数据库 の mysql(二)基本操作
文章目录
操作数据库可以大概的分为这么几个层次
- 操作数据库
- 操作数据中的表
- 操作数据库中表的属性
mysql 里面的关键字不区分大小写
一. 操作数据库
1.创建数据库
如果不存在,那么就可创建了。
CREATE DATABASE [IF NOT EXISTS] westos
2.删除数据库
如果存在数据库,就删除。
DROP DATABASE [IF EXISTS] westos
3.使用数据库
USE `school`
tab 按键的上有一个表明或者是字段名,需要带 ·· 用来区分关键字
4.查看数据库
SHOW DATABASES
注意 databases 是复数的
二 . 数据库的列类型
数值:
- tinyint 十分小的数据 1字节
- smallint 较小的数据 2个字节
- int 标准的整数 4个字节
- float
- double
- decimal 字符串形式 的浮点数,一般金用 decimal
字符串
- char 字符串固定大小 0-255
- varchar 可变字符串 0-655535 常用的 string
- tinytext 微型文本 2^8-1
- text 文本串 2^16-1 保存大文本
时间日期
date YYYY-MM-DD 日期格式
time HH:mm:ss 时间格式
datetime YYYY-MM-DD HH:mm:ss 最常用的时间格式
timestamp 时间戳 1970 年 1 月 1 日到现在的毫秒数
year 年份
空类型
null 不要进行数值运行,因为无论怎么算都是 null
三. 数据库的字段属性(重点)
也就是具体看看,下边的表都是干什么用的?
创建表时,应该选择的 字符集 和 核对


Unsgned:
- 无符号整数
- 声明了该类不能声明为负数
zerofill:
- 0 填充
- 不足位数,可以使用 0 来填充。
- 比如 int(0) , 5—005
自增
- 默认在上一条的记录上 +1 (默认)
- 通常用来设计唯一主键 index ,必须要求是整数类型。
- 可以自定义设计逐渐自增的初始值和步长
非空 null 和 not null
- 假设设置为 not null ,如果不给它赋值,就会报错。
- Null ,如果不填写值,默认就是 null
默认:
- 如果不指定值得话,就会设置为默认的值
- sex ,默认为 男,如果不指定该列的值,则会有默认的值
按照阿里巴巴的数据库要求,一遍的都要有这些个字段
id 主键
·version· 乐观锁
is_delete 伪删除
gmt_create 创建时间
gmt_update 修改时间
注意:
int 类型的话,后面指定的 长度,其实是可以随意长的,那个长度只是他显示的长度
四.表的操作
create table [if not exists] `表名`(
`字段名` 列类型 [属性] [索引] [注释]
`字段名` 列类型 [属性] [索引] [注释]
)[表类型] [字符集设置]
CREATE TABLE IF NOT EXISTS `students`(
`id` INT(4) NOT NULL COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT('匿名') COMMENT "姓名",
)ENGINE=INNODB DEFAULT CHARSET=utf8
五. 数据库引擎
分为很多种,但是常用的就是两种:
- INNODB: 现在默认使用的
- MYISAM: 这个是5.0之前的版本使用的
| MYSAM | INNODB | |
|---|---|---|
| 事务的支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大 |
数据行锁定是一行锁住,而不是表锁
外键约束,在数据库级别关联另一张表
常规使用规则:
- MYISAM 节约空间,速度较快
- INNODB 安全性高,事务的处理,多表多用户操作
物理存储空间
所有的数据库文件都存在于data 目录下:
本质还是文件的存储
注意点:
- 字段名使用 ``
- sql 关键字大小写不敏感,建议大家使用大小写(因为容易识别)
- 所有的符号都必须使用英文
六. 数据库管理
5.1外键:
纪老师讲的文件夹就很容易理解这个问题,外键就指的上一个文件夹的名字,比如有个班级文件夹,有个班长文件夹,那么,这个班长文件夹就应该在班级这个文件夹,也就是他爸是谁,那么班长这个表就应该是有 外码 的找个表。
5.2去重:
发现重复数据,然后去重。
select from result --查询全部的考试成绩
select `studentNo` from result -- 查询有哪些同学参加了考试
select distinct `studentno` from result --发现重复的数据,去重,只显示一条
六.复杂查询
6.1视图和表
视图究竟是什么呢?如果用一句话概述的话,就是“从SQL的角度来看视图就是一张表”。那么视图和表到底有什么不同呢?区别只有一个,那就是“是否保存了实际的数据”。视图实际上保存的是 SELECT 语句,笼统的说,视图可以使用任何的 select 语句,但其实只有一种情况例外,那就是不能使用 order by 子句。
6.2子查询和视图
子查询就是一张一次性的视图
七.集合运算
集合运算就是使用 两张 以上表的 SQL 语句,通过以行方向(竖)为单位的集合运算符和以列方向(横)为单位的联结,就可以将分散在多张表中的数据组合成为期望的结果。
7.1重点:
- 集合运算就是对满足同一规则的记录进行的加减等四则运算。
- 使用UNION(并集)、 INTERSECT(交集)、 EXCEPT(差集)等集合运算符来进行集合运算。
- 集合运算符可以去除重复行。
- 如果希望集合运算符保留重复行,就需要使用ALL选项。
7.2表的加法(UNION 并集)
加入数据库中有这样两张表:
表一:

