操作系统 の 进程和线程
操作系统
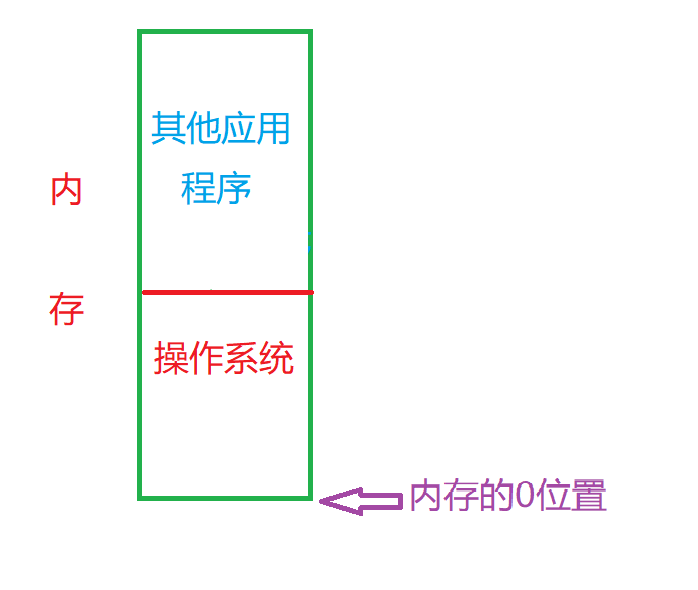
操作系统说白了,也是个程序,一开始的时候,操作系统相对于其他的应用程序。会优先加载到内存中,所以他加载到内存从0开始的位置,其他的应用程序将放到高位置的内存中。
操作系统接口
使用命令,相当于调用了 shell 程序,然后通过 shell 程序来运行程序。所以 shell是个程序,他调用了操作系统的接口。
调用系统的函数调用,称为 system_call。(系统调用)
常见的操作系统调用
| POSIX定义 | 描述 |
|---|---|
| fork | 创建进程 |
| execl | 运行一个可执行程序 |
| pthread_create | 创建一个线程 |
| open | 打开一个文件或者目录 |
| eacces | 返回值,表示没有权限 |
| mode_t_st_mode | 文件头结构:文件属性 |
