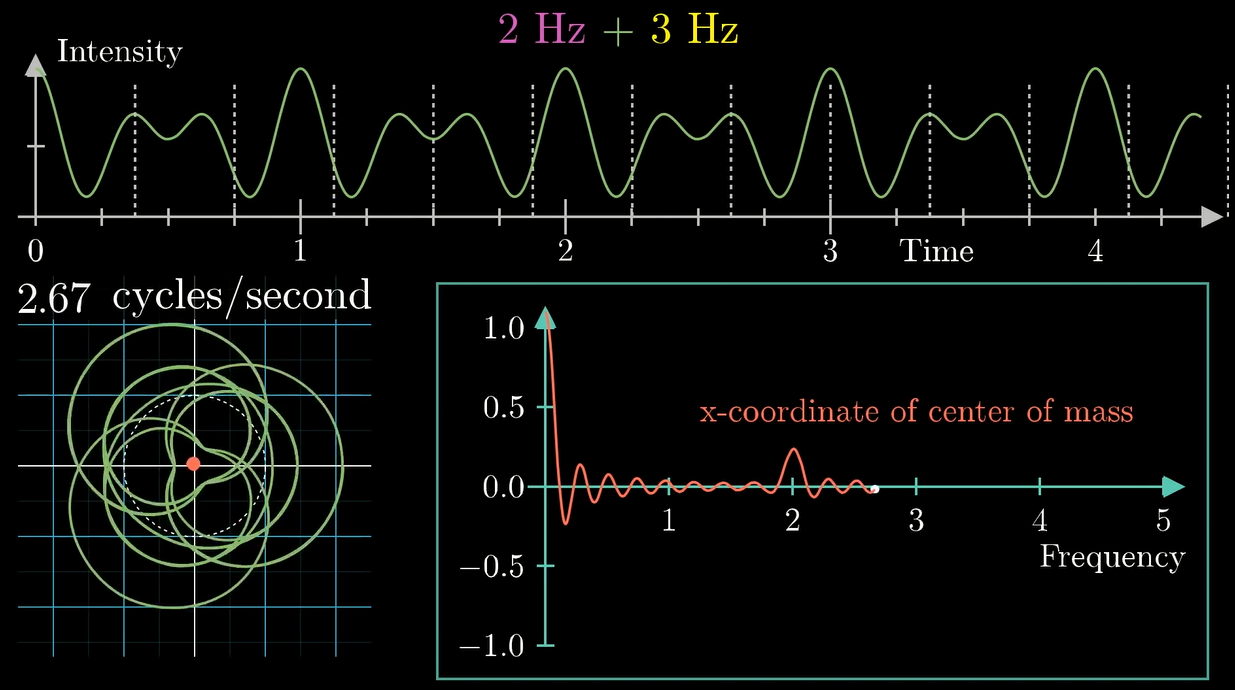
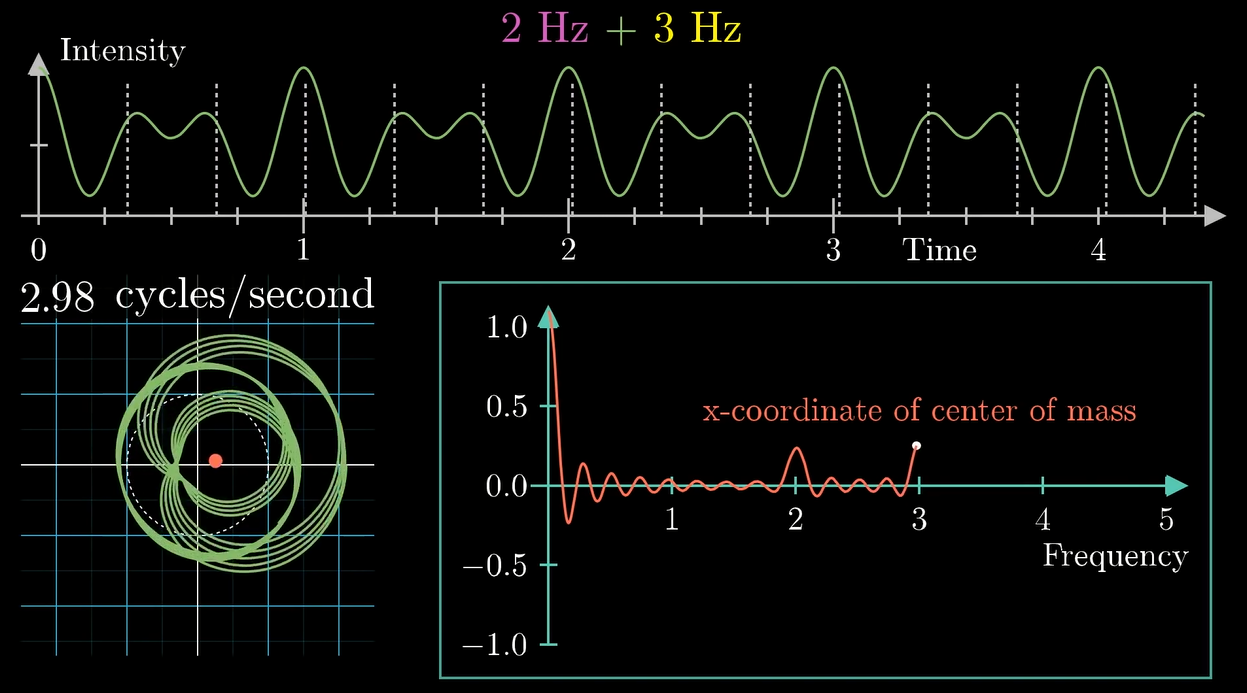
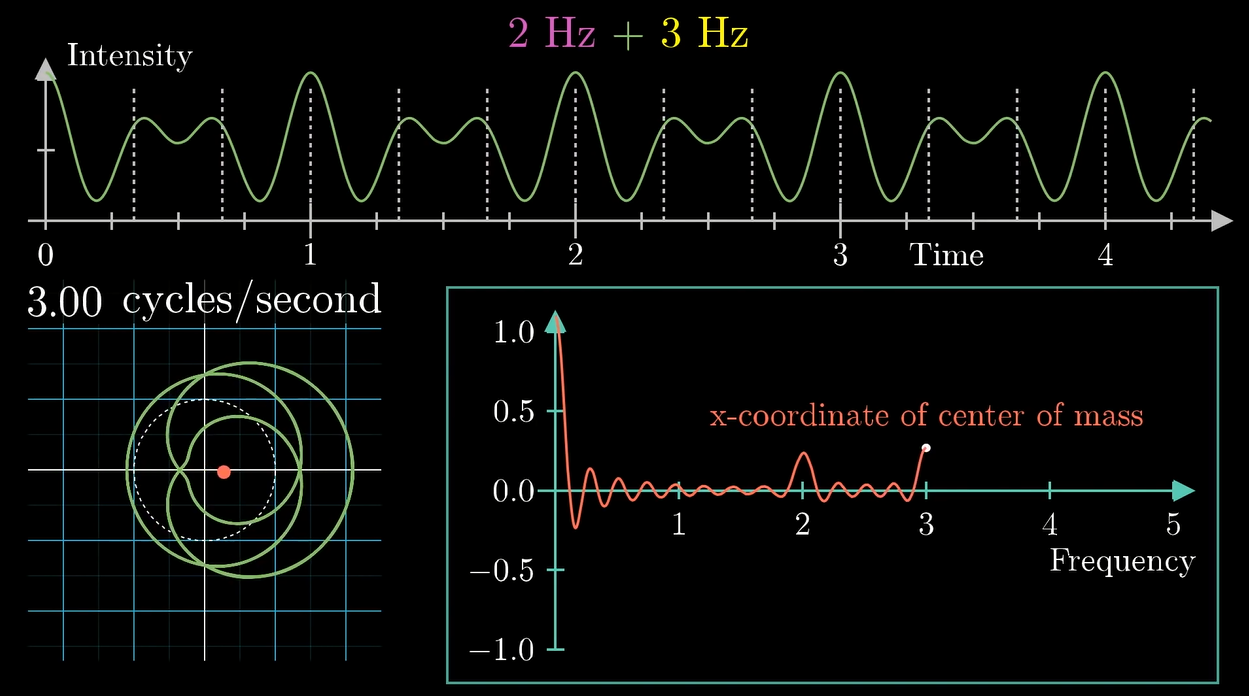
实际上我们发现, 把波叠加的同时, 最终产生的变换图像也会叠加 (显然它们在对应的点上都是算术相加的关系对吧)
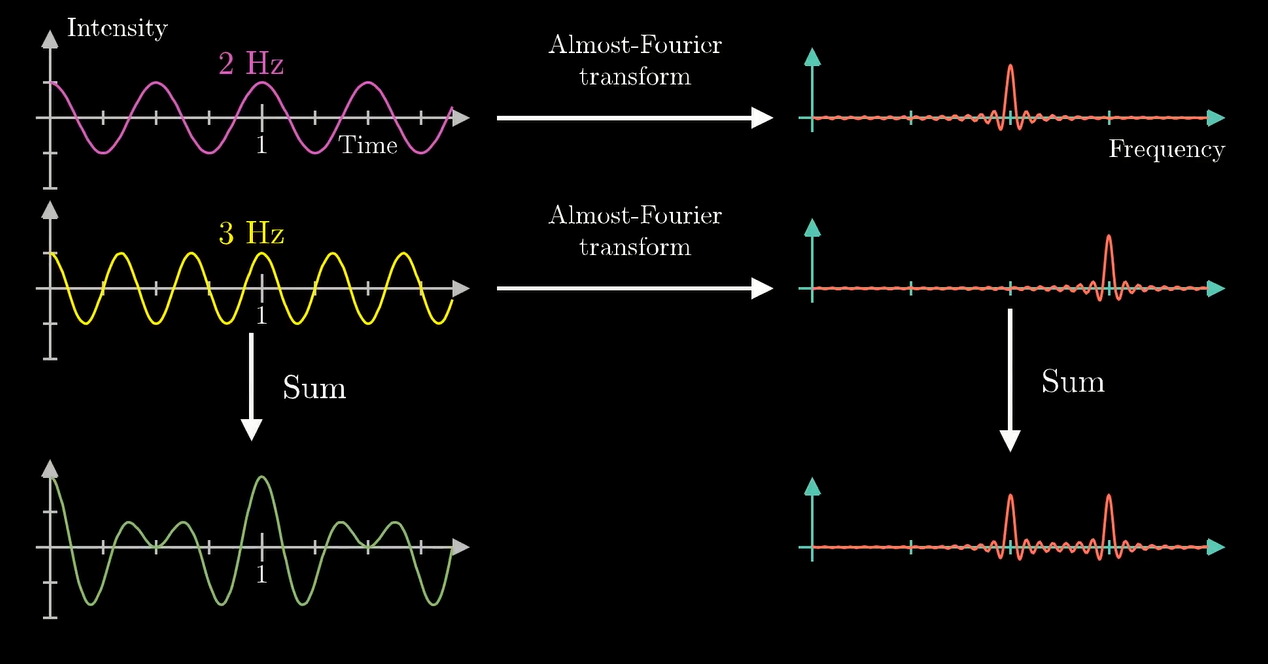
仔细想一想这个地方.
那么我们怎么在数学上实现这个频率分解过程呢?
首先我们讲一下怎么让信号转圈圈
变换的基础: 复数
以下是高考内容, 请掉线的同学立即尝试重连(怎么可能掉线)
最开始引入复数是为了解决这种东西:
显然它在实数范围内无解对吧
那么我们强行让它有解
怎么强行让它有解呢?
定义一个呗
于是 \(i\) 的定义就是这样的:
\(i\) 被称为虚数单位. 因为在创造它的时候认为它是个在自然界里没卵用的假数, 所以叫虚数.
(实际上物理里交流电分析里要用虚数的. 而且有一部分本来能做功的能量还会被虚部吃掉(变焦耳热了))
然而只有虚数还不行, 我们可能还得有实数部分, 于是我们把它们复合起来的复杂的东西叫做复数(complex number).
任意一个复数都可以表示为 \(a+bi\) 的形式 (\(a,b\in \mathbb{R}\)). (全体复数集定义为 \(\mathbb{C}\)).
其中 \(a\) 为复数 \(a+bi\) 的实部, \(b\) 为复数 \(a+bi\) 的虚部.
复数的普通运算
首先是简单一点的, 复数加减法:
复数乘法按照定义的话应该是长这样的:
然而实际上它还有一种解释方式.