表二:

执行 + 运算的代码:
SELECT product_id,product_name FROM product1
UNION
SELECT product_id,product_name FROM product2;
执行结果:

注意: 商品编号为“0001”~“0003”的 3 条记录在两个表中都存在,因此大家可能会认为结果中会出现重复的记录,但是 UNION 等集合运算符通常都会除去重复的记录。
7.3进行集合运算的注意事项:(不仅限于 union)
1.运算对象的列数必须相同:否则会报错

2.相同位置上的列的类型必须一致
例如下边:虽然列数相同,但是第二类数据类型不同,因此会报错(一个是数值类型,一个是日期类型)

3.order by 子句只能最后使用一次

4.包含重复行的集合运算
在 UNION 的结果中保留重复行的语法。其实非常简单,只需要在 UNION 后面添加 ALL 关键字就可以了

7.4 交集
交集就是把公共部分提取出来:
代码如下:

减法表
代码如下:

最后执行出来的结果就是,上个表减下个表:被减数和减数的位置不同,得到的结果也不同

八.联结(JOIN)
联结( JOIN) 运算,简单来说,就是将其他表中的列添加过来,进行“添加列”的运算
例如:

9.1内连接:
内联结( INNER JOIN),它是应用最广泛的联结运算。
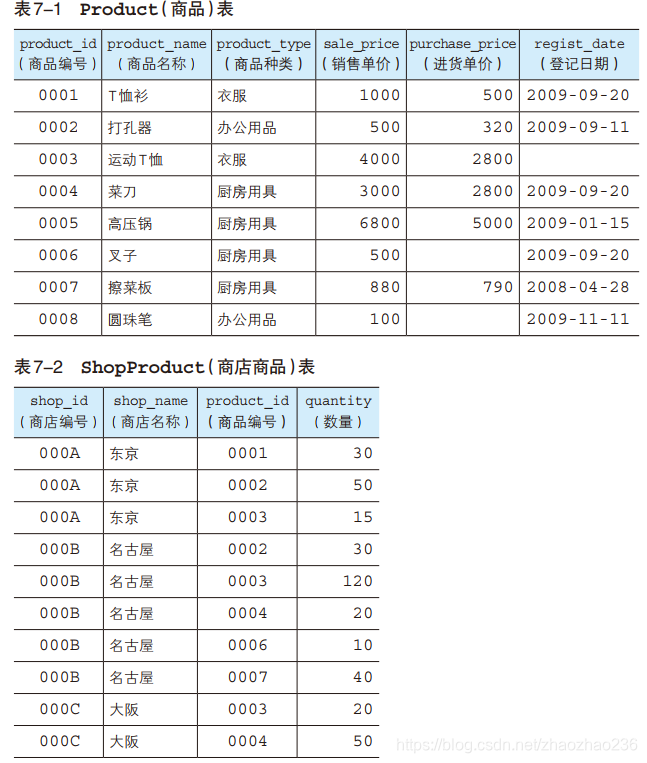
如上表所示,两张表中的列可以分为如下两类。
- A 两张表中都包含的列 → 商品编号
- B 只存在于一张表内的列 → 商品编号之外的列
所谓联结运算,一言以蔽之,就是“以A中的列作为桥梁,将 B中满足同样条件的列汇集到同一结果之中”
代码:
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name,
P.sale_price
FROM ShopProduct AS SP INNER JOIN Product AS P
ON SP.product_id = P.product_id;
需要注意:
- as 是别名,并不是必须的。
- 第二点要注意的是 ON 后面的联结条件(即连接健)
- 在 SELECT 子句中,像 SP.shop_id 和 P.sale_price 这样使用“< 表的别名 >.< 列名 >”的形式来指定列。和使用一张表时不同,由于多表联结时,某个列到底属于哪张表比较容易混乱,因此采用了这样的防范措施。
执行结果如下:
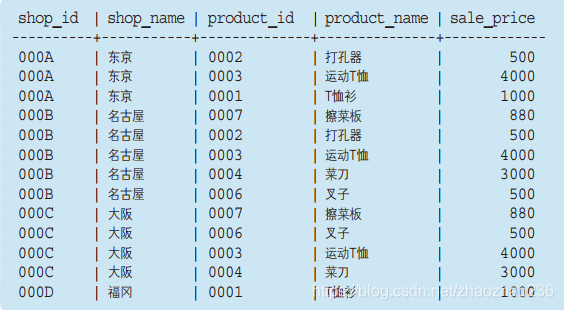
