IO 多路复用
Linux 操作系统中断
举个简单的场景,比如你正在家里打单机游戏,突然你饿了,然后你就打电话,叫了一份外卖,你此时叫完外卖,没有必要一直在这里等着,你可以回头继续打游戏,等你游戏打到大 boss 的时候,这个时候,外卖小哥过来敲门了,那么此时你肯定不能退出游戏,因为退出了游戏,再进就得从头开始打,所以你此时应该把游戏存档,然后去拿外卖,然后吃外卖,吃完以后,就可以读取存档,继续打游戏了。
那么在上面的过程中,外卖小哥过来敲门,其实就是一个 中断指令 ,而游戏存档,就是 CPU现场保护,也就是存在进程的 PCB 里面。
系统中断,硬中断,软中断
硬中断
硬中断就是硬件发起的中断,可以发生在任意时间。一般情况下,这种引起中断的请求,和 CPU 当前运行的程序,基本上没有关系。
通过晶振来完成
软中断
软中断是CPU发起的中断。软中断一般是 80中断 。

多线程的问题
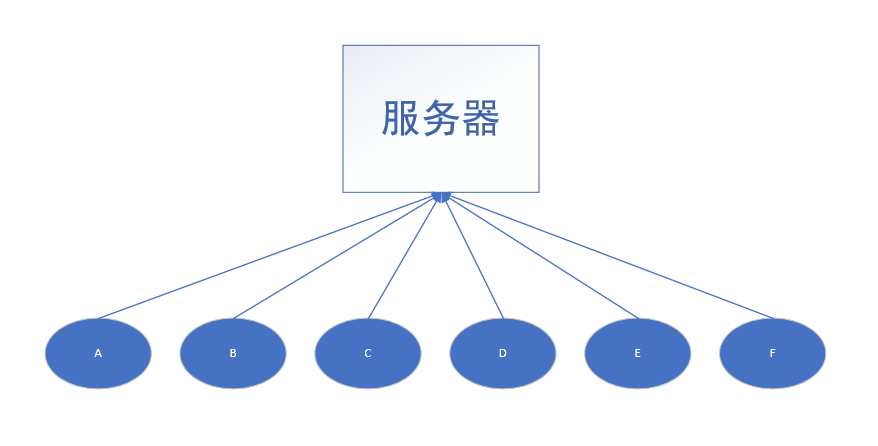
比如上面的情况,一个服务器有多个 连接请求,那么这种情况下,如果来回的切换线程,就会比较麻烦,所以这个时候,就要考虑单线程
BIO底层通信原理

比如上边的这个问题,如果我们要设置一个服务器,这个服务器要接受 一万个请求,那么难道要开一万个线程吗?显然这是不行的。
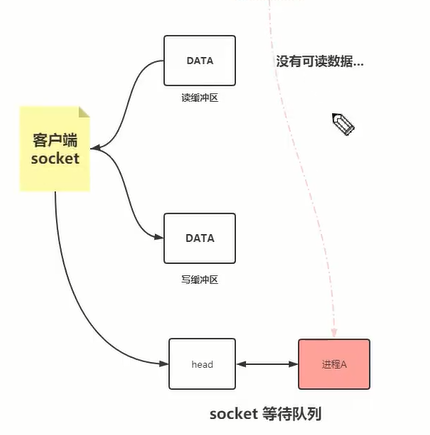
Linux的 I/O 复用函数详解
DMA机制
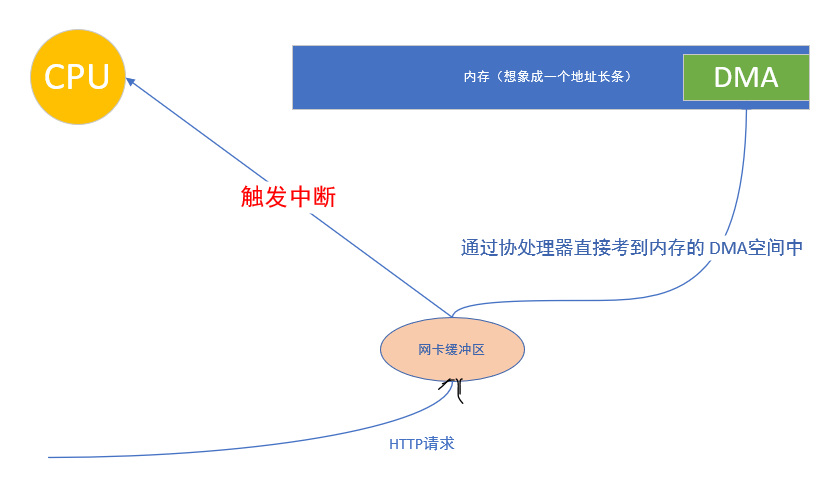
如上图,实际的网络请求的数据发送过来以后呢,如果这个时候,网卡触发中断,让CPU去把网卡中的东西,挪到内存中,这个 CPU干的活就有点太多了,所以实际上现代电脑中,都是使用叫做DMA的 协处理器,用它把内存中的东西搬到内存中独立开辟的一段空间,而不需要CPU去搬了,只是在搬完以后会触发一个中断,告诉 CPU 已经搬完了。
DMA(Direct Memory Access,直接内存存取) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。
socket创建
