Mysql 中的日志
概论
日志系统主要有redo log(重做日志)和binlog(归档日志)。redo log是InnoDB存储引擎层的日志,binlog是MySQL Server层记录的日志, 两者都是记录了某些操作的日志(不是所有)自然有些重复(但两者记录的格式不同)。
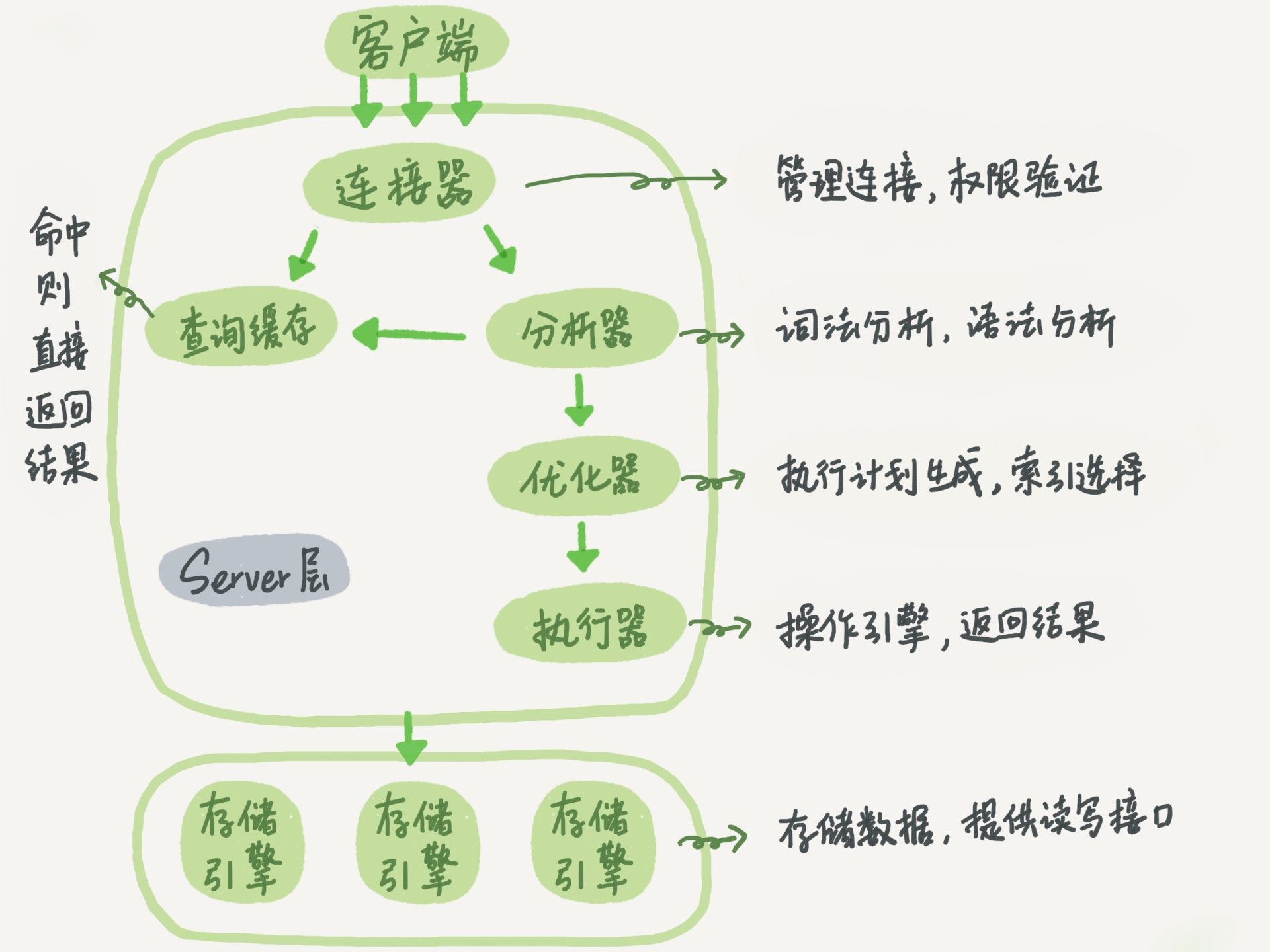
每一层的主要功能
-
客户端:建立连接,提交
sql语句。 -
连接器:管理连接,验证权限。可以通过
show PROCESSLIST;语句来查看连接情况。 -
分析器:词法分析,语法分析。会生成抽象语法树,
抽象语法树(abstract syntax tree 或者缩写为 AST); -
优化器:根据优化规则,对查询的
mysql语句进行优化。大概分为两种RBO规则CBO源码
-
执行器:执行
sql和存储引擎的交互。 -
查询缓存器:mysql8.0以后的版本,这个模块就取消了,因为这个的数据命中率很低,而且还需要经常更新。
日志记录顺序
精简版(以update语句为例)
-
Innodb在收到一条
Update语句以后,会在数据库中查找到所在的页,并将该页缓存在buffer pool中, -
执行
Updata语句,修改buffer pool中的数据,也就是内存中的数据。 -
针对
Update语句生成一个redolog对象,并存在logbuffer中。 -
针对
Update语句生成undulog日志,用于回滚。 -
如果事务提交成功,那么则会把
redolog持久化。 -
如果事务回滚,那么则利用
undolog日志进行回滚。
比如执行如下语句:update T set c=c+1 where ID=2;
-
执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入
buffer pool中。 -
执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
-
引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
-
执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
-
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
日志的作用
redo log(重做日志)
redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。
在一条更新语句进行执行的时候,InnoDB引擎会先把更新记录写到redo log日志中,然后更新内存,此时算是语句执行完了,然后在空闲的时候或者是按照设定的更新策略将redo log中的内容更新到磁盘中,这里涉及到WAL即Write Ahead logging技术,他的关键点是先写日志,再写磁盘。
redo log日志的大小是固定的,即记录满了以后就从头循环写。
bin log
binlog是属于MySQL Server层面的,又称为归档日志,属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑;
bin log 和 redo log 的区别
-
