Go map存储原理
map 基础操作
map 的声明
m := make(map[string]int, 2)
m["hah"] = 15
m["mmm"] = 20
m["wwm"] = 30
m["wsegewwm"] = 40
fmt.Println(len(m)) //输出是 4,输出的会是总长度
m := map[string]int{}
m["hah"] = 15
m["mmm"] = 20
m["wwm"] = 30
m["wsegewwm"] = 40
fmt.Println(m)
使用 fmt.Printf("%T", m)输出类型的话,上面两种输出的结果都是一样的。
func main() {
m := make(map[int]string, 0)
m[1] = "a"
F1(m)
fmt.Println(m)
}
func F1(m map[int]string) {
m[2] = "b"
}
// 输出矩阵 map[1:a 2:b]
// 这说明map是地址,可以直接传值。
注意: 输出 map 中的键值对的个数
len 中输出的是键值对的个数,而不是容量的个数。
a := map[string]int{"15": 15, "16": 16, "17": 17, "18": 18, "19": 19}
fmt.Println(a)
fmt.Println(len(a))
删除某个 key
a := make(map[string]int, 5)
a["王"] = 12
fmt.Println(a)
delete(a, "王")
fmt.Println(a)
查看 key
for k, v := range a { // 同时查看 key ,value
fmt.Println(k, v)
}
for k := range a { // 只查看 key
fmt.Println(k)
}
前提:键不重复,可哈希
v1=make(map[int]int)
v2=make(map[string]int)
v3=make(map[[2]int]int)
v6=make(map[bool]int)
v4=make(map[[]int]int) // 不行,可以是数组,但不能是切片
v5=make(map[[2][]int]int) //会报错
v5=make(map[[2]map[string]string]int) //会报错
底层的原理
1.1 hash的基本存储原理
用 拉模 + 拉链法 来快速了解 hash 表的存储原理
所有的语言里,hash的基本原理都是这样计算出来的,只不过是在不同的语言里,进行了不同的改进。
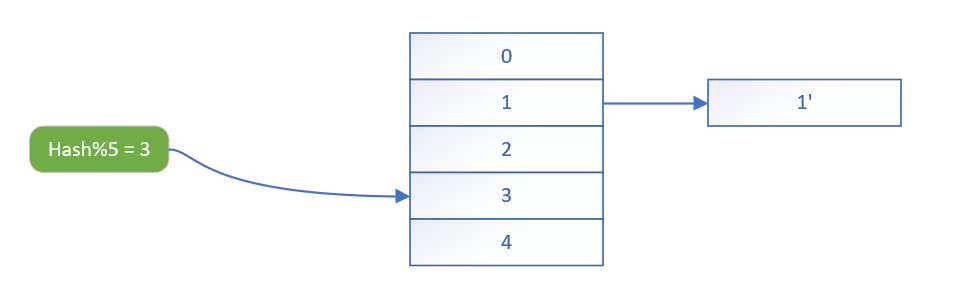
这是 Python 或者 go 中,对
map这种存储类型的基本原理,但是每种语言中,针对自己的语言特点,都进行了进一步的优化。
Map的整体存储结构
其核心是由 hmap 和 bmap 两个结构体实现的。
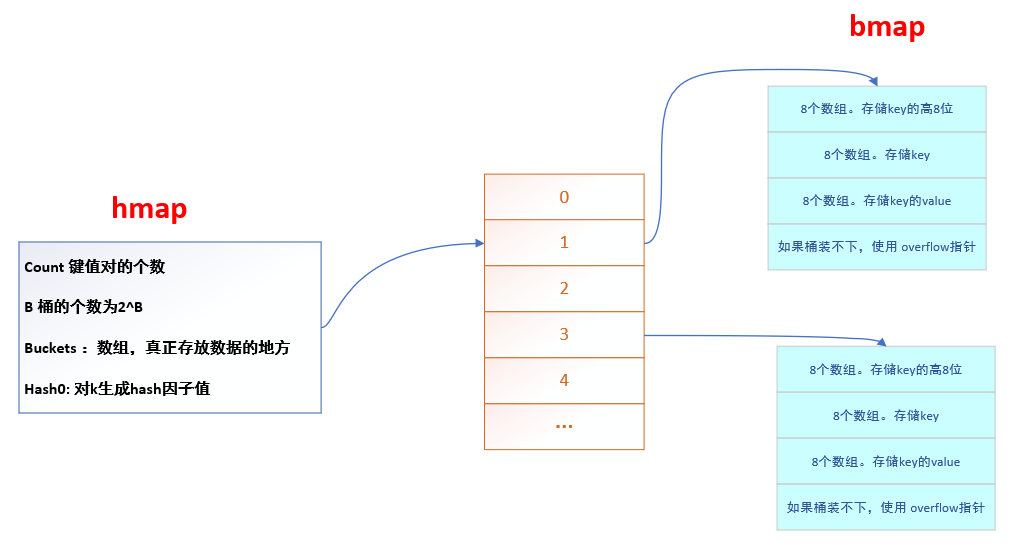
hmap的结构
每新建一个 map,都对应一个 hmap 的结构体,其结构如下
| 属性 | 含义 |
|---|---|
| count | 键值对的个数 |
| B | 桶的个数为 2 的 B 次方 |
| buckets | 当前 map 中桶的数组,是个数组,真正存数据的地方 |
| hash0 | 对于k生成哈希因子值 |
此处的 B 是根据某种算法规则得出的,具体的计算比较麻烦,会进行各种比较,可以通过看源码了解这部分内容。
map会会根据 B 去创建桶的个数,具体的计算规则如下
- B<4 的时候,桶的个数为 2B 标准桶
- B>4 的时候,桶的个数为 2B + 2B-4 标准桶+溢出桶
bmap结构
| 属性 | 含义 |
|---|---|
| tophash | 存储hash值的高八位 |
| keys | 存储字典的key |
| values | 存储字典的 values |
| overflow | 指针,当桶存不下的时候,创建的溢出桶 |
overflow是指向溢出桶的指针,每个桶最多可以承载八个键值对,如果不够,就要使用溢出桶,overflow就是指向溢出桶地址的指针。
举个例子
// 初始化一个可容纳 10 个元素的map
info=make(map[string]string,10)
-
第一步:创建一个
hmap结构体对象 -
第二步:生成一个哈希因子
hash0并赋值到hmap对象中(用于后续为 key 创建哈希值)。 -
第三步:根据
hint=10,并根据算法规则来建立B,当前B应该为 1.一个桶存8个数,所以两个桶就够了,即key的1次方
| hint | B |
|---|---|
| 0-8 | 0 |
| 9~13 | 1 |
| 14~26 | 2 |
| ...... | ..... |
- 第四步:根据
B去创建桶(bmap对象),并存放在buckets数组中,当前的bmap的数量应该为2
写入数据的过程
-
结合
哈希因子和key生成哈希值 -
获得哈希值的
后B位,并决定该值放在哪个桶中,看准是后B位,不是后8位 -
上一步确定以后,接下来就在桶中写入数据
- 第四步:
hmap的个数count++map中的元素+1