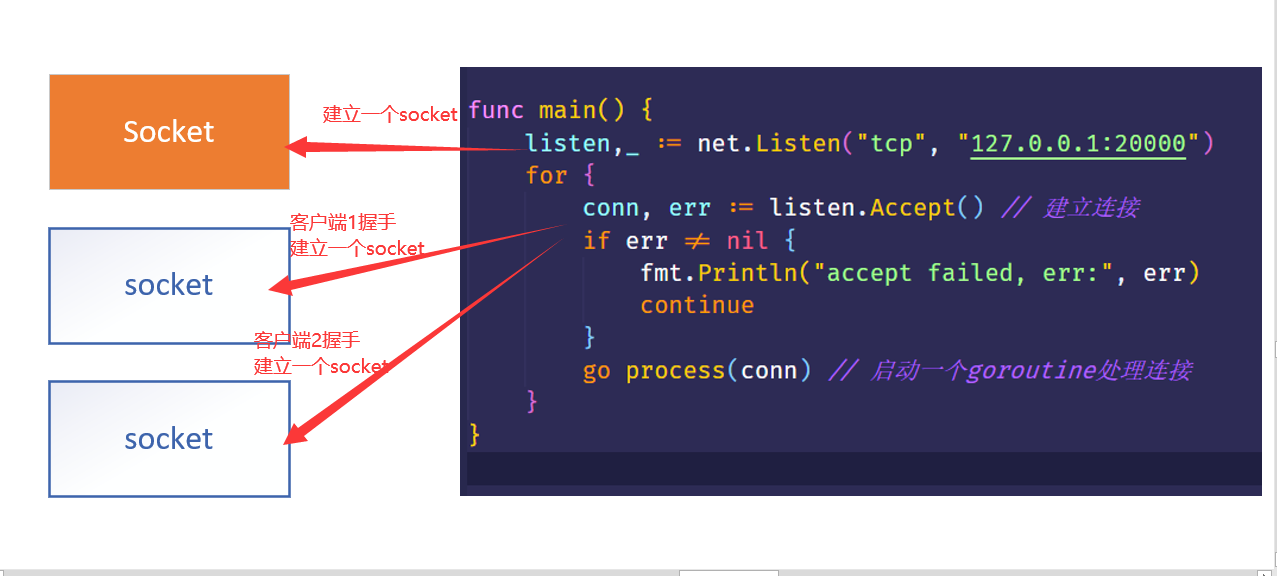
通过 Linux 的源码,可以发现,当服务器端启动的时候,就是首先建立一个 socket,然后再有一个客户端经过三次握手以后,就会建立一个 socket,但是我们的客户端虽然建立了,但是有可能一万年都不发数据,难道我们要用for循环遍历一万年吗?见代码下面第三行for循环,我们的多路复用,就是监视这些个 socket,而不是用 for 循环不断的循环。
func process(conn net.Conn) {
defer conn.Close() // 关闭连接
for { //此处如果不进行监视的话,只能不断的遍历了。
reader := bufio.NewReader(conn)
var buf [128]byte
n, err := reader.Read(buf[:]) // 读取数据
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client端发来的数据:", recvStr)
conn.Write([]byte(recvStr)) // 发送数据
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
for {
conn, err := listen.Accept() // 建立连接
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn) // 启动一个goroutine处理连接
}
}
IO多路复用
到底哪个socket有数据了,这个是操作系统干的事情,而不是用户程序干的事,因为这个功能是公用的,而且涉及到网卡等计算机硬件,所以他要由操作系统来完成。 操作系统有三个函数来完成这个事情,一个是 select 、一个是 poll 、一个是 epoll
select函数
select函数的道理比较直观,他是把想要监视的socket的文件描述符,转成 bitmap 这种格式,然后把想要监控的文件标识符置为1,其余的置为0,然后把这个 fd 数组传给 select 函数,select函数就进行遍历,当有文件描述符变化的时候,就会把这个文件描述符数组返回过去,原函数就会对返回回来的函数,进行遍历,同时对原来的fd数组进行对比,因为只有原 fd 数组记录了要监视的socket的文件描述符。所以对比才知道到底那个文件描述符发生了变化。