操作系统的接口要符合国际规范,那么不同的应用程序开发完以后,就可以在不同的操作系统上运行
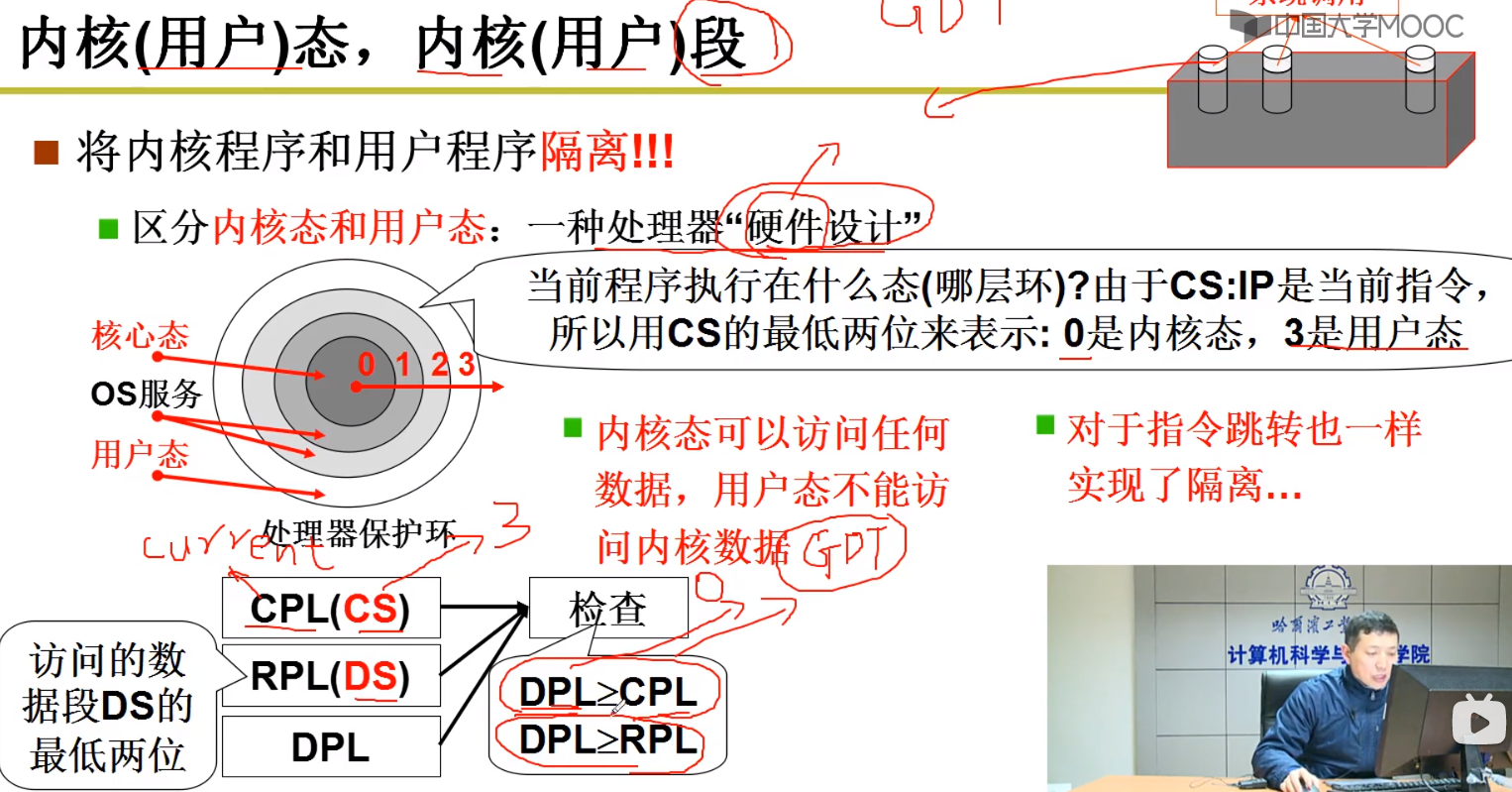
内核态和用户态,内核段和用户段
程序存在在内存中,是一段一段的存储的。内核段的内存执行在内核态下,用户段的内存执行在用户态下。用段的程序是不能访问内核段的。
为什么不让他访问
因为内存段里的东西,有很多敏感的信息,比如用户密码,所以不能让他访问。所以要进行隔离
如何不让他访问
计算机会给把内核段的优先级置0,用户段优先级置为3;数字越大,优先级越低。
计算机硬件通过设置 CPL 和 DPL 两个参数,cpl是当前内存段的优先级,如果优先级比要访问的低,那么就不能访问。
这是通过计算机硬件来完成的,让这两个段内的东西不能执行move操作和jmp操作。
要想访问怎么访问
计算机的硬件允许通过唯一的方法,即通过 中断指令 int 来进入内核。