我们引入一个坐标系, 横坐标为复数的实部, 纵坐标为复数的虚部, 我们称其为复平面. 那么一个复数都可以对应复平面上的一个点(或者说一个向量).
既然我们有了一个坐标系, 我们就可以接着定义一个复数的另外两个参数: 模长表示当前复数对应点到原点的距离, 幅角表示原点到当前复数所在点与 \(x\) 轴正方向的有向夹角( \([0,2\pi)\) ).
于是一个复数也可以表示为 \(r\angle\theta\) 的形式(吧)(反正卡西欧这么表示的(逃))
那么复数乘法可以定义为将两个复数的模长相乘, 幅角相加, 或者说:
为啥?
我们来证明一下:
设 \(\alpha\) 为复数 \(a+bi\) 的幅角, \(\beta\) 为复数 \(c+bi\) 的幅角, 则:
那么根据 \(\tan\) 的和角公式, 我们有:
而 \((a+bi)(c+di)\) 就等于 \((ac-bd)+(ad+bc)i\).
(其实用 \(\tan\) 来证明是不够严谨的, 因为它的周期是 \(\pi\) 而不是 \(2\pi\) ...然而 \(\sin\) 和 \(\cos\) 的式子太大懒得搞了...有兴趣自己试试吧)
模长相乘非常好搞, 直接就出来了
复数的高端运算
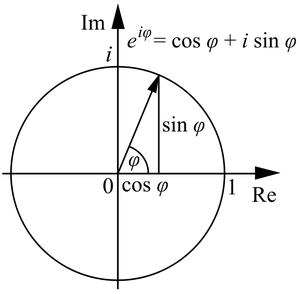
下面有请宇宙第一装B公式:
这个公式其实是Taylor展开搞出来的, 实际上更广义的公式是长这样的:
当 \(\varphi\) 取 \(\pi\) 的时候就是欧拉公式辣 (815班旗上的元素之一)
也就是下面这个图:
泰勒展开的具体式子就不放了...放了大概也没卵用...
有了上面的运算法则, 我们就可以定义傅里叶变换了
傅里叶变换
我们刚刚搞出了 \(e^{i\varphi}=\cos\varphi+i\sin\varphi=1\angle\varphi\) 这个式子, 然后又知道根据复数运算法则, 复数相乘时模长相乘幅角相加, 那么一个复数乘以 \(e^{i\varphi}\) 其实就相当于在复平面上旋转了 \(\varphi\) 的角度.
这就是转圈圈的数学实现了!
假设这个波形是函数 \(g\), 我们只要计算 \(F(x)=g(x)e^{ikx}\) 的图像的重心就可以了!
其中 \(k\) 作为系数决定缠绕速度. 为了让它和频率直接相关, 我们改造一下就星了:
其中 \(f\) 是当前频率.
不过这个鬼东西是逆时针缠绕的, 我们认为这不是很清真(其实是因为相位的关系), 于是我们把它换成顺时针:
至于重心, 我们可以考虑"采样". 在缠绕的图像上选取若干个点代数相加
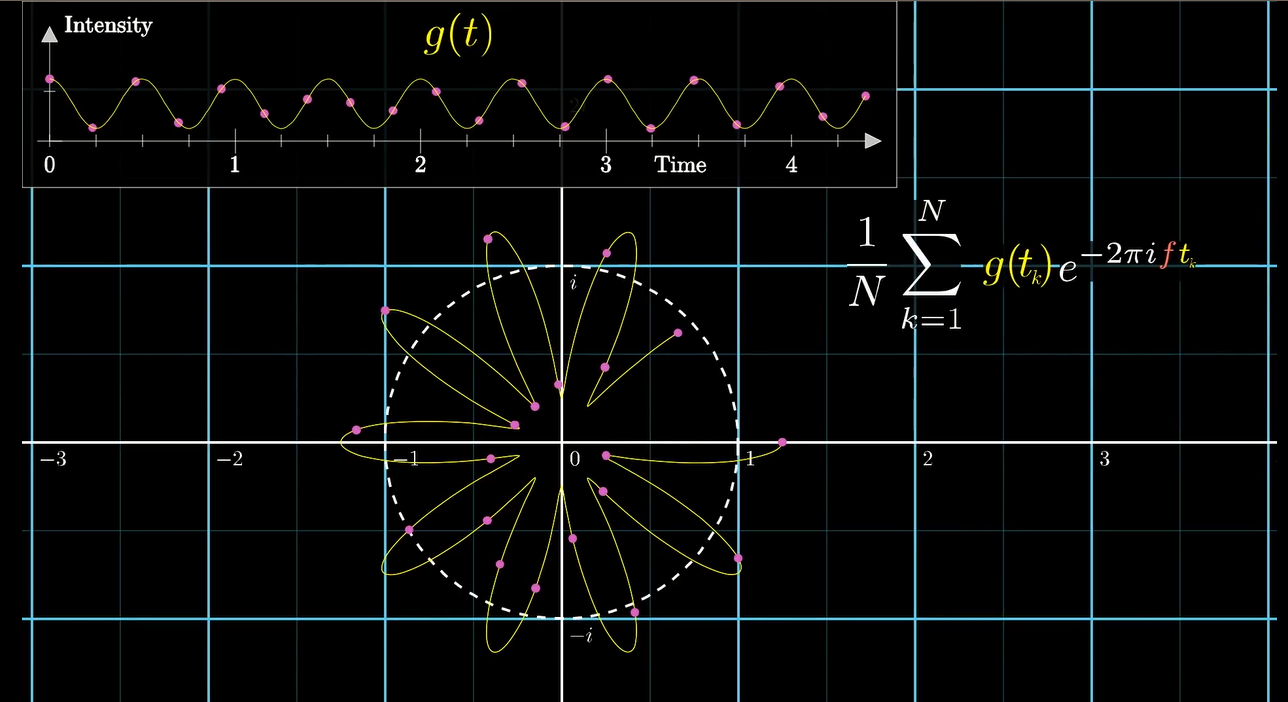
其中 \(N\) 就是采样点的个数, 我们将它取个平均值就是重心位置了.
当我们采样点越来越多的时候:
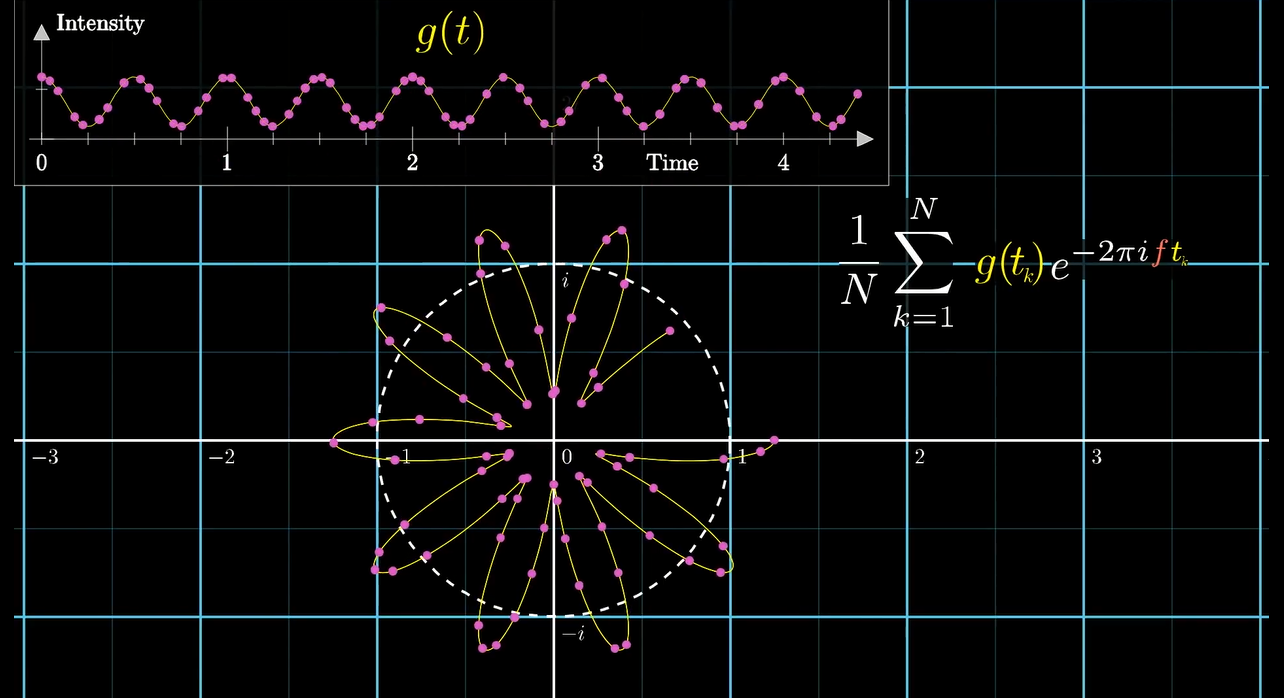
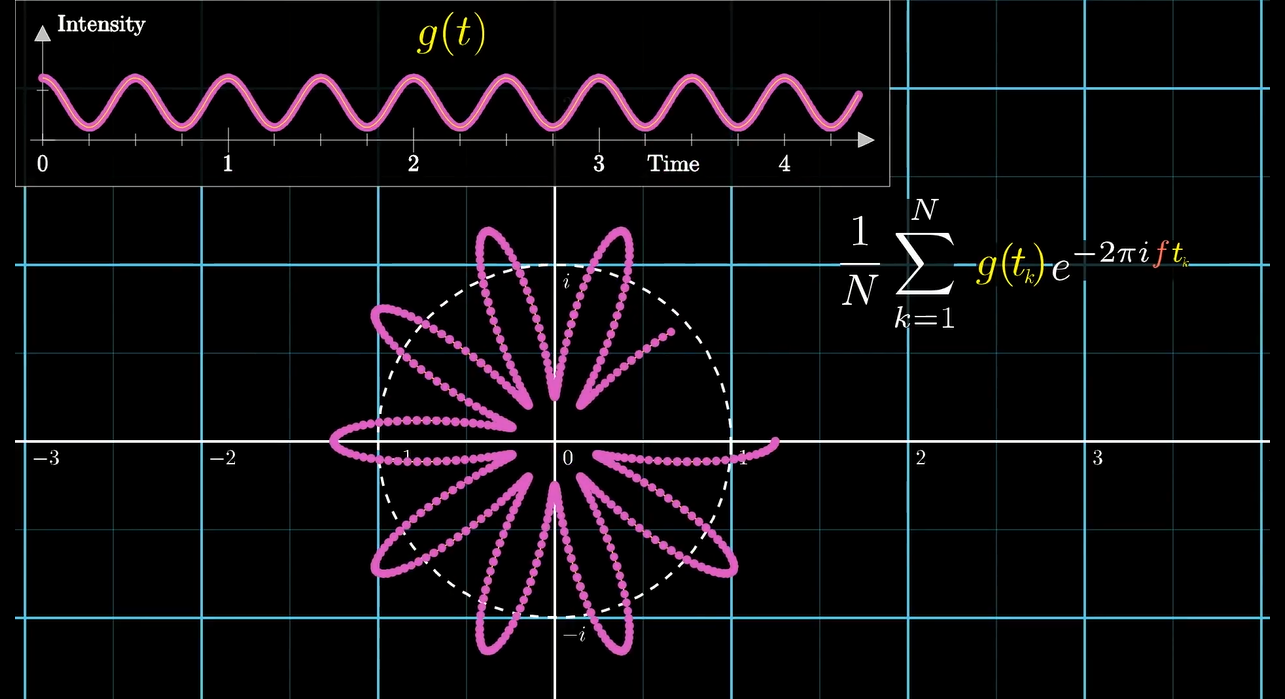
我们便可以用微分的思想, 直接把它积出来
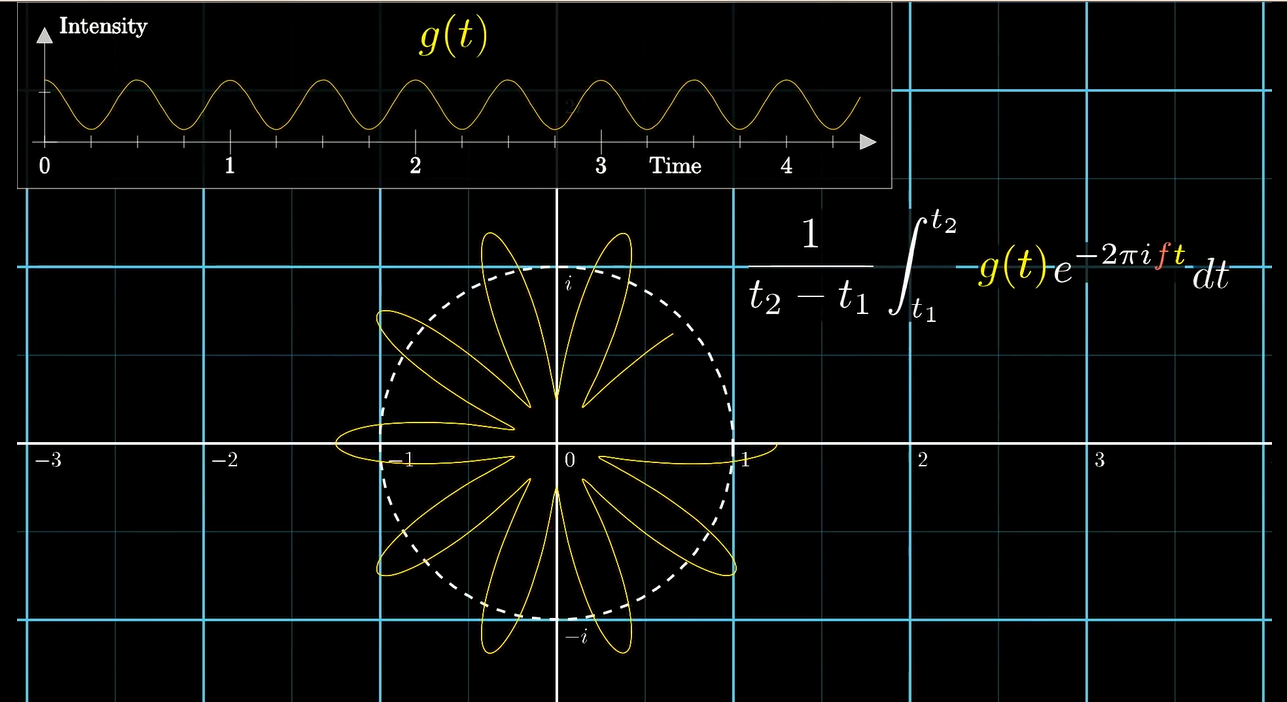
于是我们就得到了一个假傅里叶变换的表达式
为啥是假傅里叶变换呢?