redo log是属于innoDB层面,binlog属于MySQL Server层面的
-
redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
举个例子:redo log记录是具体磁盘的修改,比如磁盘1的偏移为2的值为3 binlog记录的是sql语句比如update tb_user set age =1 where id = 2;
-
redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
-
binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用
-
两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而innodb存储引擎的
redolog在事务进行中不断地被写入,binlog不是随事务提交的顺序进行写入的。
undo log
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。
undo是在事务开始之前保存的被修改数据的一个版本。
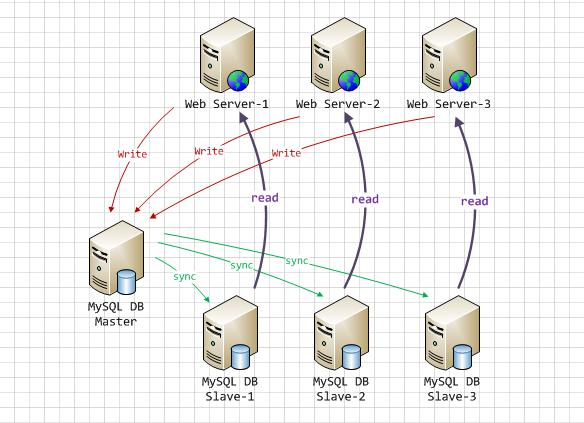
mysql的主从复制
原理
-
数据库有个bin-log二进制文件,记录了所有sql语句。
-
我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
-
让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
-
下面的主从配置就是围绕这个原理配置
过程
-
binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
-
从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
-
从库的SQL线程:从库创建一个SQL线程,这个线程从
relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从节点根据binlog文件和position偏移量来定位主从同步的位置,从节点保存偏移量,如果从节点发生宕机重启,那么会自从从position的位置发起同步。
从库在查询的时候,从库的状态
Master_Log_File — 上一个从主库拷贝过来的binlog文件
Read_Master_Log_Pos — 主库的binlog文件被拷贝到从库的relay log中的位置
Relay_Master_Log_File — SQL线程当前处理中的relay log文件
Exec_Master_Log_Pos — 当前binlog文件正在被执行的语句的位置

参考文献
[1]https://blog.csdn.net/u010002184/article/details/88526708
[2]https://blog.csdn.net/wanbin6470398/article/details/81941586
[3]https://www.cnblogs.com/wy123/p/8365234.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号