进程
进程的状态
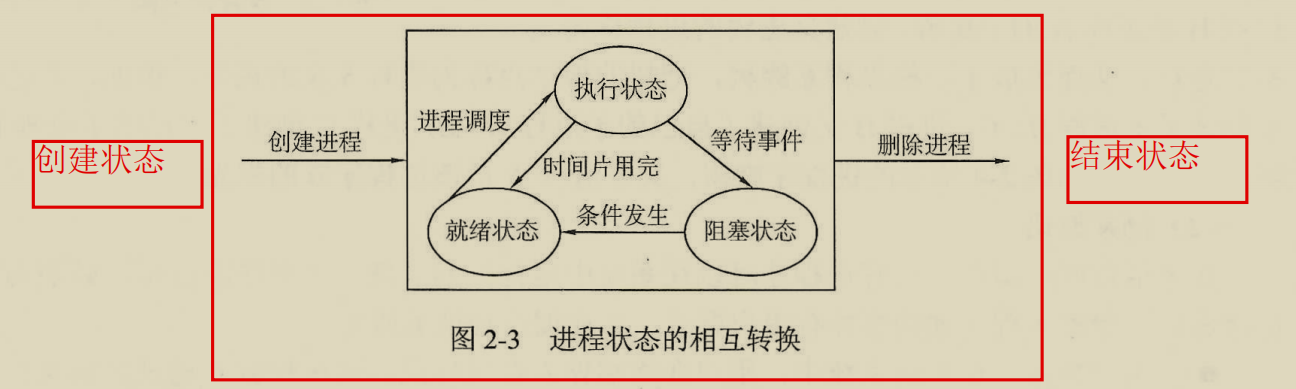
进程之间的状态转换多数情况下都是被动的,只有从执行状态到阻塞状态是程序自我行为,其他都是被动的。
进程切换的过程
- 保存和处理上下文
- 将上下文信息保存到 PCB 中
- 将进程的
PCB移入相应的队列,如就绪队列或者阻塞队列 - 选择另一个进程,更新其 PCB
- 根据 PCB 的内容,回复上下文信息
进程的切换
先看下面的一段程序
//程序 1
for i := 0; i < 10000; i++ {
a := i * 2
}
//程序 2
for i := 0; i < 10000; i++ {
a := i * 2
fmt.Println(a)//有IO操作
}
上面的两个程序,如果把运行时间打印出来的话,那么第二个程序的运行时间,大概是第一个程序的 10^6 倍,也就是一百万倍,这就说明了 IO操作非常的消耗时间。所以如果有下面的一段程序。

