Mysql 索引的原理
索引的数据结构
索引是一种排好序的数据结构,比如排好序的二叉树,
几种可供选择的索引树
- 二叉树
- 红黑树
- Hash 索引
- B+ 树
B树和B+树的特点
B树的特点:
-
节点排序
-
一个节点可以存多个元素,多个元素也是排好序的。
B+树的特点:
-
有
B树的所有特点 -
叶子节点之间有指针
-
非叶子节点上的元素在叶子节点上都用冗余,也就是叶子节点存储了所有的元素,并且是排好序的。
为什么要用 B+ 树
因为之前其他的几种树,如果数据量过大的话,都会导致树的高度变高,树高度,就相当于是 IO 交互的次数,因为真正的数据是存储在磁盘上的。
可以看出来,树的高度越高,需要交互的 IO 就越多,那么在数据不变的情况下,要想降低树的高度,唯一的做法就是扩大一个节点的宽度了。
在B+树中,mysql规定一个节点是 16kB,大概可以存储 1100 多个索引,而最后一层,因为要存储索引还要真正对应数据的地址,所以占的内存比较多,只能存储 16个字节,所以,总数为大概 2千万的数据。只需要三次 IO,甚至 B+ 树中,比较顶层的节点直接存储在内存中,使查询更快,如下图
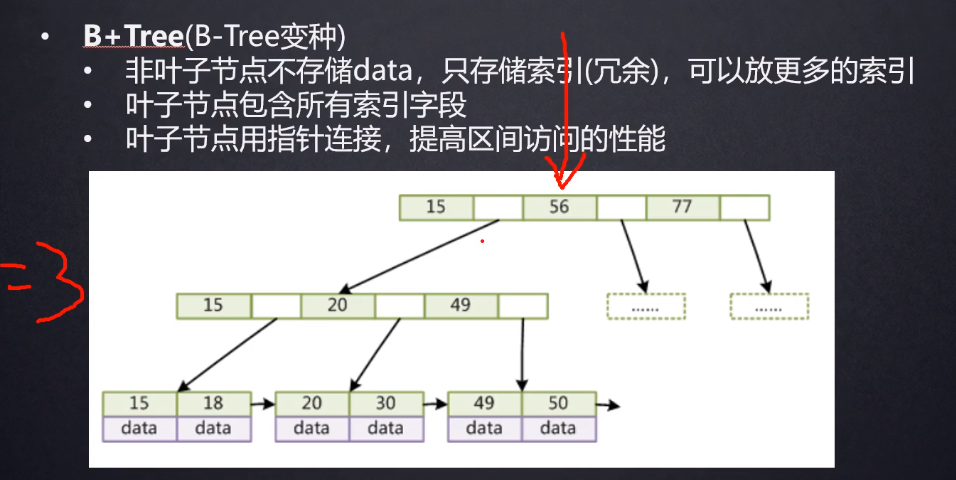
为什么不用hash呢?