读取数据的过程
- 结合哈希因子和
键,生成哈希值 - 根据哈希值的后
B位找到应该放到哪个桶里。 - 找到桶以后,再根据
tophash高八位去查找数据 - 如果没有找到,再去
溢出桶中去找
map 的扩容
两种情况下会引发扩容
-
map中数据总个数/桶个数 > 6.5,引发翻倍扩容;(这个很好理解,因为一个桶最多装8个,现在已经放超过6.5个了。需要翻倍扩容) -
使用了太多的溢出桶 (溢出桶太多,会导致map处理速度降低)
-
B<=15,已使用的溢出桶个数 >=2B,时,引发等量扩容 -
B>15,已使用的溢出桶的个数 >=215,引发等量扩容
-

迁移的过程
- 如果是翻倍扩容的话,迁移规则就是将旧桶中的数据分流到两个桶中(比例不一样),并且桶编号的位置为:同编号位置 和 翻倍后对应的编号位置。

- 等量扩容的话,溢出桶太多引发的扩容,那么数据迁移机制就会比较简单,就是将旧桶中的值迁移到新桶中,这种迁移的目的就在于让数据更紧凑,从而减少溢出桶。
总结:
翻倍扩容,就是数据太多了,桶不够用了,解决方式就是把桶的个数x2。
等量库容,就是数据不多,桶也够用,但是太松散了,溢出桶太多。解决方式新生成一个hash因子,重新分配一下。
hash数组的长度
根据数学中的位运算的思想处理。
func main() {
a := 1 << 3
b := 199
fmt.Println(b % a)
fmt.Println(b & (a - 1))
}
hash数组长度为什么需要是2的指数
-
最简单的映射算法就是取模
hash%length,但取模效率不如位运算效率高,所以使用位运算求索引位置hash&(length-1) -
为了减少位运算带来的哈希冲突,将数组长度控制为
2^n,这样hash值始终在和一个大部分数字都为1的值做与运算,那么就有更大的可能性不会发生冲突
2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1
-
因为在与运算中,如果一个数全为1,那么结果完全取决于另一个数,而这里的另一个数就是指hash算法求出的hash值(唯一),这样就大大减少了冲突可能性
-
想像一个极限情况:数组无限大,并且全为1,那么就一定不会发生冲突,因为hash值都不相同

 浙公网安备 33010602011771号
浙公网安备 33010602011771号