上面执行了一百万条指令,下面遇到了一条IO,那么就要等着,如果执行这一条IO的时间和执行一百万条的时间是相等的,显然这时候 cup 的利用率只有 50% ,而且想这样 100万 条记录才遇到一次IO操作的,已经算是非常理想了,正常情况下,都是 30条就遇到一条 IO,显然会让cpu的利用率过低。
那么显然要提高 CPU的利用率,可以不让他等待,而是直接跳过去
CPU的工作原理
CPU其实就是不断的 取指计算...取指计算...取值计算 的过程

mov 将数据送入寄存器
add a1 ,[100] 就是将地址100中的值存加到 a1 中
程序运行
当程序跑起来的时候,如果遇到了 IO 操作,那么就跳到别的程序去,但是再调回来的时候,需要记住跳出去的那一刻,当时已经跑成的样子,找个就是记录在 PCB 中,静止的代码是没有这种概念的,不需要保护运行时的状态,所以有了进程的概念。
如何保存现场呢?
其实就是把CPU寄存器里面的东西,直接挪到 PCB1 里去。
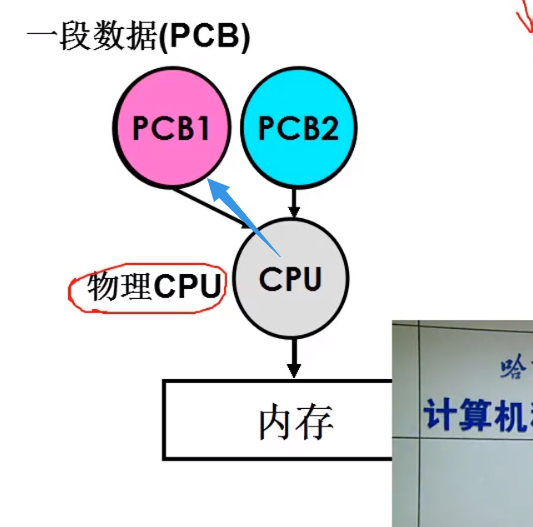
如何防止 进程1 的进程修改 进程2 内存中的数据呢?
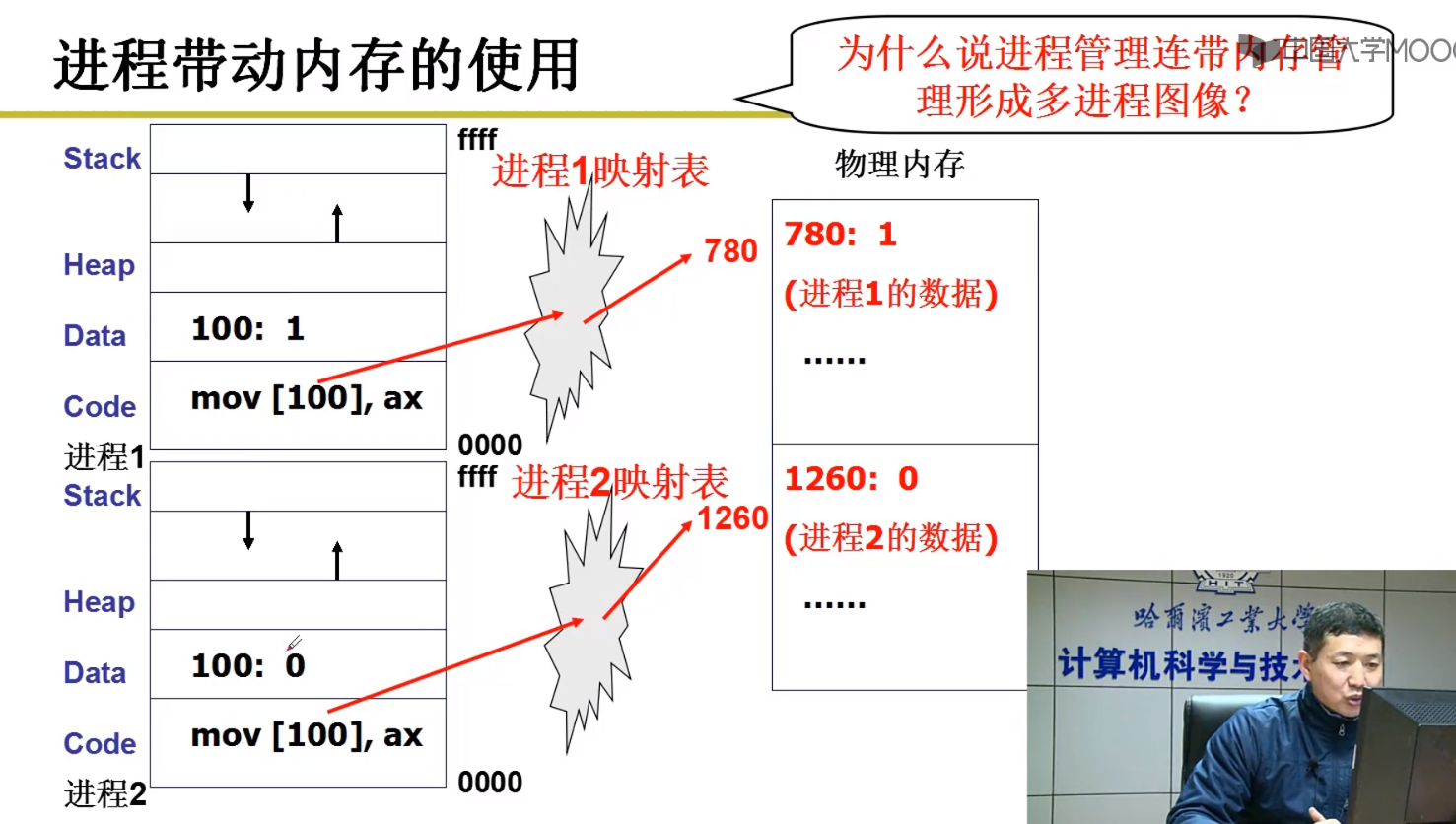
图六-映射表
答案是通过映射表,即 进程1要去地址为 100 的数据,进程2 也要处理地址为 100 的数据,那么这两个地址是否会冲突呢?其实是不会的,因为他们通过映射表以后,其实访问的更本就不是同一块地址,进程1访问的是 【780】,进程2 访问的是 【1256】内存。
多进程之间的合作 (同步)
为了让多进程之间可以合作,计算器划分了一块共享区域。
我们将产生数据的程序叫做 生产者程序、将使用进程的程序叫做 消费者程序。

如果多程序之间是顺序执行的话,肯定没问题,但是如果是有时候,程序1刚执行了一半就停了,程序2再执行,等程序2执行完了以后,程序1接着再执行,这样的话,其实程序就会乱了。比如下面。