真傅里叶变换是长这样的
从物理意义上讲, 当一个信号持续的时间越长, 你便越能确定这个信号的频率. 不知道大家有没有这样的经历: 当你在等红灯的时候, 碰巧看见两辆车的转向灯好像是同步的. 然而等了一会之后, 它们又变得不同步了. 于是我们将前面的求平均值部分舍弃, 来表达我们对这个成分频率的确定程度.
比如当信号很长的时候:
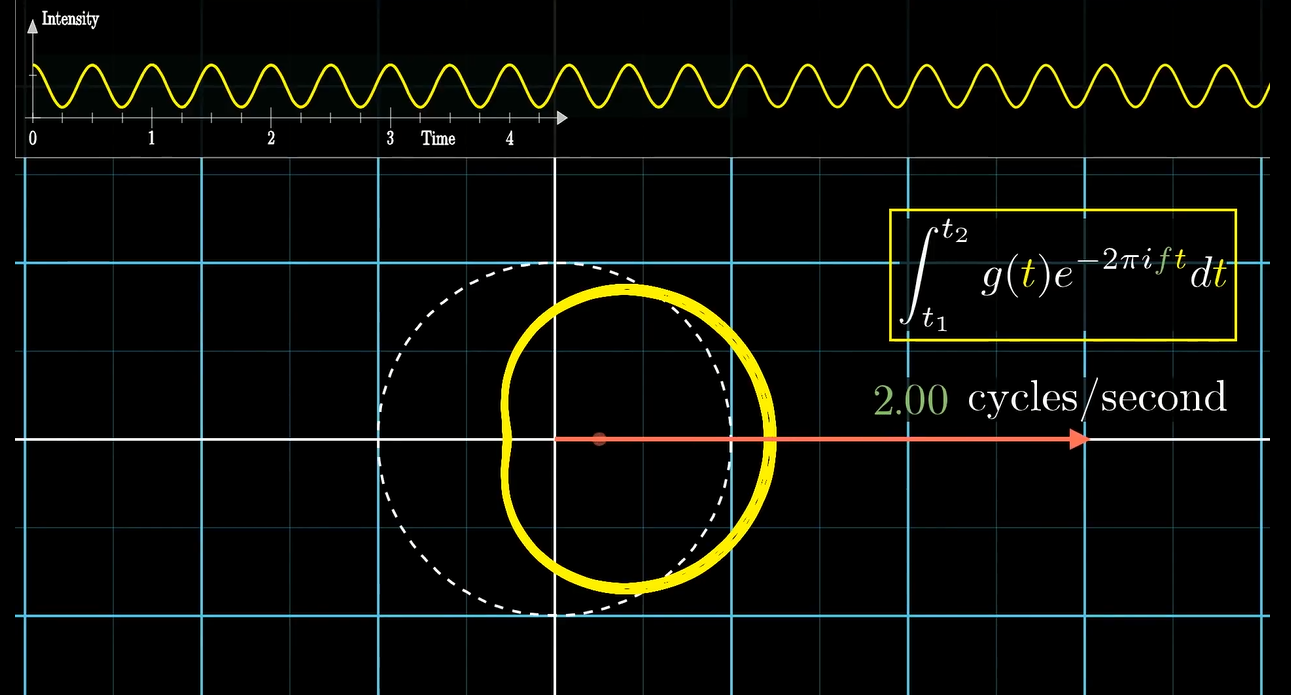
当我们缠绕的频率稍有偏差, 就会产生这样的效果:
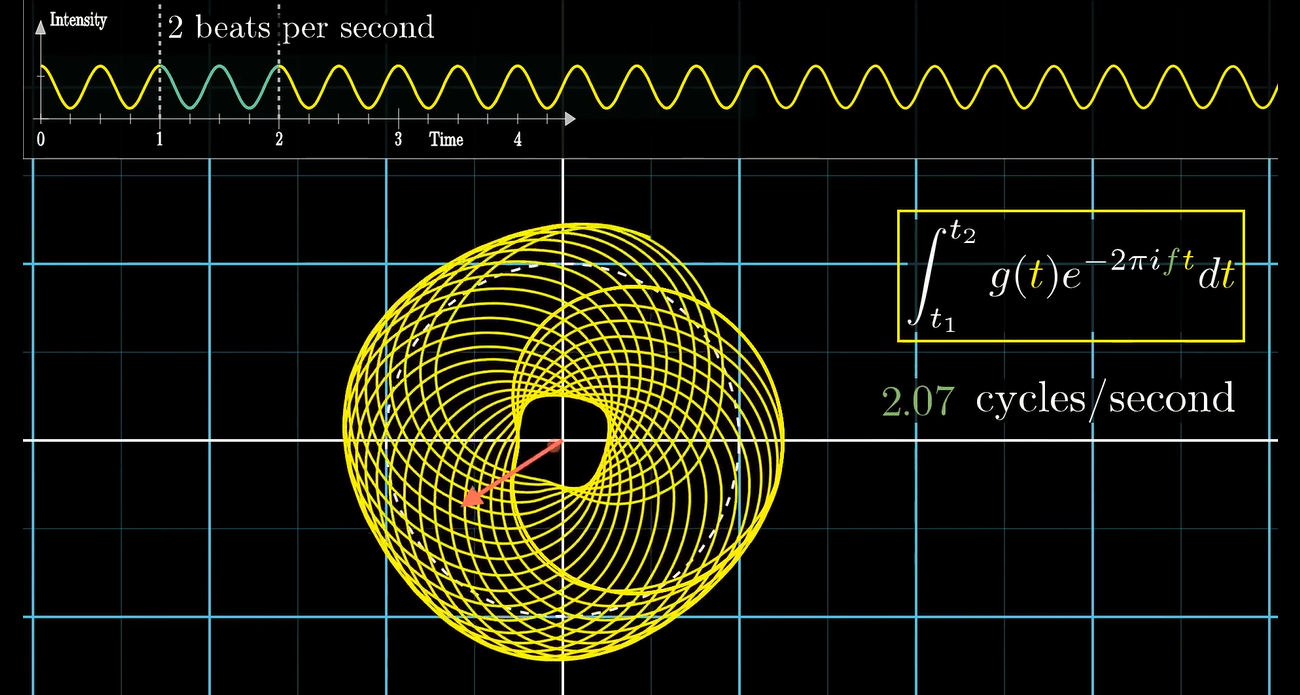
可以看到, 波形非常迅速地比较均匀地分布在了原点周围, 这会让我们的变换波形上出现一个尖锐的峰.
然而这个东西的缺陷在于什么呢?
它处理的是连续信号. 也就是说你得有个平滑的可积的函数表达式才能让计算机处理.
可自然界哪来那么多平滑函数? 尤其是这种随机性极大的信号?
于是我们就有了...
离散傅里叶变换
显然在计算机中, 我们只能通过原波形上的一系列的点来搞事情 (因为原波形一般复杂的一匹). 这些点称为采样.
实际上WC2018课上wys说采样应该是单位冲激信号和原信号的连续卷积
于是我们 ROLLBACK 到采样点那一部分
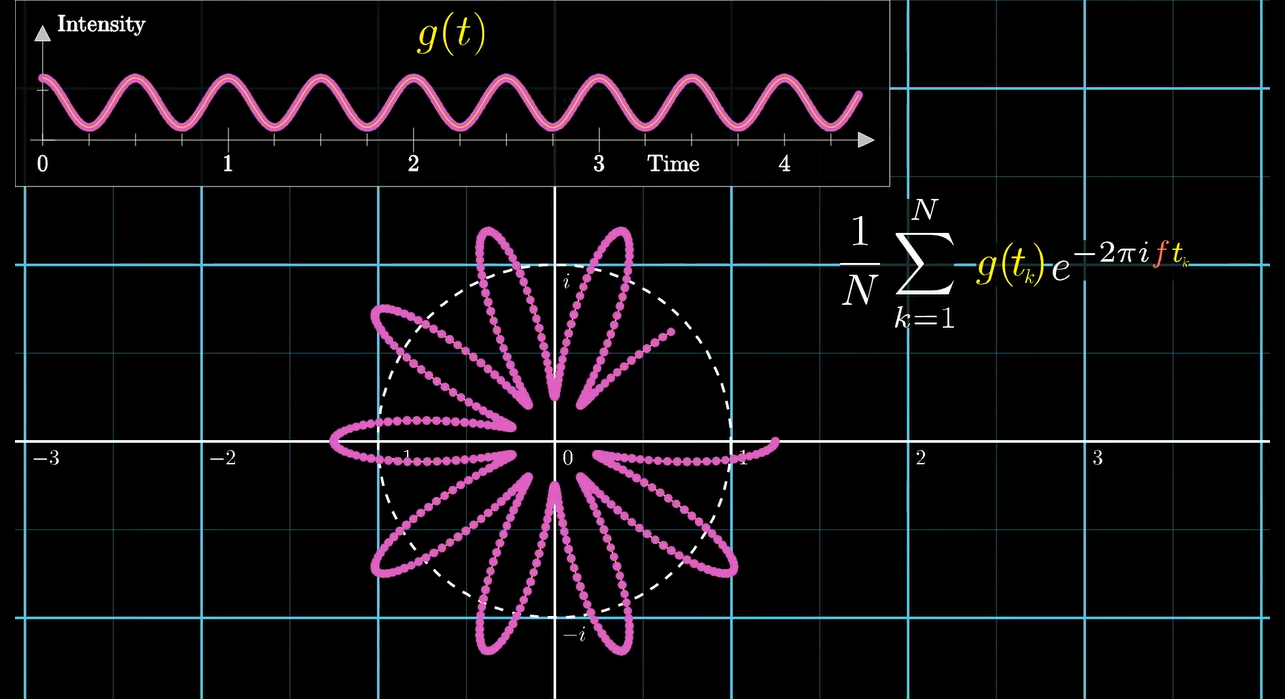
然后把前面的 \(\frac 1 N\) 去掉, 于是就得到了离散傅里叶变换(DFT)的表达式
FFT 与多项式
在上一节中我们得到了DFT的表达式, 然后我们来分(魔)析(改)一下这个式子.
首先对于一个正经的采样来说, 它的时间间隔一定是相等的. 其次对于离散傅里叶变换来说, 这个时间具体是多少其实已经没有任何卵用. 而且对于离散的采样来说, 它的旋转系数(或者每一个采样的旋转角)只有最小时间间隔的整数倍才有意义. 再加上我们可以把相位共轭一下而去掉这个式子中 \(e\) 的幂上的负号, 最后再把下标换成从 \(0\) 开始, 于是我们就可以得到下面这个式子:
等等这个 \(\omega\) 是啥玩意?
