Mysql の 索引优化
一.单表索引优化
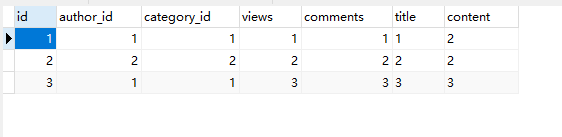
1.1建表:
1.1建表
CREATE TABLE `article` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`author_id` int(10) UNSIGNED NOT NULL,
`category_id` int(10) UNSIGNED NOT NULL,
`views` int(10) UNSIGNED NOT NULL,
`comments` int(10) UNSIGNED NOT NULL,
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`content` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Compact;
1.2 往表内插值
INSERT INTO `article` ( `author_id`, `category_id`, `views`, `comments`, `title` ,`content` )
VALUES
(1,1,1,1,"1","2"),
(2,2,2,2,"2","2"),
(1,1,3,3,"3","3");
1.2查询
案例一:查询category_id 为 1 且 comments 大于1 的情况下,views 最多的 article_id 。
EXPLAIN SELECT
`id`,
`author_id`
FROM
article
WHERE
category_id = 1
AND comments > 1
ORDER BY
views DESC # ASC上升序列
LIMIT 1;

更新数据:
update person set name="小王",class=5 WHERE id=1;
上文中,tpye 是ALL,而且extra 里还出现了 using filesort,所以是最坏的情况,优化也是必须的。
建立索引
CREATE INDEX idx_article_ccv on article(category_id,comments,views);
# 注意创建索引的时候,student 后面自己跟 id,age
CREATE INDEX idx_id_age ON student(id,age);
CREATE INDEX idx_age ON student(age);
# 删除索引:
DROP index stu_class_name_grade on student;
索引是根据 where 后面的和 排序 的 关键字 建立。
查看索引所有
SHOW INDEX from article;
索引会根据 1,2,3 的顺序进行排序。

explain参数的含义
分别是type,key,rows。其中key表明的是这次查找中所用到的索引,rows是指这次查找数据所扫描的行数(这里可以先这样理解,但实际上是内循环的次数)。而type则是本文要详细记录的连接类型,前两项重要而且简单,无需多说。
mysql5.7中type的类型达到了14种之多,这里只记录和理解最重要且经常遇见的六种类型,它们区别。all,index,range,ref,eq_ref,const。从左到右,它们的效率依次是增强的。
All
这便是所谓的“全表扫描”,如果是展示一个数据表中的全部数据项,倒是觉得也没什么,如果是在一个查找数据项的sql中出现了all类型,那通常意味着你的sql语句处于一种最原生的状态,有很大的优化空间。
Index
这种连接类型只是另外一种形式的全表扫描,只不过它的扫描顺序是按照索引的顺序。这种扫描根据索引然后回表取数据,和all相比,他们都是取得了全表的数据,而且index要先读索引而且要回表随机取数据,因此index不可能会比all快(取同一个表数据),但为什么官方的手册将它的效率说的比all好,唯一可能的原因在于,按照索引扫描全表的数据是有序的。这样一来,结果不同,也就没法比效率的问题了。
range
range指的是有范围的索引扫描,相对于index的全索引扫描,它有范围限制,因此要优于index。关于range比较容易理解,需要记住的是出现了range,则一定是基于索引的。
ref
出现该连接类型的条件是: 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。
ref_eq
ref_eq 与 ref相比牛的地方是,它知道这种类型的查找结果集只有一个?什么情况下结果集只有一个呢!那便是使用了主键或者唯一性索引进行查找的情况,比如根据学号查找某一学校的一名同学,在没有查找前我们就知道结果一定只有一个,所以当我们首次查找到这个学号,便立即停止了查询。这种连接类型每次都进行着精确查询,无需过多的扫描,因此查找效率更高
const
通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量
extra信息
Using filesort(九死一生的提示,需要尽快优化)
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。mysql中无法利用索引完成的排序操作称为“文件排序”。
排序的时候最好遵循所建索引的顺序与个数否则就可能会出现using filesort
Using temporary
使用了临时表保存中间结果,mysql在对查询结果排序时使用临时表。常见于排序order by和分组查询group by。
group by一定要遵循所建索引的顺序与个数
Using index
表示相应的select操作中使用了覆盖索引(covering index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;
explain其他信息
- 执行顺序先看
id,从上到下;先执行id=1的,然后是id=2的,如果id相同,那么在上面,先执行谁。 - 然后看 table,是小表驱动大表,所以是先执行的下边的,然后是上边的。
explain
再次执行查看命令
EXPLAIN
-- SELECT id, author_id
SELECT *
FROM article
WHERE
category_id=1
AND
comments>1
ORDER BY
views DESC
LIMIT 1;

虽然优化了,但是这个using filesort 还是存在的。
这是因为索引无法对范围进行索引,索引在>1这个地方行不通,所以要新建索引,单表的查询的时候要注意,在不等于的时候,索引失效。
create index idx_article_cv on article(category_id,views);
EXPLAIN
SELECT
*
FROM
article
WHERE
`category_id` = 1
AND `comments` > 1
ORDER BY
views DESC
LIMIT 1;