如何解决这个问题呢?
出现这个问题的根本原因就是因为,cpu切换的时间不对,切换的太随便了,所以我们要让程序合理的推进,不能让 cpu 想切换就切换,一般使用的方法是给 counter上锁,消费者要检测counter锁,如果有锁,就不能向前推进。
用户级线程
用户级线程就是在用户态下执行的程序。
通过上图 图六映射表,可以知道,每个程序都对应一个映射表,也就是相当于他享有的资源。刚开始的时候,进程之间的切换,除了CPU 指令的切换,还要进行映射表的切换,就比较费时间,如果我们只是切换CPU的指令,而不去更换映射表,那么不就快了吗?所以我们把这种只切换 CPU 指令,而不切换 映射表 的操作,叫做 线程切换。
比如浏览器从服务器读取网页,他可以使用先下载文字,渲染这一部分,然后再下载图片,再渲染这一部分。这样下载和渲染交替着进行。如果整个的线程的切换,都是在用户态下执行的,那么这种线程就叫做用户级线程。
用户级线程的问题
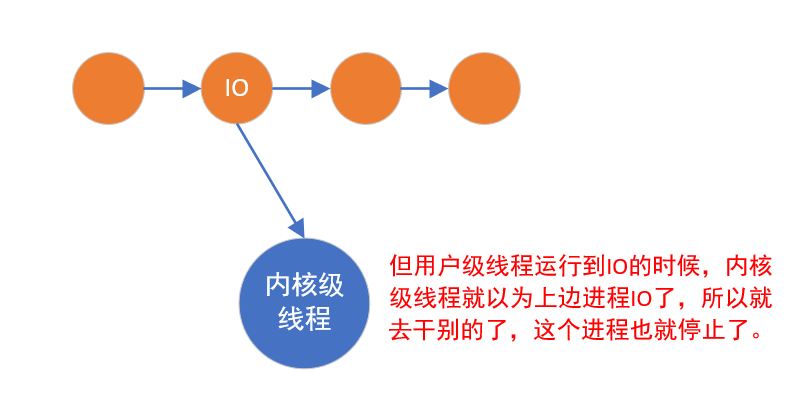
内核级线程
进程只有是内核级的,因为进程要分配资源,要访问文件等等,所以必须是内核级的。
内核级线程的作用
现在的电脑都是多核处理器,多核处理器。通过下面的图,看看多处理和多核的区别,多处理器,是每个处理器对应一个映射表,多核是使用一套映射表,所以只有使用了 内核级的多线程,才能发挥多核CPU的价值
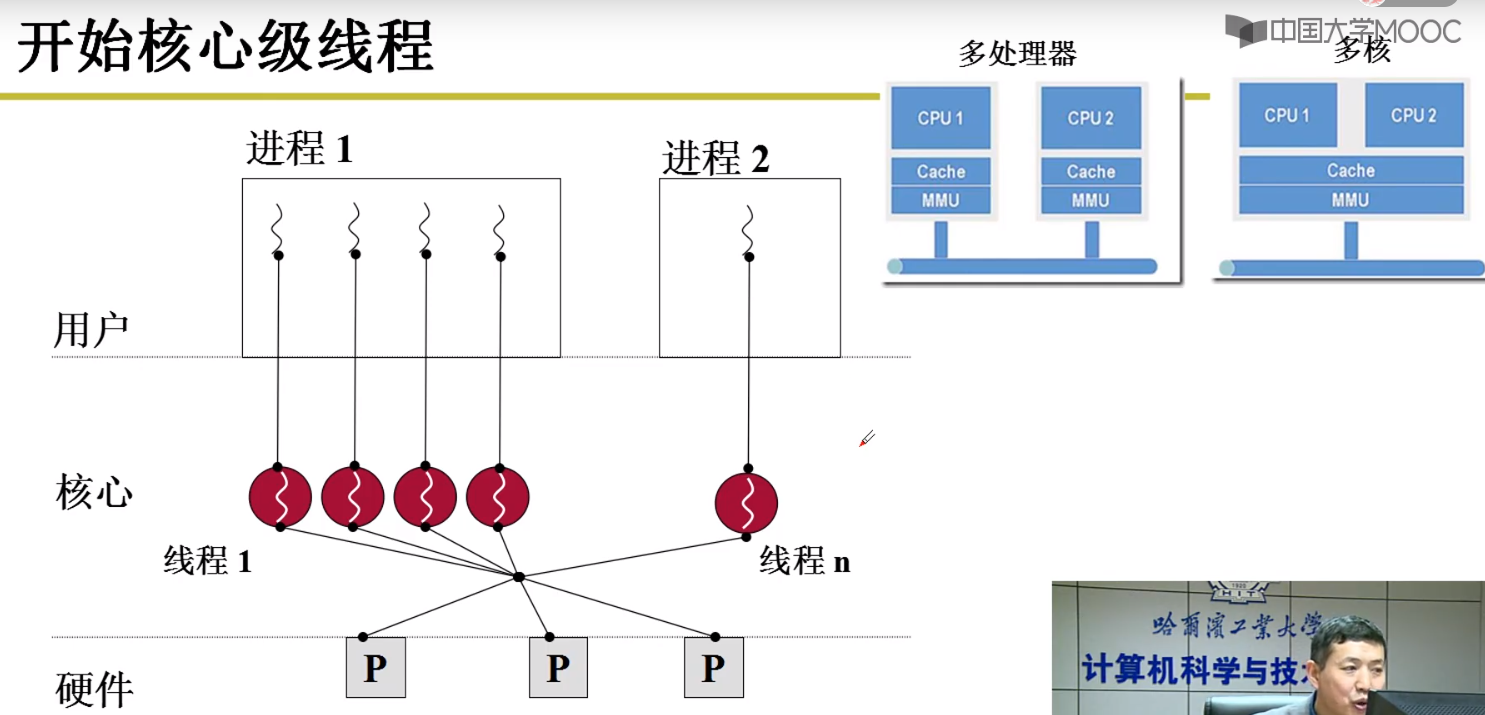

