
7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
逻辑回归是通过正则化防止过拟合;当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,而正则化可以保留所有的特征变量的前提下,同时减小特征变量的数量级,由此可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
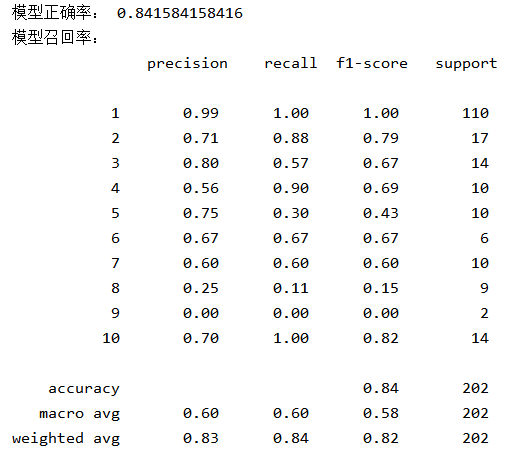
import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report data = pd.read_csv('log426.csv') x = data.iloc[:,1:5] y = data.iloc[:,3] x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3) # 构建逻辑回归预测 gg = LogisticRegression() gg.fit(x_train,y_train) # 训练模型 pre = gg.predict(x_test) print('模型正确率:',gg.score(x_test,y_test)) print('模型召回率:\n',classification_report(y_test,pre))
输出结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号