\(n\) 次单位复根
\(n\) 次单位复根是满足 \(\omega^n=1\) 的复数 \(\omega\). 根据复数乘法的集合意义以及同余, 我们可以得出: \(n\) 次单位根恰好有 \(n\) 个, 均匀分布在以原点为圆心, 半径为 \(1\) 的圆周上. 如下图所示:
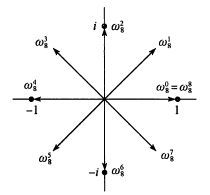
于是我们可以得到对于 \(k=0,1,\dots,n-1\), \(n\) 次单位根为 \(e^{2\pi i k / n}\).
其中 \(\omega_n=e^{2\pi i/n}\) 为主 \(n\) 次单位根.
为啥呢它是这么分布的呢?
首先我们有这样一个显然的结论:
于是我们就有了:
于是我们可以把乘法转化指数上的模 \(n\) 意义下加法, 显然任意整数 \(k\) 乘上一个 \(n\) 在模 \(n\) 意义下都是 \(0\).
其实 \(n\) 次单位根集合 \(\varOmega_n\) 和复数乘法运算组成了一个有限群 \((\varOmega_n,\times)\).
还有一个显然的事情, 就是对于一个 \(n\) 次单位根 \(\omega_n^k\), 它在极坐标系中的幅角就是 \(\frac k n\) 个周角. 因为它们均匀分布在单位圆上. 而对于分数, 我们是可以进行约分的, 这也就引出了对后续FFT十分重要的结论:
消去引理, 折半引理与求和引理
直接引用算法导论中给出的证明:
引理(消去引理): 对任意整数 $n \geq 0, k\geq 0 $, 以及 \(d\geq 0\), 有:
\[\omega_{dn}^{dk}=\omega_n^k \]证明: 由单位复数根的定义式可直接推出引理, 因为
\[\omega_{dn}^{dk}=(e^{2\pi i / dn})^{dk}=(e^{2\pi i /n})^k= \omega_n^k \]
十分优雅而精简的证明, 正是运用了单位复数根的特殊性质. 证明过程中使用了幂的幂中指数相乘的运算法则, 将 \(d\) 乘进括号内, 与括号内在指数分母上的另一个 \(d\) 相抵消.
根据消去引理, 我们还可以推出另一个引理:
引理(折半引理): 如果 \(n>0\) 为偶数, 那么 \(n\) 个 \(n\) 次单位复数根的平方的集合就是 \(n/2\) 个\(n/2\) 次单位复数根的集合.
证明: 根据消去引理, 对任意非负整数 \(k\) , 我们有 \((\omega_n^k)^2=\omega_{n/2}^k\) . 注意, 如果对所有 \(n\) 次单位复数根进行平方, 那么获得每个 \(n/2\) 次单位根正好两次. 因为:
\[(\omega_n^{k+n/2})^2=\omega_n^{2k+n}=\omega_n^{2k}\omega_n^n=\omega_n^{2k}=(\omega_n^k)^2 \]因此, \(\omega_n^{k+n/2}\) 与 \(\omega_n^k\) 平方相同.
\(\blacksquare\)
从消去引理推出的折半引理是后面FFT中使用的分治策略的正确性的关键, 因为折半引理保证了递归子问题的规模只是递归调用前的一半, 从而保证 \(O(n\log(n))\) 时间复杂度.
另一个重要的引理是求和引理, 是后文中使用FFT快速插值的基础.
引理(求和引理): 对于任意整数 \(n\geq 1\) 与不能被 \(n\) 整除的非负整数 \(k\) , 有:
\[\sum_{j=0}^{n-1}(\omega_n^k)^j=0 \]证明: 根据几何级数的求和公式:
\[\sum_{k=0}^nx^k=\frac{x^{n+1}-1}{x-1} \]我们可以得到如下推导:
\[\sum_{j=0}^{n-1}(\omega_n^k)^j=\frac{(\omega_n^k)^n-1}{\omega_n^k-1}=\frac{(\omega_n^n)^k-1}{\omega_n^k-1}=\frac{(1)^k-1}{\omega_n^k-1}=0 \]定理中要求 \(k\) 不可被 \(n\) 整除, 而仅当 \(k\) 被 \(n\) 整除时有 \(\omega_n^k=1\), 所以保证分母不为 \(0\) .
\(\blacksquare\)
重新定义
我们把 \(g(k)\) 看做一个数列, 那么它就是个数论函数它就是个向量. 那么其实后面的和式可以看做另一个函数:
而 \(f(x)\) 就成了:
而这个 \(F\) 其实就是个多项式!
而我们所做的, 其实就是求出了多项式 \(F\) 在所有的 \(n\) 次单位根上的取值!
然而求这个有啥用?
多项式的表示
多项式的系数表达
相信大家都知道对于一个次数界为 \(n\) 的多项式 \(A(x)\) 可以表示为如下形式:
这时, 多项式 \(A(x)\) 的系数所组成的向量 \(\vec{a}=(a_0,a_1,...a_{n-1})\) 是这个多项式的系数表达. (实际上是列向量不是行向量OwO)
使用系数表达来表示多项式可以进行一些方便的运算, 比如对其进行求值, 这时我们可以采用秦九昭算法来在 \(O(n)\) 时间复杂度内对多项式进行求值.
但是当我们想把两个采用系数表达的多项式乘起来的时候, 恭喜你, 问题来了: 一个多项式中的每个系数都要与另一个多项式中的每个系数相乘. 然后时间复杂度就变成了鬼畜的 \(\Theta(n^2)\) ...
也就是对于两个多项式的系数表示 \(\vec{a}\) 和 \(\vec{b}\) 来说, 两个多项式乘积的系数表达 \(\vec{c}\) 中的值的求值公式如下:
然而多项式乘法和卷积在很多地方都需要快速的实现, 而对于多项式乘法来说, 另一种表示方法似乎更为合适:
多项式的点值表达
首先我们对点值表达进行定义:
一个次数界为 \(n\) 的多项式 \(A(x)\) 的点值表达为一个由 \(n\) 个点值对所组成的集合:
\[\{(x_0,y_0),(x_1,y_1),(x_2,y_2),...,(x_{n-1},y_{n-1})\} \]使得对于 \(k=0,1,2,...,n-1\) , 所有的 \(x_k\) 各不相同
(我们可以先暂且把 \(A(x)\) 看作一个函数)
其中 \(y_k=A(x_k)\) , 也就是说选取 \(n\) 个不同的值分别代入求值之后产生 \(n\) 个值, 就会得到 \(n\) 个未知数的值与多项式值的点对. 这 \(n\) 个点对就是多项式的一个点值表达.
不难看出点值表达并不像多项式表达一样具有唯一性, 因为 \(x_k\) 是没有限制条件的.
而我们刚刚DFT中所做的, 就是求出了多项式 \(F\) 的一个点值表达. 于是我们就可以把它拿来搞事情了. 而按照定义计算出这些点值需要 \(O(n^2)\) 的时间.
....
等等...? 怎么还是 \(O(n^2)\) ? 别急, 很快我们就会发现, 如果我们像某些丧病出题人一样精心选择数据, 我们就可以在 \(O(n\log(n))\) 的时间复杂度内完成这个运算.
而从多项式的点值表达转换为唯一的系数表达就没有那么显然了. 首先我们介绍两个概念:
求值与插值
从一个多项式的系数表达确定其点值表达的过程称为求值(似乎很显然的样子? 毕竟我们求点值表达的过程就是取了 \(n\) 个 \(x\) 的值然后扔进了多项式求了 \(n\) 个值出来233), 而求值运算的逆运算(也就是从一个多项式的点值表达确定多项式的系数表达)被称为插值. 而插值多项式的唯一性定理告诉我们只有多项式的次数界等于已知的点值对的个数, 插值过程才是明确的(能得到一个确定的多项式表达) , 联想之前的矩阵与线性方程组和增广矩阵可以得到如下证明:
定理(插值多项式的唯一性): 对于任意 \(n\) 个点值对组成的集合 \(\{(x_0,y_0),(x_1,y_1),...,(x_{n-1},y_{n-1}\}\) ,且其中所有 \(x_k\) 不同, 则存在唯一的次数界为 \(n\) 的多项式 \(A(x)\) , 满足 \(y_k=A(x_k),k=0,1,...,n-1\) .
证明 证明主要是根据某个矩阵存在逆矩阵. 多项式系数表达等价于下面的矩阵方程:
\[\begin{bmatrix} 1 & x_0 & x_0^2 & \dots & x_0^{n-1} \\ 1 & x_1 & x_1^2 & \dots & x_1^{n-1} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{n-1} & x_{n-1}^2 & \dots & x_{n-1}^{n-1} \end{bmatrix} \begin{bmatrix} a_0 \\ a_1 \\ \vdots \\ a_{n-1} \end{bmatrix} = \begin{bmatrix} y_0 \\ y_1 \\ \vdots \\ y_{n-1} \end{bmatrix} \]左边的矩阵表示为 \(V(x_0,x_1,...,x_{n-1})\) , 称为范德蒙矩阵. 而这个矩阵的行列式为:
\[\prod _{0\leq j < k \leq n-1} (x_k-x_j) \]所以根据定理 "\(n\times n\) 矩阵是奇异的, 当且仅当该矩阵的行列式为 \(0\)", 如果 \(x_k\) 皆不相同, 则这个矩阵是可逆的. 因此给定点值表达 \(\vec y\) , 则能确定唯一的系数表达 \(\vec{a}\) 使:
\[\vec{a}=V(x_0,x_1,...,x_{n-1})^{-1}\vec{y} \]\(\blacksquare\)
上面的证明过程实际上也给出了插值的一种算法, 即求出范德蒙矩阵的逆矩阵. 我们可以在 \(O(n^3)\) 时间复杂度内求出逆矩阵所以相应地可以在 \(O(n^3)\) 时间复杂度内计算出点值表达所对应的系数表达.
然而这特么比求值还慢...=_=
所幸我们还有一种基于 \(n\) 个点的插值算法, 基于拉格朗日公式:
基于这个公式我们可以在 \(O(n^2)\) 时间复杂度内计算出点值表达所对应的系数表达.
然后插值勉强追上了求值的时间复杂度.
那么问题来了, 计算这个点值表达有啥用?
点值表达的运算
点值表达在很多多项式相关操作上比系数表达要方便很多, 比如对于加法, 如果 \(C(x)=A(x)+B(x)\) ,则对于任意点值 \(x_k\) , 满足 \(C(x_k)=A(x_k)+b(x_k)\) . 而正确性是显而易见的.所以对于两个点值表达的多项式进行加法操作, 时间复杂度为 \(O(n)\).
与加法类似, 多项式乘法在点值表达的情况下也变得更加方便: 如果 \(C(x)=A(x)B(x)\), 则对于任意点 \(x_k\) , \(C(x_k)=A(x_k)B(x_k)\) . 也就是说点值表达常常可以大大简化多项式间的运算!
于是这就是我们拿它来卷积的理由了.
然而现在它是 \(O(n^2)\) 的, 我们现在来优化它.
快速傅里叶变换FFT
FFT (Fast Fourier Transform)利用了 \(n\) 次单位根的特殊性质, 让我们可以在 \(O(n\log n)\) 的时间内计算出DFT.
我们下面统一这样定义DFT:
对于 \(A\) 的系数表达 \(\vec{a}= (a_0,a_1,...,a_{n-1})\) 和 \(k=0,1,...,n-1\) , 定义结果 \(y_k\):
则 \(\vec{y}=(y_0,y_1,...,y_{n-1})\) 就是系数向量 \(\vec{a}\) 的离散傅里叶变换(DFT). 简记为 \(\vec{y}=DFT_n(\vec{a})\)
在下文中我们为了分治方便, 统一认为 \(n\) 是 \(2\) 的整次幂. 虽然对于非整次幂的 \(n\) 的算法已经出现, 但是平常 OI 中使用的时候一般采取补一大坨值为 \(0\) 的高次项系数强行补到 \(2\) 的整次幂23333
FFT使用的是分治策略. 根据系数下标的奇偶来拆分子问题, 将这些系数分配到两个次数界为 \(n/2\) 的多项式 \(A^{[0]}(x)\) 和 \(A^{[1]}(x)\) :
可以发现 \(A^{[0]}(x)\) 中包含了 \(A\) 中下标为偶数的系数, 而 \(A^{[1]}(x)\) 则包含了 \(A\) 中下标为奇数的系数. 所以实际上我们根据下标可以得到如下结论:
因为次数界折半了所以代入的是 \(x^2\) , 然后对于奇数下标系数还要乘上一个 \(x\) 作为补偿.