CPU的调度进程
CPU调度就是决定将 CPU 分配给哪个进程。也就是从就绪队列中选择哪个进程进行执行
如何让进程满意
- 周期比较短。(从任务进入到任务结束)
- 相应时间段。(从操作发生到相应),比如world,输入一个字,就要在屏幕上显示
- 系统内耗小,即吞吐量大,(进程切换等做无用功的时间时间比较短)
吞吐量和相应时间之间的矛盾
响应时间短 => 切换次数多 => 系统内耗大 => 吞吐量小
前台任务和后台任务的关注点不同
- 前台任务关注相应时间
- 后台任务关注周转时间
IO约束型任务和CPU约束性任务的特点
-
IO约束性的任务,一般切换比较多,每次执行的时间比较短,比如world。
-
CPU约束性的任务,一般切换比较少,每次执行的时间比较长,比如后台任务,mantlab后台运算。
常见的调度算法
-
先到先执行
-
短作业优先。让短的先执行,会提高短的周转时间,从而让短的满意了,就让整体的都满意了。
-
时间片轮转调度
word很关心相应时间,而 gcc(编译) 更关心周转时间,两类任务同时存在怎么办?
从系统中,维护两个任务队列,对于前台任务,选用 轮转调度、对于后台任务,选用 短任务优先调度,两个中间,两个任务队列中间,选用优先级调度。先优先调用前台任务,后调用后台任务。
- 前台任务: 前台任务
- 后台任务
问题: 但是如果死板的使用优先级调度,那么就会导致线程饥饿,
一个故事,1973年关闭的MIT的 IBM7094时,发现有一个进程在 1967年提交,就一直未运行过。
Linux0.11的调度函数(schedule)
大概的写写
for{
找出最大的conut,也就是优先级最大的进行执行
找到最大的 c,就跳出
}
for {
没经过一次,阻塞的队列中,经历的for循环越大,就会 conut+=count/2
}

总结一下linux 0.11调度函数的优点
- counter保证了相应的边界,即每次+原来的值除二,就会保证最大是 2p
- 经过 IO 以后,counter就会变大,IO时间越长,counter就会越大。
- 后台进程一直按照counter轮转,保证了最短优先,因为都是一轮一轮的运转,肯定时间最短的最先执行完
- 每个进程都只维护了一个 counter变量,简单高效。
进程同步和信号量
如何合理的利用信号量,实现进程之间有序合作,合理推进。
什么叫同步,就是 等待和唤醒

直观点来理解:司机要想开车,不是什么时候都可以开的,他要等一个信号,要等售票员给说一声 “人都上来了” 这样的一个信号。
同样的,售票员把票都卖完了,他要个司机发一个信号,告诉他可以走了。
所以多进程的相互协作,要有一个进程发信号,一个进程接收信号
需要让 “进程走走停停”来保证多进程合作的合理有序。

信号量(从信号到信号量是一个大的进步)
设定一个资源可用数量的值,sem ,
sem = -1 # 表示缓冲区满了,而且有一个在等待
sem = 0 # 表示缓冲区正好满了
sem = 2 # 表示有两个资源可用使用
为更加深入的了解 sem 的含义,请看下面的例题:
一种资源的数量是 8 ,这个资源对应的信号量的当前值是 2 ,那么说明()
A . 有两个进程等待这个资源
B . 有两个资源可以使用
C . 有六个进程等待这个资源
D . 有六个进程可以使用
答案选择:B
如何通过信号量来控制共享文件