因为使用 hash 的确可以更快的进行 等值查找,但是对于 范围查找,显然就无能无力了,因为 hash 的存储结构是无序的,那么他的下一个储存位置,未必是他下个要找的值。
聚集索引和非聚集索引
聚簇索引:
数据必定是跟某个索引绑定在一起的,绑定数据的索引叫做聚簇索引。
其他索引的叶子节点中存储的数据不再是整行的记录,而是聚簇索引的 id 值。
优势:聚簇索引可以直接获取数据,相比于非聚簇索引需要二次查询的效率要高
劣势:维护索引比较昂贵,特别是插入新行和主键被更新,再者就是使用 UUID 作为组件的话,会导致数据存储变得稀疏。所以需要调整表的结构
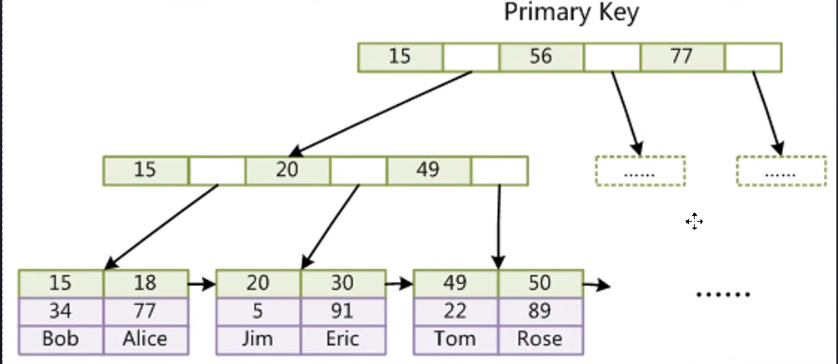
非聚簇索引
叶子节点不存储数据,存储的是数据的行地址,也就是说,根据行的位置,再去磁盘中查找数据,
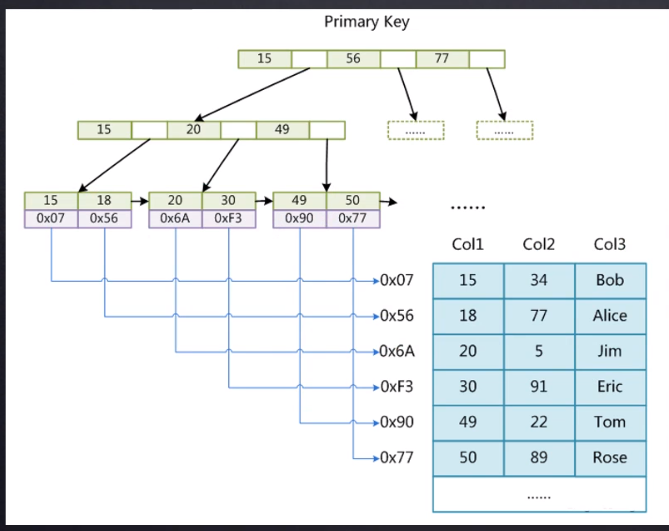
回表 - 覆盖索引 - 最左匹配 - 索引下推
回表:
使用了 select * 这种写法,在普通索引中先查询到匹配对应的叶子节点,查询到对应的行记录的 id 值 的时候,再根据 id 去聚簇索引的 B 树中去查询,这个过程称之为 回表。
覆盖索引:
在某些场景中,可以考虑将要查询的所有列变成组合索引,此时就会使用覆盖索引,加快查询效率。
最左匹配原则:
创建索引的时候,可以选择多个列共同组成索引。此时叫做组合索引,或者联合索引,要准许最左匹配原则。就像写信的时候,要先写省再写市,最后写县。
-- 在表中根据 name 和 age 两列建立索引。
select * from table where name = 'zhangshan' and age =12; -- 会走索引
select * from table where name = 'zhangshan' ; -- 会走索引
select * from table where age =12; -- 不会走索引
select * from table where age =12 and name = 'zhangshan' ; -- 他查询出来的结果和第一行是一样的。mysql有个内部的优化器,会走索引。
索引下推:
为什么推荐整型的自增主键,而不是GUIG?
要了解这个问题,首先要看一下,B+树的底层结构
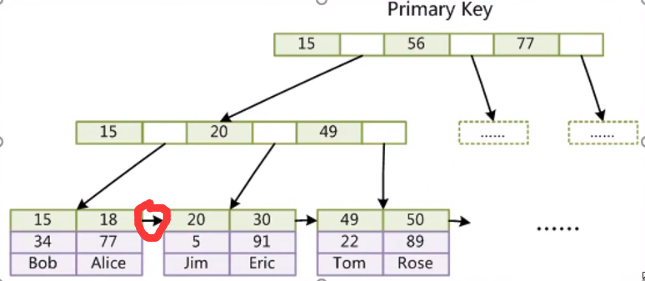
- 他的叶子节点,之间是有双向指针的,而且是按照顺序排好的
- 他上面的索引,也都是按照顺序排好的
所以为什么用整型呢?
因为在查找的时候,要对排好序的索引,进行每个比较,显然比较 int 要比比较 字符串快的多
为什么要自增呢?