于是我们就把求 \(A(x)\) 在 \(\omega_n^0,\omega_n^1,...,\omega_n^{n-1}\) 处的值转化成了这样:
1.求多项式 \(A^{[0]}(x)\) 和 多项式 \(A^{[1]}(x)\) 在下列点上的取值:
2.根据刚刚推导出的将两个按奇偶拆开的多项式的值合并的公式合并结果.
但是根据折半引理, 这 \(n\) 个要代入子多项式中求值的点显然并不是 \(n\) 个不同值, 而是 \(n/2\) 个 \(n/2\) 次单位复数根组成. 所以我们递归来对次数界为 \(n/2\) 的多项式 \(A^{[0]}(x)\) \(A^{[1]}(x)\) 在 \(n/2\) 个 \(n/2\) 次单位复数根处求值. 然我们成功地缩小了了子问题的规模. 也就是说我们将 \(DFT_n\) 的计算划分为两个 \(DFT_{n/2}\) 来计算. 这样我们就可以计算出 \(n\) 个元素组成的向量 \(\vec a\) 的DFT了.
我们结合递归FFT的C++实现来理解一下
void FFT(Complex* a,int len){
if(len==1)
return;
Complex* a0=new Complex[len/2];
Complex* a1=new Complex[len/2];
for(int i=0;i<len;i+=2){
a0[i/2]=a[i];
a1[i/2]=a[i+1];
}
FFT(a0,len/2);
FFT(a1,len/2);
Complex wn(cos(2*Pi/len),sin(2*Pi/len));
Complex w(1,0);
for(int i=0;i<(len/2);i++){
a[i]=a0[i]+w*a1[i];
a[i+len/2]=a0[i]-w*a1[i];
w=w*wn;
}
delete[] a0;
delete[] a1;
}
让我们逐行解读一下这个板子:
第2,3行是递归边界, 显然一个元素的 \(DFT\) 就是它本身, 因为 \(\omega_1^0=1\), 所以
第4~9行将多项式的系数向量按奇偶拆成两部分.
第12,13和第17行结合起来用来更新 \(\omega\) 的值, 12行计算主 \(n\) 次单位复数根, 13行将变量 \(w\) 初始化为 \(\omega_n^0\) 也就是 \(1\) , 17行使在组合两个子多项式的答案时可以避免重新计算 \(\omega_n\) 的幂, 而是采用递推方式最大程度利用计算中间结果(OI中的常用技巧, 对于主 \(n\) 次单位复数根还可以打个表来节约计算三角函数时的巨大耗时).
第10,11行将拆出的两个多项式递归处理. 我们设多项式 \(A^{[0]}(x)\) 的 \(DFT\) 结果为 \(\vec{y^{[0]}}\) , \(A^{[1]}(x)\) 的 \(DFT\) 结果为 \(\vec{y^{[1]}}\), 则根据定义, 对于 \(k=0,1,...,n/2-1\), 有:
然后根据消去引理, 我们可以得到 \(\omega_{n/2}^k=\omega_n^{2k}\), 所以
设整个多项式的 \(DFT\) 结果为 \(\vec y\), 则第15,16行用如下推导来将递归计算两个多项式的计算结果综合为一个多项式的结果:
第15行, 对于 \(y_0,y_1,...,y_{n/2-1}\), 我们设 \(k=0,1,...,n/2-1\) :
上面的推导中, 第一行是我们在代码中进行的运算, 第二行将 \(y_k^{[0]}\) 和 \(y_k^{[1]}\) 按定义代入, 第三行基于我们刚刚推导出的组合两个子多项式 \(DFT\) 结果的式子.
第16行, 对于 \(y_{n/2}, y_{n/2+1}, ..., y_{n-1}\) , 我们同样设 \(k=0,1,...,n/2-1\) :
上面的推导中, 第一行同样是我们在代码中进行的运算, 第二行从 \(\omega_n^{k+(n/2)}=-\omega_n^k\) 推导出, 第三行将 \(y_k^{[0]}\) 和 \(y_k^{[1]}\) 按定义代入, 第四行从 \(\omega_n^n=1\) 推导出, 最后一行基于推导出的组合递归结果用的等式.
根据这两段推导, 我们在代码中所作的计算能够得到正确的\(\vec y\).
其中我们把 \(\omega_n^k\) 称为旋转因子.
上述的算法实际上对应于下面的递归式:
所以我们讲完了...个鬼
别忘了我们只是求出了 DFT, 我们算卷积的时候把它们乘起来还得再 IDFT 回去彩星. 这种时候我们就得...
通过 FFT 在单位复数根处插值
根据我们的四步快速卷积计算方案(倍次/求值/点积/插值), 我们还剩下最后一步就可以完成这一切了.
首先, \(DFT\) 的计算过程按照定义可以表示成一个矩阵, 根据上文关于范德蒙德矩阵的等式 , 我们可以将 \(DFT\) 写成矩阵乘积 \(\vec y=V_n \vec a\), 其中 \(V_n\) 是用 \(\omega_n\) 的一定幂次填充的矩阵, 这个矩阵大概长这样:
观察矩阵中 \(\omega_n\) 的幂次, 我们似乎发现 \(\omega_n\) 的指数似乎组成了一张....乘法表???
因为我们将 \(DFT\) 表示为 \(\vec y=V_n \vec a\) , 则对于它的逆运算 \(\vec a=DFT^{-1}(\vec y)\) , 我们可以选择直接求出 \(V_n\) 的逆矩阵 \(V^{-1}_n\) 并乘上 \(\vec y\) 来计算.
然后就会有一个玄学的定理来告诉我们逆矩阵的形式, 算导上的证明如下:
定理: 对于 \(j,k=0,1,...,n-1\), \(V_n^{-1}\) 的 \((j,k)\) 处元素为 \(\omega_n^{-kj}/n\).
证明: 我们证明 \(V_n^{-1}V_n=I_n\), 其中 \(I_n\) 为一个 \(n\times n\) 的单位矩阵. 考虑 \(V_n^{-1}V_n\) 中 \((j,j')\) 处的元素:
\[[V_n^{-1}V_n]_{jj'}=\sum_{k=0}^{n-1}(\omega_n^{-kj}/n)(\omega_n^{kj'})=\sum_{k=0}^{n-1}\omega_n^{k(j'-j)}/n \]当 \(j'=j\) 时, 此值为 \(1\) , 否则根据求和引理, 此和为 \(0\).
注意, 只有 \(-(n-1)\leq j'-j \leq n-1\) , 从而使得 \(j'-j\) 不能被 \(n\) 整除,才能应用求和引理.
\(\blacksquare\)
上面证明的思路是, 求出 \(V_n^{-1}V_n\) 的各元素的值, 并和单位矩阵 \(I_n\) 比较, 发现求出的值与单位矩阵相符, 原命题得证.
得到这个定理之后我们就可以推导出 \(DFT^{-1}(\vec y)\) 了, 而我们发现它是长这样的:
我们发现它和 \(DFT\) 的定义极其相似! 唯一的区别仅仅在于前面的多出的 \(\frac{1}{n}\) 和 \(\omega_n\) 指数上多出来的负号. 也就是说, 我们可以通过稍微修改一下 \(FFT\) 就可以用来计算 \(DFT^{-1}\) 了!
最终我们可以得到像这样的代码, 通过第三个参数指定计算 \(DFT\) 还是 \(DFT^{-1}\) . 参数为 \(1\) 则计算 \(DFT\) , 参数为 \(-1\) 则计算 \(DFT^{-1}\). 除以 \(n\) 的过程在函数执行后在函数外进行即可.
void FFT(Complex* a,int len,int opt){
if(len==1)
return;
Complex* a0=new Complex[len/2];
Complex* a1=new Complex[len/2];
for(int i=0;i<len;i+=2){
a0[i/2]=a[i];
a1[i/2]=a[i+1];
}
FFT(a0,len/2);
FFT(a1,len/2);
Complex wn(cos(2*Pi/len),opt*sin(2*Pi/len));
Complex w(1,0);
for(int i=0;i<(len/2);i++){
a[i]=a0[i]+w*a1[i];
a[i+len/2]=a0[i]-w*a1[i];
w=w*wn;
}
delete[] a0;
delete[] a1;
}
FFT的速度优化与迭代实现
看到上面的实现, 根据OIer的常识, 我们显然可以意识到: 递归常数比较大. 而且上述实现中拆分多项式的时候还要重新动态分配一段空间显然慢的一匹. 本来FFT各种浮点运算常数大如狗然后你还要递归那么, 我们是否可以通过模拟递归时对系数向量的重排与操作来取得更好的执行效率呢?
裆燃可以辣!
首先我们可以注意到, 在上面的实现代码中计算了两次 \(\omega_n^k y^{[1]}_k\), 我们可以将它只计算一次并将结果放在一个临时变量中. 然后我们的循环大概会变成这样:
for(int i=0;i<(len/2);i++){
int t=w*a1[i];
a[i]=a0[i]+t;
a[i+len/2]=a0[i]-t;
w=w*wn;
}
我们定义将旋转因子与 \(y^{[1]}_k\) 相乘并存入临时变量 \(t\) 中, 并从 \(y^{[0]}_k\) 中增加与减去 \(t\) 的操作为一个蝴蝶操作.
接着我们考虑如何将递归调用转化为迭代. 首先我们观察递归时的调用树:
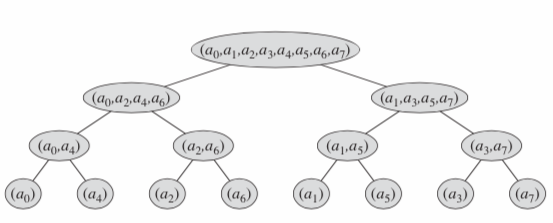
(没错这图就是算导上的)
我们可以发现如果我们自底向上观察这棵树, 如果将初始向量按照叶子的位置预先重排好的话, 完全可以自底向上一步一步合并结果. 具体的过程大概像这样:
-
首先成对取出元素, 对于每对元素进行 \(1\) 次蝴蝶操作计算出它们的 \(DFT\) 并用它们的 \(DFT\) 替换原来的两个元素, 这样 \(\vec a\) 中就会存储有 \(n/2\) 个二元素 \(DFT\) ;
-
接着继续成对取出这 \(n/2\) 个 \(DFT\) , 对于每对 \(DFT\) 进行 \(2\) 次蝴蝶操作计算出包含 \(4\) 个元素的 \(DFT\) , 并用计算出的 \(DFT\) 替换掉原来的值.
-
重复上面的步骤, 直到计算出 \(2\) 个长度为 \(n/2\) 的 \(DFT\) , 最后使用 \(n/2\) 次蝴蝶操作即可计算出整个向量的 \(DFT\).
实际实现时, 我们发现计算该轮要进行蝴蝶操作的两个元素的下标是比较方便的, 最外层循环维护当前已经计算的 \(DFT\) 长度, 每次循环完成后翻倍; 次级循环维护当前所在的 \(DFT\) 的开始位置的下标, 每次循环完成后加上 \(DFT\) 长度值; 最内层循环枚举 \(DFT\) 内的偏移量. 如果三个循环的循环变量分别为 \(i,j,k\), 则 \(j+k\) 指向当前要操作的第一个值, \(j+k+i\) 指向下一个 \(DFT\) 中需要计算的值.
然后关键的问题就在于如何快速重排得到递归计算时的叶子顺序.
我们以长度为 \(8\) 的 \(DFT\) 为例, 让我们打表找规律看看能不能发现什么:
| 原位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 原位置的二进制表示 | 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| 重排后下标的二进制表示 | 000 | 100 | 010 | 110 | 001 | 101 | 011 | 111 |
| 重排结果 | 0 | 4 | 2 | 6 | 1 | 5 | 3 | 7 |
看起来似乎...是把二进制表示给翻过来了?
这个过程在算导上似乎叫做位逆序置换, 这个过程可以直接遍历一遍并交换二进制表示互为逆序的各个下标所对应的值, 也可以预处理出来保存在一个数组中来在多次定长 \(FFT\) 中减少重复计算.