注意:生产者生产资源,消费者消费资源
P 操作就是消费资源
V 操作就是生产资源 。这两个是荷兰语,没有什么原因,就是这两个单词。
使用 生产者、消费者 的角度来了解。
-
生产者生产了资源,那么对应的
sem就要 +1 ,如果满了。那么生产者就要等待了sleep了。如果此时发现sem=-1,那么就要唤醒一个阻塞的进程 -
使用消费者,每使用一次,那么对应的,
sem-1。 -
同样的,还有互斥锁
mutex,当要更改共享资源的时候,要加互斥锁,改完以后,释放掉锁。
使用临界区保护信号量
信号量为什么需要保护呢?
原因在于,我们要想让程序依赖信号量,实现程序的有序进行,那么就必须要保证,信号量他的数字是正确的。 可是当一段程序还没有执行完,就因为时间片用完了,而切了出去,这样的话,就会导致问题。

如何保护 sem 的正确性
换句话说,其实很像数据库的 原子性,就是要么一个程序不修改,要么就都要修改完,其实就是加了一个互斥锁。

临界区
什么叫做临界区;如下图,比如说 A程序的 20-30行代码,还有B程序的 35-40 行代码 ,这两部分的代码,都要修改同一变量,那么这两行代码,就属于临界区代码。 即 A 运行这段代码的时候, B 不能再运行这段代码了。

如何对临界区进行保护
有硬件算法和软件算法两种。软件主要使用面包店算法,硬件主要使用加锁,保证他的原子性。
面包店算法
面包店算法依旧是标记和轮转的结合。
如何轮转
每个进程都会获得一个序号
如何标记
进程离开的时候,序号为0,不为0的序号即为标记
面包店: 每个进入商店的客户,都会获得一个号码,号码最小的先得到服务,号码相同的时候,名字靠前先得到服务。
使用邻接保护,就是为了保护 sem的值,所以 sem的执行,一定要报过在 面包店算法里面。