9.2外连接
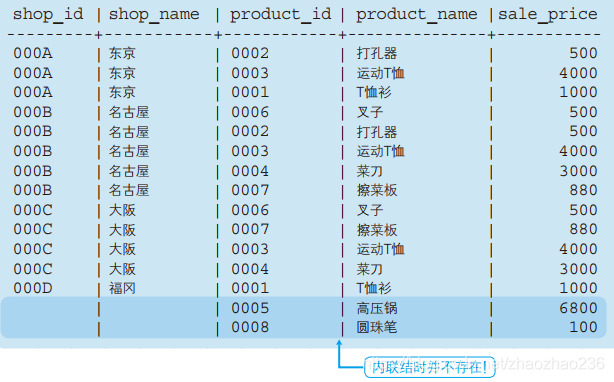
相比于外连接。内连接只能选出同时存在于两张表中的数据。反过来,对外联表来说,只要存在于某一张表中,就能够读取出来。
九.其他的相关概念
1.聚合查询:
需要对标进行汇总,然后进行的查询,比如,求总数,求平均值。
2.事务:
简单点来说。事务就是需要在同一个处理单元中执行的一系列更新处理的集合。
事务的特性:
- 原子性:要么全部执行,要么完全不执行
- 一致性: 指的是事务中包含的处理要满足数据库提前设置的约束,比如主键约束和非空约束
- 隔离性:隔离性指的是保证不同事务之间互不干扰的特性。该特性保证了事务之间不会互相嵌套。
- 持久性:使由于系统故障导致数据丢失,数据库也一定能通过某种手段进行恢复。
约束设置
- NOT NULL 约束,非空约束
- 把其设置为主键,也可以称之为 “主键约束”
8.1主从表:
主从表,从表数据依赖于主表,一般最后查询数据时把主表与从表进行关联查询。主表可用于存储主要信息,如客户资料(客户编号,客户名称,客户公司,客户单位等),从表用来存储客户扩展信息(客户订单信息,客户地址信息,客户联系方式信息等)
带主码的就是 主表 ,带外键的就是 从表 。
所有的表都应该有主键,再严格点说,如果没有主键的表就不能算是表!!
十. 概念模型
信息世界的一些基本的概念
- 实体:一个人,一个部门,一个学生,一门课,学生的一次选课。
- 属性:一个实体可以用若干属性来刻画。例如学生可以用学号、姓名。
- 实体型:例如:学生
- 实体集:例如:全体学生
实体内部的联系,通常指组成实体的各属性之间的联系
实体之间的联系,通常指实体集之间的联系
实体之间的联系,有一对一,一对多,多对多等多种类型
- 如果实体集 A 中的每一个实体,实体集 B 至多有一个实体(也可以没有)与之联系,反之亦然,则实体集 A 与 实体集 B 具有一对一联系
- 如果实体集 A 中的每一个实体,实体集B中,有 n 个实体(n>=0)与之联系,反之,对于实体集B中的每个实体,实体集A中,至多只有一个实体与之联系,则称实体集A与实体集B有一对多联系
- 如果实体集 A 中的每一个实体,实体集 B 中有n个实体(n>=0)与之联系,反之,对于实体集 B 中的每个实体,实体集A中也有m个实体(m>=0)与之联系。则称实体集A与实体集B具有多对多的关系
使用 实体-联系方法 来描述现实世界的模型概念,即 E-R 图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号