代码实现类似这样(我在这里将位逆序置换预处理掉存在rev数组里了)
void FFT(Complex* a,int len,int opt){
for(int i=0;i<len;i++)
if(i<rev[i])
std::swap(a[i],a[rev[i]]);
for(int i=1;i<len;i<<=1){
Complex wn=Complex(cos(PI/i),opt*sin(PI/i));
int step=i<<1;
for(int j=0;j<len;j+=step){
Complex w=Complex(1,0);
for(int k=0;k<i;k++,w=w*wn){
Complex x=a[j+k];
Complex y=w*a[j+k+i];
a[j+k]=x+y;
a[j+k+i]=x-y;
}
}
}
}
预处理部分大概这样:
for(int i=0;i<bln;i++)
rev[i]=(rev[i>>1]>>1)|((i&1)<<(bct-1));
其中bct是DFT长度的幂次.
实现中, 第一维枚举当前分治区间的长度(因为递归的时候递归到底才开始计算, 所以从小到大枚举分治长度), 第二维枚举分治区间的位置, 第三维在当前分治区间中进行蝴蝶操作.
上面的板子不包含最后除以DFT长度 \(n\) 的部分
然后我们就成功地给 \(FFT\) 加了个速OwO
现在的实现已经可以拿来做题了, 比如板子题 UOJ #34 多项式乘法
完整代码实现:
#include <bits/stdc++.h>
const int MAXN=270000;
const int DFT=1;
const int IDFT=-1;
const double PI=acos(-1);
struct Complex{
double real;
double imag;
Complex(double r=0,double i=0){
this->real=r;
this->imag=i;
}
};
Complex operator+(const Complex& a,const Complex& b){
return Complex(a.real+b.real,a.imag+b.imag);
}
Complex operator-(const Complex& a,const Complex& b){
return Complex(a.real-b.real,a.imag-b.imag);
}
Complex operator*(const Complex& a,const Complex& b){
return Complex(a.real*b.real-a.imag*b.imag,a.real*b.imag+a.imag*b.real);
}
Complex a[MAXN],b[MAXN],c[MAXN];
int n; //Length of a
int m; //Length of b
int bln=1; //Binary Length
int bct; //Bit Count
int len; //Length Sum
int rev[MAXN]; //Binary Reverse Sort
void Initialize();
void FFT(Complex*,int,int);
int main(){
Initialize();
FFT(a,bln,DFT);
FFT(b,bln,DFT);
for(int i=0;i<=bln;i++){
c[i]=a[i]*b[i];
}
FFT(c,bln,IDFT);
for(int i=0;i<=len;i++){
printf("%d ",int(c[i].real/bln+0.5));
}
putchar('\n');
return 0;
}
void FFT(Complex* a,int len,int opt){
for(int i=0;i<len;i++)
if(i<rev[i])
std::swap(a[i],a[rev[i]]);
for(int i=1;i<len;i<<=1){
Complex wn=Complex(cos(PI/i),opt*sin(PI/i));
int step=i<<1;
for(int j=0;j<len;j+=step){
Complex w=Complex(1,0);
for(int k=0;k<i;k++,w=w*wn){
Complex x=a[j+k];
Complex y=w*a[j+k+i];
a[j+k]=x+y;
a[j+k+i]=x-y;
}
}
}
}
void Initialize(){
scanf("%d%d",&n,&m);
len=n+m;
while(bln<=len){
bct++;
bln<<=1;
}
for(int i=0;i<bln;i++){
rev[i]=(rev[i>>1]>>1)|((i&1)<<(bct-1));
}
for(int i=0;i<=n;i++){
scanf("%lf",&a[i].real);
}
for(int i=0;i<=m;i++){
scanf("%lf",&b[i].real);
}
}
炸精现场与 NTT
有时候我们会遇到这样的东西:
- 求一个东西的方案数量, 计算过程中发现需要快速卷积
- 求一个东西的概率, 输出模一个大质数意义下的值, 计算过程中发现需要快速卷积
这个时候我们发现一个非常刺激的问题: FFT炸精了!
其次 FFT 全程对复数进行各种骚操作, 看着就慢的一匹, 能不能用整数代替啊?
当然可以啦!
但是单位复根的性质并不是很好在整数系统中体现...
我们在发现 \(\omega_n\) 可以简化运算的时候主要用了啥性质?
别忘了它的定义是啥.
\(\omega_n^n=1\) 啊!
所以我们要在整数中找满足 \(x^n=1\) 的非 \(1\) 值 \(x\).
等等好像只剩下 \(-1\) 了?
首先普通的乘法运算肯定不会越乘绝对值越小, 所以我们考虑怎么能允许它越乘越小呢?
取模!
于是我们就有了...
原根
阶
定义: 若 \(m>1\) 且 \(\gcd(x,m)=1\), 我们定义一个数 \(x\) 在剩余系 \(m\) 下的阶 \(\delta_m(x)\) 为使得 \(x^r \equiv 1 \pmod m\) 的最小的整数 \(r\).
于是我们有定理: 若 \(m>1\) 且 \(\gcd(x,m)=1\), \(x^n\equiv1\pmod m\), 则 \(\delta_m(x)|n\).
因为在 \(x\) 的所有幂次上, 第一次达到 \(1\) 即为 \(\delta_m(x)\), 于是 \(n\) 显然是 \(\delta_m(x)\) 的倍数.
这个阶其实就是指 \(x^k\) 在模 \(m\) 意义下的所有取值的个数. 也就是说当 \(k\) 取 \([0,\delta_m(x))\) 中的所有整数的时候 \(x^k\) 在模 \(m\) 意义下互不相同. 大概可以这样证明:
- 设 \(a,b\in[0,\delta_m(x))\), \(a<b\), \(x^a\equiv x^b\pmod m\), 则我们一定有 \(x^{b-a}\equiv1\pmod m\), 这与 \(\delta_m(x)\) 的定义矛盾.
原根的定义
设 \(m\) 是正整数, \(g\) 是整数, 若 \(\delta_m(g)=\varphi(m)\), 则称 \(g\) 为模 \(m\) 的一个原根.
原根的性质
- 对于正整数 \(m\), 当且仅当 \(m=2,4,p^k,2p^k\) 时 \(m\) 有原根. (\(p\) 为奇质数)
- 对于模 \(m\) 的原根 \(g\), 满足 \(g^k\pmod m(0\le k<\varphi(m))\) 与所有与 \(m\) 互质的数一一对应
这两个结论都挺显然的(吧)
于是原根也构成了一个有限群 \((G_m,\times_{\mathbb{Z}/m})\) . 其中 \(|G_m|=\varphi(m)\) .
原根的意义在于, 它能把 \([0,p-1)\) 这 \(p-1\) 个指数取不同的取值, 于是就成了一个最小周期为 \(p-1\) 的环.
回想 \(\omega_n\) 的那张图:
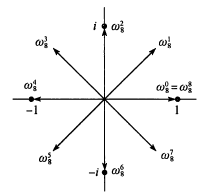
其实它的本质就是一个乘法环上的若干个不同值.
但是有一点不同!
\(g\) 能产生一个最小周期为 \(p-1\) 的环, 那么它最多只能产生 \(p-1\) 以及 \(p-1\) 的约数次单位根. 想一想, 为啥?
我们在求复数根的时候相当于在一个连续的圆周上均匀选了 \(n\) 个点, 但现在这个大圆不是连续的了. 它变成了 \(p-1\)个点, 而我们要均匀选 \(n\) 个点的话必定要满足 \(n|(p-1)\).
说了这么多, 那单位复根满足的三个引理它都满足嘛?
当然满足啦!
按照上面的定义, 我们在乘法环上这 \(n\) 个点的方法就是令 \(n\) 次单位根为 \(g^{(p-1)/n}\). 它的性质证明直接把 \(g^{(p-1)/n}\) 代进 \(\omega_n\) 里就证完了.
原根的求法
其实某个数的最小原根一般都很小, 再加上模数一般是固定的于是本机暴力枚举或者直接记住就可以了
实际上, 对于一个质数, \(a^{p-1}\equiv 1\pmod p\) , 所以 \(\delta_p(a)|(p-1)\), 于是我们只要枚举 \(p-1\) 的所有质因子 \(p_k\) 看看 \(a^{\frac{p-1}{p_k}}\) 是否都不是 \(1\) 就可以了.
扩展到模数为合数的情况只要用欧拉定理把 \(p-1\) 换成 \(\varphi(m)\) 就可以了.
NTT
其实会了 FFT 之后基本就会 NTT ((Fast) Number Theory Transform) 了.
因为根据上面的各种推♂倒, 我们只要用 \(g^{(p-1)/n}\) 代替 \(\omega_n\) 就可以了.
但是因为我们必须要令 \(n|(p-1)\), 而 \(n\) 因为后续分治的需要必须是 \(2\) 的整次幂, 于是我们需要令 \(p-1\) 是 \(r2^k\) 的形式, 其中必须有 \(2^k\ge n\) .
然而在OI题目中能实现的范围内, NTT长度不会超过 \(2^{20}\), 于是我们只要记住几个质数直接拿来用就星了
题目如果给定模数的话扔进计算器里看看二进制表示也就知道它是不是NTT模数了.
比如最常用的 UOJ 模数 \(998244353\), 它的一个原根为 \(3\).

它实际上等于 \(7\times17\times2^{23}+1\), 可以做长达 \(8388608\) 的NTT(然而实际上你真的跑这么长的 NTT 在 OI 时限内是跑不完的)
于是我们就可以得到 NTT 的板子辣~
void NTT(int* a,int len,int opt){
for(int i=0;i<len;i++){
if(i<rev[i]){
std::swap(a[i],a[rev[i]]);
}
}
for(int i=1;i<len;i<<=1){
int wn=Pow(G,(opt*((MOD-1)/(i<<1))+MOD-1)%(MOD-1),MOD);
int step=i<<1;
for(int j=0;j<len;j+=step){
int w=1;
for(int k=0;k<i;k++,w=(1ll*w*wn)%MOD){
int x=a[j+k];
int y=1ll*w*a[j+k+i]%MOD;
a[j+k]=(x+y)%MOD;
a[j+k+i]=(x-y+MOD)%MOD;
}
}
}
if(opt==-1){
int r=Pow(len,MOD-2,MOD);
for(int i=0;i<len;i++)
a[i]=1ll*a[i]*r%MOD;
}
}
理论上因为都是整数运算所以跑得比 FFT 要快
实际上上面这句理论是就是在扯淡.
因为瓦们有 SSE!
(SSE是一个现代CPU指令集, 全称Streaming SIMD Extensions, 单指令多数据流扩展. 包含各种浮点运算指令/MMX整数运算强化指令/连续内存块传输优化指令, 可以理解为这个指令集就是专门为各种现代化图形/科学计算设计的)
于是一般我们有这样的规律:
- 如果你用
std::complex, 那么 FFT 一般都要慢于 NTT - 如果你手写
Complex而且没有开-O2, 那么 NTT 一般快于 FFT - 如果你手写
Complex而且开了-O2, 那么 FFT 一般快于 NTT
除了 \(998244353\) 还有另外的一些模数, 比如:
- \(p=1004535809=479\times2^{21}+1\), \(g=3\)
- \(p=469762049=7\times2^{26}+1\), \(g=3\) (这个NTT长度更长, 但是数值有些偏小)
附一个(大概是miskcoo的) long long 以内的 NTT 模数表:
| 素数 | \(r\) | \(k\) | \(g\) |
|---|---|---|---|
| \(3\) | \(1\) | \(1\) | \(2\) |
| \(5\) | \(1\) | \(2\) | \(2\) |
| \(17\) | \(1\) | \(4\) | \(3\) |
| \(97\) | \(3\) | \(5\) | \(5\) |
| \(193\) | \(3\) | \(6\) | \(5\) |
| \(257\) | \(1\) | \(8\) | \(3\) |
| \(7681\) | \(15\) | \(9\) | \(17\) |
| \(12289\) | \(3\) | \(12\) | \(11\) |
| \(40961\) | \(5\) | \(13\) | \(3\) |
| \(65537\) | \(1\) | \(16\) | \(3\) |
| \(786433\) | \(3\) | \(18\) | \(10\) |
| \(5767169\) | \(11\) | \(19\) | \(3\) |
| \(7340033\) | \(7\) | \(20\) | \(3\) |
| \(23068673\) | \(11\) | \(21\) | \(3\) |
| \(104857601\) | \(25\) | \(22\) | \(3\) |
| \(167772161\) | \(5\) | \(25\) | \(3\) |
| \(469762049\) | \(7\) | \(26\) | \(3\) |
| \(1004535809\) | \(479\) | \(21\) | \(3\) |
| \(2013265921\) | \(15\) | \(27\) | \(31\) |
| \(2281701377\) | \(17\) | \(27\) | \(3\) |
| \(3221225473\) | \(3\) | \(30\) | \(5\) |
| \(75161927681\) | \(35\) | \(31\) | \(3\) |
| \(77309411329\) | \(9\) | \(33\) | \(7\) |
| \(206158430209\) | \(3\) | \(36\) | \(22\) |
| \(2061584302081\) | \(15\) | \(37\) | \(7\) |
| \(2748779069441\) | \(5\) | \(39\) | \(3\) |
| \(6597069766657\) | \(3\) | \(41\) | \(5\) |
| \(39582418599937\) | \(9\) | \(42\) | \(5\) |
| \(79164837199873\) | \(9\) | \(43\) | \(5\) |
| \(263882790666241\) | \(15\) | \(44\) | \(7\) |
| \(1231453023109121\) | \(35\) | \(45\) | \(3\) |
| \(1337006139375617\) | \(19\) | \(46\) | \(3\) |
| \(3799912185593857\) | \(27\) | \(47\) | \(5\) |
| \(4222124650659841\) | \(15\) | \(48\) | \(19\) |
| \(7881299347898369\) | \(7\) | \(50\) | \(6\) |
| \(31525197391593473\) | \(7\) | \(52\) | \(3\) |
| \(180143985094819841\) | \(5\) | \(55\) | \(6\) |
| \(1945555039024054273\) | \(27\) | \(56\) | \(5\) |
| \(4179340454199820289\) | \(29\) | \(57\) | \(3\) |
任意模数 NTT
刚刚我们说到, NTT 有一个局限就是模数必须能写成 \(r2^k+1\) 的形式而且 \(2^k\ge n\).