硬件算法
硬件算法,就是使用用一个硬件来保护,其实根本的目的,就是把 修改sem的时候,保护原子的值,这是使用原子指令,瞬间就锁上了。其中没有任何其他的可能。
死锁
我们将多个进程 互相等待对方持有的资源 而造成谁都无法执行的情况,叫做死锁。
可以借助下面的一张图来理解这个过程。
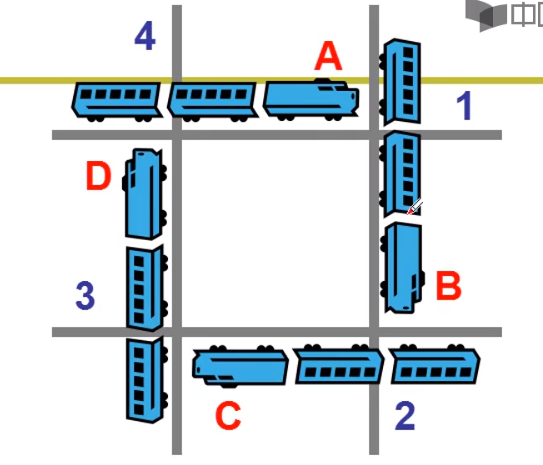
死锁形成的四个必要条件
- 互斥使用;
- 不可抢占;资源只能自己主动放弃
- 请求和保持;进程必须占有资源,同时再去申请资源
- 环路等待;资源分配图中有一个环路
死锁处理方法(用火灾来举例子)
| 处理方法 | 火灾例子 | 操作系统操作 |
|---|---|---|
| 死锁预防 | 预防火灾 | 破坏死锁出现的条件 |
| 死锁的避免 | 安装煤气超标检测,自动切换电源 | 检测每个资源请求,如果造成死锁,就拒绝 |
| 死锁的检测和修复 | 发现火灾的时候,立刻拿起灭火器 | 检测到死锁,让进程回滚,让出资源 |
| 死锁忽略 | 站在太阳上,对火灾全然不顾 | 就好像没有死锁一样 这种方法可以用在PC机上,程序卡了,重启一下就好了,但是如果是在常年不关机的服务器上,这么弄肯定不行 |
预防死锁的几种方法的详解
死锁预防
可以在进程执行前,一次性申请所有所需的资源,但是这样,编程的难度太大,而且很多资源在分配后,很长一段时间才会被使用,资源的利用率低。
死锁的避免
启动银行家算法,查看是否所以进程,存在一个可完成的执行序列 P1、P2、P3,则称系统处于一种安全状态。
银行家算法,其实就是找一个是否可执行的序列。但是这种做法,其实就是非常复杂的,他的复杂度为 O(mn2),非常的麻烦。
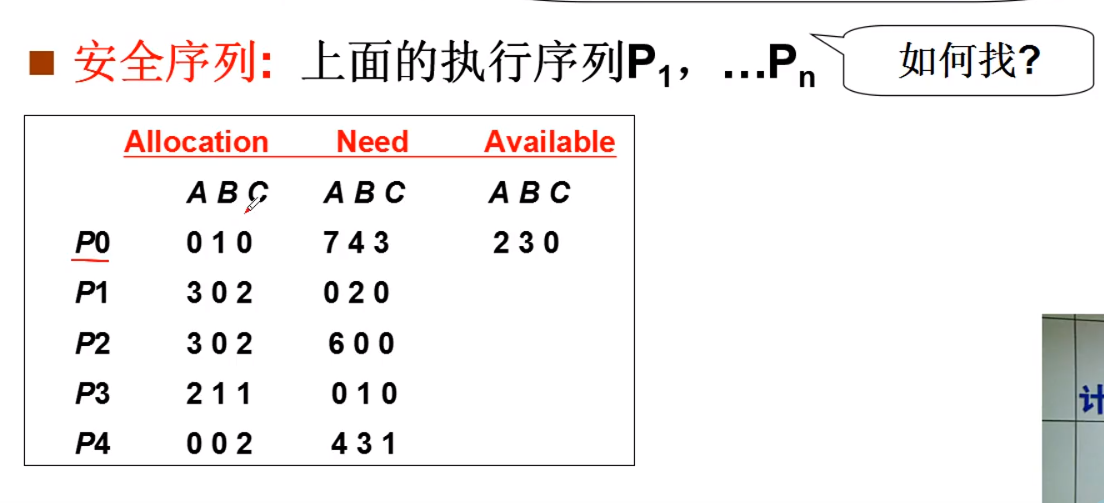
死锁的检测和恢复
如果每次执行程序的时候,都执银行家算法,效率太低了,所以 只有当发现资源的利用率比较第低的时候,再检查程序中是否有死锁,如果有死锁的话,就选择某一个进程,让他回滚,但是如果程序已经对资源进行了更改,这样的话,再进行回滚就会非常麻烦
死锁忽略
在许多的通用的操作系统上,比如在 PC 机上安装的 windows 和 linux 都采用了死锁忽略的方法,原因
- 死锁本来就是小概率事件。
- 死锁忽略的代价比较小
- 死锁预防让编程变得困难
- 死锁可以用重启来解决,PC 重启造成的影响小
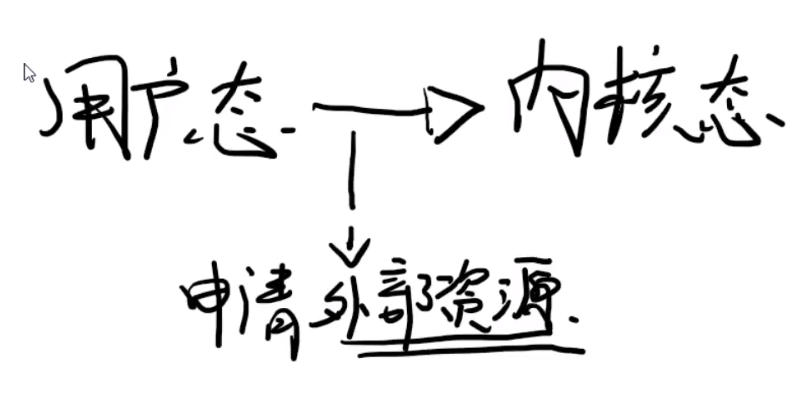
内核态和用户态
什么时候,程序会从内核态,切换到用户态,就是当申请外部资源的时候
什么是申请外部资源
- 系统调用
- 中断(比如,虚拟内存在查询的时候,发现没有映射到物理内存上,就会发生缺页中断)
- 异常
什么时候从内核态返回到用户态呢?
就是当内核态的程序执行完的时候,就会切回到用户态。
系统调包括(linux 系统下,可以通过 man systemcall 来查看)
- 进程
- 文件
- 设备
- 信息
- 通信
参考文献
https://www.bilibili.com/video/BV1d4411v7u7?p=20&share_source=copy_web

 浙公网安备 33010602011771号
浙公网安备 33010602011771号