因为本来的 B+ 树就是排好序的,这个时候你要 INSERT 插入一个,如果是是自增的话,直接插入到最后就行了,但是如果是非递增的,那就有可能要插入到原来的队列中,还要进行比较和树的调整,显然直接插更快。
复合索引
一般在工作中,单值索引其实是用的比较少的,大多数情况下,都是使复合索引,结构如下图
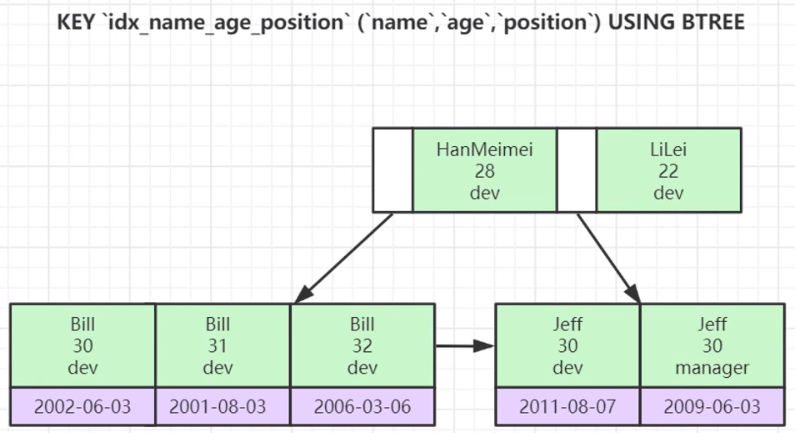
从上图可以看出,如果索引是按照 (name , age , position ) 这种顺序建立的,那么他会先按照 name 排序,如果 name 相同,再按照 age 排序。
调优
Mysql 的性能瓶颈
- CPU 饱和
- 磁盘IO,一般发生在要装入的数据远大于内存容量的时候
- 服务器已经问题
- SQL 写的有问题,使用 (explain)查看
如何避免索引失效,写查询 sql 要遵守的原则
- 全值匹配我最爱
- 最佳左前缀原则
- 不在索引列上做任何计算
MySql的慢查询如何去优化
工作中,一般的优化并不是等问题出现了,我们才去进行优化,而是在进行数据库建模和数据库设计的时候,就已经优先考虑到一些优化问题,比如表字段的类型、长度等等。包括创建合适的索引等等,但是这种方式只能提前预防,并不能解决一切问题,所以我们要在sql出现了问题以后,,从数据库的性能监控、索引的建立和维护、sql语句的调整、参数的设置、架构的调整等多个方面进行综合的考虑。性能监控使用 show profiles,performenace_schema 来进行监控,索引。。参数。。。。
-
检查是否走了索引,没有的话,则优化
SQL利用索引。 -
检查所利用的索引,是否是最右索引。
-
检查所查字段是否都是必须的,是否查询过多字段,查出多余数据。
-
检查表中的数据是否过多,是否应该进行分库分表了。
-
是否是服务器硬件太差了。
如何保证 Redis 和 MySql 的数据一致性
-
先更新 mysql,再更新
redis,但是如果redis更新失败,那么依然可能会有不一致的问题。 -
先删除
redis,再更新mysql,等再查询的时候,再把数据缓冲到redis中,但是在高并发的时候,这样做依然会出现问题。比如线程1删除了redis,然后又更新了mysql,此时又有一个线程进行了查询,将旧的数据又重新查回到redis中了。 -
延迟双删: 先删除
redis中的数据,然后再删除mysql中的数据,延迟几百毫秒以后(这里的时间等待,是为了要等mysql的主从复制等相关进程),再删除redis的数据,这样即使其他线程读到了数据并更新到了redis中,也会被删掉,从而保证了数据的一致性。
参考文献
https://www.bilibili.com/video/BV18f4y1U7pe?p=8&share_source=copy_web
https://www.bilibili.com/video/BV1KW411u7vy?p=34&share_source=copy_web

 浙公网安备 33010602011771号
浙公网安备 33010602011771号