那如果有毒瘤出题人搞了个题目模数为 \(998244853\) (猫锟模数) 或者 \(99824353\) (meaty模数) 怎么办呢?
其实我们可以发现一个事情: 如果卷积的长度为 \(n\), 模数是 \(m\), 那么最终不取模的准确答案不会超过 \(nm^2\).
所以我们找三个 NTT 模数分别做一遍 NTT 然后 CRT 一发就好啦!
现在泥萌知道我刚刚为啥要多说几个模数了吧
然而这样搞出来的结果会爆 long long. 所以实现上还是有点技巧的.
我们要合并的式子是:
我们首先在 long long 范围内把前两项合并, 得到下面的东西:
然后我们设最后的答案是:
且 \(k\) 要满足:
那么这个 \(k\) 一定可以在模 \(p_3\) 意义下求出来:
其中 \(M^{-1}\) 是模 \(p_3\) 意义下的逆元.
于是我们就可以根据这个式子直接计算在对给定模数 \(p\) 取模的意义下的值了:
好像非常清真?
然而并不
这个过程其实局限也蛮多的.
首先模数 \(p\) 必须不能超过 \(10^9\) 数量级 (再大的话需要加模数, 加模数就得 NTT 更多遍, 而且最后 CRT 的时候可能无法避免地要计算高精度取模...常数当场爆炸)
其次第一步合并两个数的时候因为 \(M\) 是个 long long 范围内的数于是需要快速乘...然而倍增快速乘常数好像很捉鸡...于是我们就需要这个板子了:
LL Mul(LL a,LL b,LL P){
a=(a%P+P)%P,b=(b%P+P)%P;
return ((a*b-(LL)((long double)a/P*b+1e-6)*P)%P+P)%P;
}
主要原理是取模之后的答案用 \(A\% B=A-\left\lfloor\frac A B\right\rfloor B\) 来算.
注意其中 \(A\) 和 \(\left\lfloor\frac A B\right\rfloor B\) 都是可能爆 long long 的.
然而因为是减法而且溢出之后一般是循环溢出所以作差之后(大概)不会锅.
好像 \(2009\) 年集训队论文里有这玩意?
相信这个板子就用它吧, 不信就倍增...
如果坚信有符号溢出是 UB 的话你可以试试 unsigned
卷积状物体与分治 FFT
有时候我们会发现形如这样的式子
它是卷积么?
显然它不是卷积. 但是它看上去确实长得很像卷积, 唯一不同的是 \(f\) 同时出现在了等式两边.
(注意求和下指标是从 \(1\) 开始的)
这式子怎么求?
\(O(n^2)\) 的算法非常显然, 根据定义式从小到大枚举 \(x\) 就可以计算了.
然而出题人才不会这么放过你呢哼!
教练我会 FFT!
然而直接算因为会有自己转移到自己这种操作, 所以我们如果对于每个 \(x\) 都算一遍 FFT 的话就变成 \(O(n^2\log n)\) 了...还不如 BFT 呢...
我们考虑优化.
因为这是个求和式子, 其中每一项都是前面某一个已经求过的 \(f(x)\) 与另一个相对比较固定的函数值的乘积. 我们考虑将这些贡献分别计算.
假设我们已经知道了 \(f(1)\) 到 $ f(\frac n 2)$ 的值, 我们要计算它对未知部分 \(f(\frac n 2+1)\) 到 \(f(n)\) 的贡献. 我们发现对于一个已知的 \(f(x)\) , 它对任意一个 \(i>x\) 的 \(f(i)\) 的贡献都只有 \(f(x)g(i-x)\). 设未知部分的 \(f\) 值为 \(0\) , 于是贡献函数 \(F\) 就长这样了:
好辣现在它是个卷积辣~
实际应用的时候, \(f\) 只需要填充 \([l,mid)\) 的部分, \(g\) 只需要填充 \([1,r-l]\) 的部分就可以了 (因为其他地方的 \(f\) 值都是 \(0\), 而贡献只要算 \([mid,r)\) 的部分).
于是我们CDQ分治一下, 先递归跑 \([l,mid)\), 然后算贡献, 然后跑 \([mid,r)\)就完成了.
板子没时间写了, 窃了一份.
void cdq(int l,int r){
if(l==r) return;
int mid=l+r>>1;
cdq(l,mid);
int up=r-l-1;
// for(lg=0,sze=1;sze<=(up<<1);sze<<=1)++lg;--lg;
for(lg=0,sze=1;sze<=up;sze<<=1)++lg;--lg;//其实只用的到区间长度,实际却有两倍,所以保险用两倍。
for(int i=0;i<sze;i++) R[i]=(R[i>>1]>>1)|((i&1)<<lg),A[i]=B[i]=0;
// memset(A,0,sizeof(A));memset(B,0,sizeof(B));
// fill(A,A+sze,0);fill(B,B+sze,0);//这两种方法赋值fill会比memset快一些(因为fill确定了大小)
for(int i=l;i<=mid;i++) A[i-l]=f[i];
for(int i=1;i<=r-l;i++) B[i-1]=g[i];
calc(A,B,sze);
for(int i=mid+1;i<=r;i++) f[i]=(f[i]+A[i-l-1]%mod)%mod;
cdq(mid+1,r);
}
calc 函数是计算 A 和 B 的卷积并把结果放在 A 里.
FWT 与位运算卷积
我们之前讲到卷积, 说离散卷积可以表示为如下形式:
我们迷思一下: 当运算 \(\circ\) 为位运算的时候是什么玩意?
这便是位运算卷积了, 相当于下标系统是二进制数以及位运算的卷积.
回想我们求多项式乘法卷积的时候, 搞了个大新闻构造了个卷积性变换 DFT, 然后把 \(A\) 和 \(B\) 都 DFT 掉然后求点积再 IDFT 回来就得到了卷积.
于是我们现在要构造一些新的卷积性变换 \(T\) , 满足 \(T(A)\cdot T(B)=T(A*_\oplus B)\). 而且还得有搭配的逆变换 \(T^{-1}\).
这个变换便是 Fast Walsh-Hadamard Transform.
FWT 与 \(\text{or}\) 卷积
构造变换 \(T\)
若 \(x\ \text{or}\ y=z\) , 那么 \(x\) 和 \(y\) 一定满足它们的二进制代表的集合都是 \(z\) 的子集.
于是我们把下标看成集合, 那么我们发现这个卷积对并集一致的下标一视同仁, 于是我们可以把所有子集都求和来让它们能快速卷起来(乘法分配律你不会嘛?), 于是我们尝试如此定义变换 \(T\):
那么我们就有了 \(T(A*B)=T(A)\cdot T(B)\).
为啥?
我们展开它:
显然它们都等价于:
于是我们便完成了第一步: 构造一个卷积性变换.
计算变换 \(T\)
直接按照定义式计算显然又双㕛叒叕变成 \(O(n^2)\) 的了...
我们发现, 位运算有个特点就是每一位相互独立. 于是我们非常自信地选择按位分治.
设我们要变换的数列为 \(A\), 则 \(A_0\) 为 \(A\) 中下标的最高的二进制位为 \(0\) 的值构成的数列, \(A_1\) 为下标的最高二进制位为 \(1\) 的值构成的数列. 实际上 \(A_0\) 就是前一半, \(A_1\) 就是后一半. 显然当 \(A\) 长度为 \(1\) 的时候变换就是它自己.
如果我们知道了 \(T(A_0)\) 和 \(T(A_1)\) , 那是不是就可以求 \(T(A)\) 了呢?
裆燃可以辣!
假设当前 \(A\) 的长度为 \(2^k\):
- \(A_0\) 相当于是第 \(k\) 位填 \(0\) (不选), 那么子集肯定还是只有 \(T(A_0)\) 里的值.
- \(A_1\) 相当于是第 \(k\) 位填 \(1\) (选中), 那么子集除了 \(T(A_1)\) 里的值, 还有 \(T(A_0)\) 里的值.
于是我们就有了合并方法了.
设 \(A=(B,C)\) 表示把 \(B\) 和 \(C\) 首尾相接得到的数列赋给 \(A\), 那么:
其中 \(+\) 表示直接对位算术相加.
为啥直接算术相加? 显然分治的过程可以保证对位的时候除了第 \(k\) 位外其他的更低的位的选中情况完全一致.
其实这好像是个CDQ分治的过程, 递归分治然后算左半部分对右半部分的贡献.
于是我们就在 \(O(n\log n)\) 的时间复杂度内计算出 \(T(A)\) 辣~
计算逆变换 \(T^{-1}\)
其实有了变换的分治算法, 逆变换算法就直接解出来了.
我们只要递归地把左边对右边的贡献减掉就好了啊
于是式子就长这样了:
应该没啥不好理解的(吧)
迭代实现
我们发现这一整个分治过程都和FFT极其相似, 那么我们能不能像FFT一样迭代实现它呢?
当然可以啦!
而且这次因为 \(A_0\) 就是前半部分 \(A_1\) 就是后半部分所以甚至根本就没有重排过程.
于是我们就可以写出这样的板子:
void FWT(LL *a,int opt){
for(int i=2;i<=N;i<<=1)
for(int p=i>>1,j=0;j<N;j+=i)
for(int k=j;k<j+p;++k)
a[k+p]+=a[k]*opt;
}
第一维枚举当前分治长度, 第二维枚举当前分治区间的位置, 第三维计算贡献. 跟 FFT 的迭代实现极为相似.
然后就没了.
FWT 与 \(\text{and}\) 卷积
构造变换 \(T\)
若 \(x\ \text{and}\ y=z\), 那么 \(x\) 和 \(y\) 一定都满足它们的二进制代表的集合都是 \(z\) 的超集.
于是我们依葫芦画瓢, 按照 \(\text{or}\) 卷积的形式定义变换 \(T\):
那么它肯定也满足 \(T(A*B)=T(A)\cdot T(B)\) 了.
计算变换 \(T\)
按照 \(\text{or}\) 卷积的基本思路, 我们同样把 \(A\) 分为两部分 \(A_0\) 和 \(A_1\) , 然后计算它们之间的影响.
显然我们可以得到下面的计算式:
为啥这样应该不用我多说了吧
- \(A_0\) 相当于是第 \(k\) 位填 \(0\) (不选), 那么超集除了 \(T(A_0)\) 里的值, 还有 \(T(A_1)\) 里的值.
- \(A_1\) 相当于是第 \(k\) 位填 \(1\) (选中), 那么超集肯定还是只有 \(T(A_1)\) 里的值.
计算逆变换 \(T^{-1}\)
其实就是把左边向右贡献改成右边向左贡献了吧
不理解的话大概需要 ROLLBACK 到 \(\text{or}\) 卷积的地方...
迭代实现
void FWT(LL *a,int opt){
for(int i=2;i<=N;i<<=1)
for(int p=i>>1,j=0;j<N;j+=i)
for(int k=j;k<j+p;++k)
a[k]+=a[k+p]*opt;
}
是的, 就是把 \(\text{or}\) 卷积的 a[k] 和 a[k+p] 给 std::swap 了一下.