所以select 函数的复杂度为n。
poll函数
因为 select 函数要牵扯到把数组从用户态王内核态拷贝,所以他的不能太大,一般的语言都把他限制在 1024,或者 2048,左右。
所以这也导致了 poll函数的两个缺点
-
poll函数就是使用了类似于链表的格式,打破了
fd数组大小的限制。 -
poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll函数
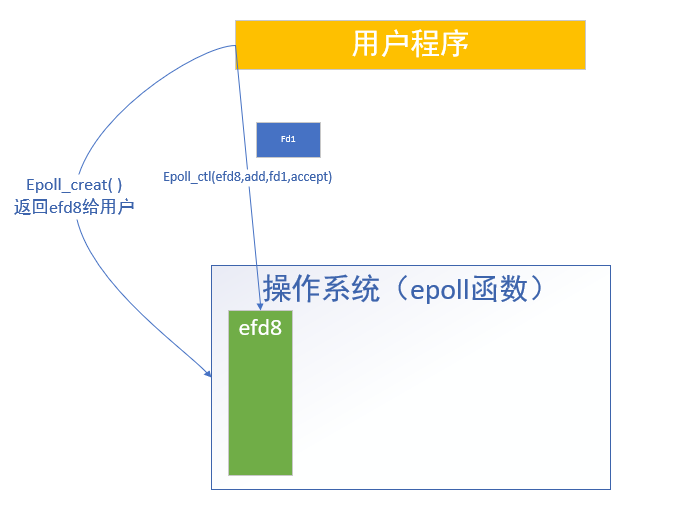
如上图,用户会先调用 epoll_ctr ,让内核中,产生一个缓冲区,在这个缓冲区中会建立一个 efd8的buffer,
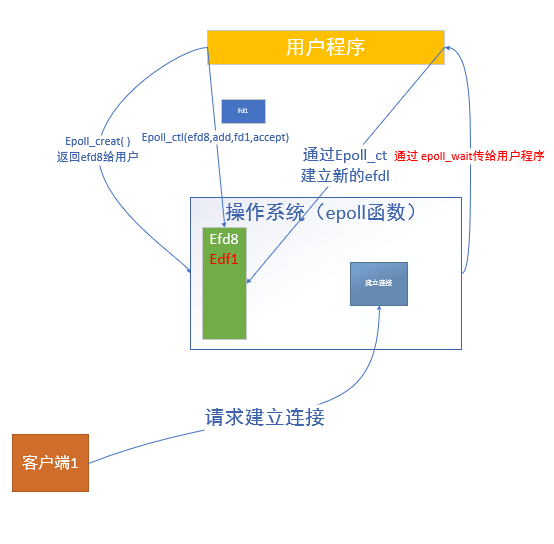
这个时候,如果有哪个 efd 发生变化,那么就会把这个请求,就会通过 epoll_wait 传给用户知道
epoll函数是事件驱动型的,他可以把IO多路复用的时间复杂度,从原来的O(n),降为O(1)。
水平触发和边缘触发
| 水平触发 | 边缘触发 |
|---|---|
| 不断轮询监控每个文件描述符的状态,有的话就触发事件,如果处理完事件,还剩下文件描述符,内核会再次触发事件 | IO状态改变,才触发事件,一次使用完所有可用的。 |
水平触发:就是不断查询是否有可用的文件描述符,有的话,内核就触发时间,如果数据没有处理完,内核会继续触发事件。
边缘触发:只有当IO状态改变的时候,才触发事件,每次触发会把所有的数据全部处理完,因为下一次处理,要等下次IO状态改变,才能触发。
参考文献
https://www.cnblogs.com/aspirant/p/9166944.html
https://www.bilibili.com/video/BV1JU4y1h7YM?p=10&share_source=copy_web

 浙公网安备 33010602011771号
浙公网安备 33010602011771号