FWT 与 \(\text{xor}\) 卷积
前面 \(\text{or}\) 卷积和 \(\text{and}\) 卷积都是小意思而且本质相似.
然而 \(\text{xor}\) 就开始鬼畜起来了... (虽然最后写出来也没长到哪去)
构造变换 \(T\)
在 \(\text{and}\) 和 \(\text{or}\) 卷积中, 我们利用了一些集合操作成功地构造出了一个卷积性变换, 然而 \(\text{xor}\) 可就没有这样优秀的性质了...
我们需要寻找一些像上面两个卷积中那样的性质.
这个时候我们引入一个定理:
设 \(d(x)\) 表示 \(x\) 的二进制表示中 \(1\) 的个数的奇偶性, 则我们有:
理解一下?
其实首先里面那个 \(\text{and}\,k\) 可以直接扔掉不管, 我们直接看其他的.
这个定理的正确性我们可以理解为, \(j\) 中每多包含一个 \(1\), 必定都会让 \(d(i\,\text{xor}\,j)\) 的值翻转一次.
于是我们就可以尝试构造出长这样的变换 \(T\):
于是我们又有了 \(T(A*B)=T(A)\cdot T(B)\).
我们展开来看看发生了什么 (前方鬼畜预警):
而实际上根据上面的定理, 我们有:
于是我们莫名其妙地又完成了第一步.
计算变换 \(T\)
我们还是照样按位分治, 分别考虑最高位取 \(0\) 或 \(1\) 的情况.
但这次与 \(\text{or}\) 和 \(\text{and}\) 不同的地方在于, 这次我们分治两侧的区间会相互产生贡献了.
(不过还好它们没有变成环)
首先我们假设我们不考虑第 \(k\) 位的贡献会发生什么.
因为不考虑最高位, \(T(A_0)\) 和 \(T(A_1)\) 的对应位置的求和指标在对应的分治区间内的相对位置都是完全一样的.
-
当最高位是 \(0\) 的时候, \(\text{and}\) 运算的结果并不产生影响, 所以我们直接把 \(T(A_0)\) 和 \(T(A_1)\) 的相对位置加起来就可以了.
-
当最高位是 \(1\) 的时候, \(\text{and}\) 运算的结果可能会产生区别. 左半部分因为下标最高位是 \(0\) 于是直接产生贡献, 右半部分下标最最高位是 \(1\), 于是多了一个翻转奇偶性的贡献, 翻转奇偶性之后根据定义式, 两个求和号的内容互换, 相当于交换符号, 于是我们把它取反加在对应位置.
于是总的计算式就是:
计算逆变换 \(T^{-1}\)
话说泥萌再看看这个变换计算式, 它是不是有点眼熟?
这个 \(+/-\) 的过程是不是有点像...Manhattan距离和Chebyshev距离互化的坐标系变换过程?
那个变换的逆变换是啥来着?
其实我们直接解就可以了, \(A_0'\) 和 \(A_1'\) 分别求和或者求差就可以消掉另一项, 然后再除以 \(2\) 就可以了.
于是我们就有了 \(T^{-1}\):
迭代实现
跟前面一个思路, 不过逆变换要记得除以 \(2\).
void FWT(int *a,int opt){
for(int i=2;i<=N;i<<=1)
for(int p=i>>1,j=0;j<N;j+=i)
for(int k=j;k<j+p;++k)
{
int x=a[k],y=a[k+p];
a[k]=(x+y)%MOD;a[k+p]=(x-y+MOD)%MOD;
if(opt==-1)a[k]=1ll*a[k]*inv2%MOD,a[k+p]=1ll*a[k+p]*inv2%MOD;
}
}
inv2 是预处理的 \(2\) 的逆元.
FMT 与子集卷积
有时候我们发现在图论问题中有时候会搞出这种东西:
其中 \(S\) 和 \(T\) 都是集合. 或者另一种(大概)等价的表达式:
第一眼我们大概会用 \(\text{or}\) 卷积来搞, 然而我们会发现一个非常滑稽的事情: \(A\) 和 \(B\) 不能有交集, 而 \(\text{or}\) 卷积则没有限制这一点. 咋办?
首先大家可能会天真地以为 FMT 就是直接干这个的
然而实际上 FMT 和 \(\text{or}\) 卷积一毛一样, 因为它的定义是这样的:
网上的 FMT 计算方法是这样的:
inline void FMT(int *a,int len,int opt) {
for (int i = 1; i < len; i <<= 1)
for (int j = 0; j < len; ++j)
if (j & i)
a[j]+=a[j^i]*opt;
}
其实这个计算过程也和上面的 FWT 计算 \(\text{or}\) 卷积本质完全一样. 想一想为啥 (注意看 i 枚举的是什么)
那我们要怎么满足交集为 \(\varnothing\) 的限制呢?
我们加一维表示集合大小再做 FMT. 这样的话式子就变成了:
然后我们对位相乘的时候把所有集合大小与当前位置相等的都手动卷起来, 得到:
然后我们再逆变换回去, 便得到:
为啥逆变换回去之后是对的呢?
我们在变换与逆变换的过程中, 求和式中的每一项都是独立的, 于是逆变换的时候 \(f(A)g(B)[|A|+|B|=k]\) 就会被看做一个整体对待(因为它们之间是相乘的, 是同一项).
众所周知, 如果 \(|A\cup B|=|A|+|B|\) 的话, \(A\cap B=\varnothing\). 所以我们只取 \(p_k(S)\) 中 \(|S|=k\) 的部分就是答案了.
总时间复杂度因为多了一维要再乘上一个集合大小, 转换成 FMT 长度的话就是 \(O(n\log^2n)\).
卷积与字符串
首先讲个笑话
去年打NEERC的时候发现的
从前, 有三个神仙组了个队注册了, 他们叫...叫啥来着...(突然忘了)

后来, 又有三个人组了个队注册了, 他们叫做:

于是前面三位神仙就改了个队名:

然而刚刚讲了那么多东西, FFT 和bitset怎么扯上的关系呢?
其实它们功能的交集是一些字符串问题.
卷积与回文序列
记得BZOJ里有这么一个题: 万径人踪灭
首先我们可以得到一个非常显然的思路: 对于每个回文中心, 计算以它为中心对称的字符个数 \(k\), 于是它会对答案产生 \(2^k\) 的贡献. 同时题目要求不允许连续的回文串, 但是我们发现连续的回文串一定都在刚刚的过程中算过了, 于是我们跑一遍 Manacher 求出回文子串个数在答案中减掉就好了.
这个过程的复杂度瓶颈在对于每个回文中心都计算对称字符个数, 直接枚举计算显然是 \(O(n^2)\) 的. 考虑优化这个过程.
首先我们发现字符集大小 \(\Sigma\) 只有 \(2\) , 我们可以考虑把每种字符产生的贡献分开计算. 我们考虑相对某个回文中心对称的下标有什么共同点?
它们的下标值之和是固定的!
我们可以理解为, 两个位置的下标值的平均值就是对称中心的位置. 而平均值中除以 \(2\) 的部分我们可以同时忽略.
那么我们设原字符串为 \(s\) , \(f(x)\) 为对称中心 \(\frac x2\) 产生的贡献, 那么我们就可以得到这样的式子:
经过 \(0.5\texttt{s}\) 的思考之后我们非常滑稽地发现: 它是一个卷积的形式!
我们把原串 \(s\) 转化为数列 \(S_i=[s_i=k]\), 然后用 FFT/NTT 计算出 \(S*S\) 的结果就可以了!
于是问题完美解决!
卷积与通配符
考虑这样一个问题:
给定一个字符串和一个模板串, 两个串中有一些字符是通配符, 求模板串与字符串的所有匹配位置.
大家先顺着上一节的套路撕烤一下?
首先我们得想办法匹配字符串.
KMP/ST/SAM等等状态转移自动机肯定是不行的, 单次匹配倒是没问题. 但是单次匹配你为啥不直接暴力呢?
我们考虑什么初等计算可以起到 "只要进行这个运算, 不管什么值都会得到一个同样的值" 这样的通配效果?
乘 \(0\) !
我们可以构造一个表达式, 让它为 \(0\) 的时候表示该位置匹配, 这样我们只要让通配符出现的时候让它与 \(0\) 相乘就可以让整个项代表匹配了, 也就是实现了通配.
比较显然的操作是把对应位置字符值做差, 但是差来差去万一有正有负结果消成 \(0\) 了不就假了?
瓦们可以套个绝对值!
于是我们设原串为 \(S\), 模板串为 \(P\), 可以这样表示一个位置是否匹配:
若某位置是通配符则字符值为 \(0\) , 那么显然当且仅当 \(M(x)=0\) 的时候位置 \(x\) 匹配.
然而绝对值可不怎么好算...
注意到我们只是想看看最终答案是不是 \(0\), 那么显然我们可以通过平方的方式把绝对值去掉, 于是得到:
现在它变成了三个看上去像卷积的东西...
然而我们非常滑稽地发现: 这个卷积中下标运算不是加法而是减法!
咋办?
我们只需要用下面这个小学生都知道的式子:
我们想办法把其中一个串的下标变成负的!
然而直接变成负的的话好像非常不清真. 我们再加个 \(\text{len}\) 把它补成正的吧!
于是我们就要搞一个这样的变换来预处理:
emmmmm...
这不就是™ std::reverse 了一下么
(也就是说当你发现减法卷积的时候翻转其中一个就可以了)
然后就可以搞事情了! 我们预处理出 \(S_i^2,S_i^3,P_i^2,P_i^3\) 然后再 std::reverse 一下 \(P\), 卷起来看哪位是 \(0\) 就可以了!
因为都是整数, NTT/FFT均可.
一点优化?
刚刚我们的做法要算三个卷积做⑨遍FFT/NTT, 常数直接起飞.
如果原串和模板串都带通配符的话并没有别的办法, 只能像个⑨一样做⑨遍FFT. (讲道理⑨怎么会FFT呢)
(实际上我们本质上是多项式乘法再加法的形式, 所以按照点值表示的运算法则算就可以了, 总计 7 遍 FFT)
但是如果只有模板串或只有原串带通配符呢?
我们可以考虑复数!
刚刚我们为啥不能直接做差呢? 因为正负相消, 两个不匹配位置可能一个 \(+k\) 一个 \(-k\) 造成假匹配.
如果是复数呢?
我们按照惯例先说个结论: \(k\) 个模长为 \(1\) 的复数相加, 它们的和为 \(k\) 当且仅当这些复数都是 \(1\).
于是我们把这个差搬到 \(e^i\) 的指数上就好辣!
为啥?
假设出现了假匹配, 那么我们显然会得到这种东西:
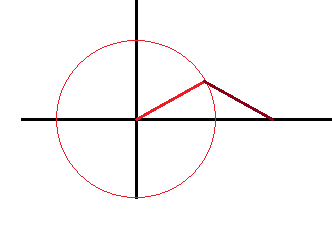
那个圆就是单位圆.
而实际上只有下面这种东西我们才会被认为是匹配:
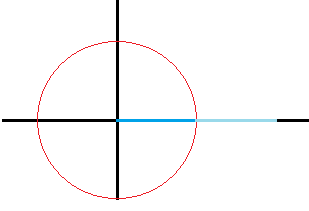
显然假匹配的实部是不够长的.
于是我们对于原串做变换 \(S_i=\exp\left(\frac{s_i\pi i}\Sigma\right)\), 模板串做变换 \(P_i=\exp\left(\frac{-p_i\pi i}\Sigma\right)\), 翻转模板串后直接卷积就可以了.
判断某个位置匹配只需要看卷出来之后的实部大小是否和模板长度减去通配符数量一致就可以了.
于是我们只需要一次卷积三次 FFT 就解决了通配符匹配问题.
这次因为动用了复数所以并不能用 NTT 来搞了...
实际上常数依然不小, 于是...

(大雾
写在最后
卷积性变换在 OI 圈里的普及度越来越高了...而且确实很有用也很好用. 毕竟卷积这种形式在自然界也蛮常见的.
尤其是在以 998244353 出名的UOJ(雾
这篇博客本来是一份知识分享讲稿, 结果由于时间关系最后部分写得比较仓促, 还请现在在看这篇博客的您谅解!
如果你觉得这篇博客写得比较全面, 还请点击右下角推荐一下qwq~ 如果你觉得博客中有错误或写得晦涩的地方也欢迎在评论区指正或询问~
本博客已弃用, 新个人主页: https://rvalue.moe, 新博客: https://blog.rvalue.moe

 浙公网安备 33010602011771号
浙公网安备 33010602011771号