二.索引两表优化
两表查询的原则
左连接,在右边上加索引,右连接在左表上加索引。
原因分析: 因为左连接的时候,左边肯定是都有的,所以最后的结果应该是看右边。
2.1 建表
建立class 和 book 两个类:每个表里随机的产生 20条数据。
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));

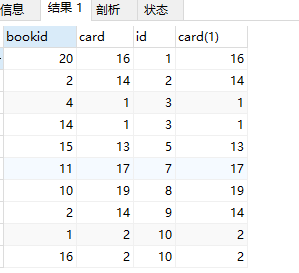
SELECT * FROM book INNER JOIN class ON book.card=class.card;
筛选出来的结果:15条记录
内连接就是做笛卡尔积,然后把所有符合 on 条件的都提取出来
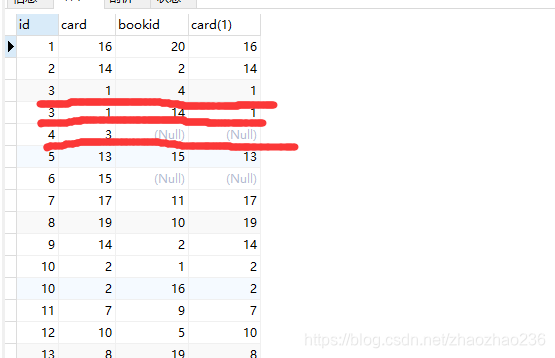
左连接
SELECT * FROM class LEFT JOIN book ON class.card=book.card;
左连接查询共 22 条记录。
2.2 建立索引
ALTER TABLE `book` ADD INDEX Y(`card`); # 给book 的card 建立索引
再次执行查找命令
EXPLAIN SELECT
*
FROM
class
LEFT JOIN book ON class.card = book.card;

2.3 换个地方建立索引
删除索引
DROP INDEX Y ON book;
在class上建立索引
ALTER TABLE `class` ADD INDEX Y(`card`); # 给class 的card 建立索引

三表索引优化系列
三表建立索引的原则
也是左连接在右表建立索引,右连接在左表建立索引。
尽量不要使用
JSON这种联合查询的字符串
永远用小表驱动大表,比如,班级和学生,肯定是学生是大表,班级是小表
当有嵌套语句的时候,优先优化内循环的语句,就比如鸡蛋,只有最内核的快了,其他的才会快。
查询的原则
除了违反最右前缀树原则以外,还有其他几个地方
-
不要在索引列上进行任何操作(计算、函数、类型转换),会导致索引失效
-
不等号,包括
>,<,is null,is not null都会让索引失效 -
使用
or也会让索引失效。 -
varchar类型在查询的时候,一定要用单引号
例子
在原来两个表的基础上再建一个表,也是20行,内容如下:
SELECT * FROM
class LEFT JOIN book
ON class.card=book.card
LEFT JOIN phone
ON book.card=phone.card;
结果有25条记录:
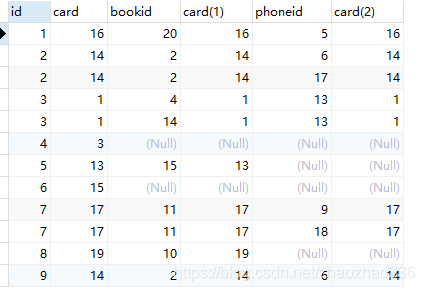
explan效果图:

建立索引:
查询语句
SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card=phone.card;
索引的建立 索引从join的内部开始往外建立,先见phone的索引,再建立 book 的索引,最后的class 是不需要建立索引的。
ALTER TABLE `phone` ADD INDEX Z(`card`);
ALTER TABLE `book` ADD INDEX Y(`card`);
再执行该查询语句
EXPLAIN
SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card=phone.card;

从 rows 上来看,有明显的提升
join 语句的优化
- 尽可能的减少
join语句中的nestedloop的内循环次数,永远用小结果驱动大的结果集 - 保证 join 语句中被驱动表上的
join条件字段索引 - 当无法保证驱动表中的
join条件字段被索引且内存资源内存资源充足的情况下,不要太吝惜joinbuffer的设置
排序优化
之前的优化,都是应对于 select 之后、order by 之前的查询。排序优化是更高阶的优化。
小表驱动大表
为什么要使用小表驱动大表
用 go 的一段代码看看,显然第一个的交互次数,要比第二次的少。
// 这个创建表连接的次数少
for i := 0; i < 5; i++ {
for j := 0; j < 1000; j++ {
}
}
// 这个创建表连接的次数多
for i := 0; i < 1000; i++ {
for j := 0; j < 5; j++ {
}
}
如果小的循环在外层,对于表连接来说就只连接5次 ;
如果大的循环在外层,则需要进行1000次表连接,从而浪费资源,增加消耗 ;
综上: 小表驱动大表的主要目的是通过 减少表连接创建的次数 ,加快查询速度 。
怎么区分驱动表和被驱动表
通过EXPLAIN查看SQL语句的执行计划可以判断在谁是驱动表,EXPLAIN语句分析出来的第一行的表即是驱动表;
-
当使用left join时,左表是驱动表,右表是被驱动表
-
当使用right join时,右表时驱动表,左表是被驱动表
-
当使用inner join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表
小表驱动大表的读写顺序不要写反了
-- student 这个表比较小。所以是小表驱动大表
select * from grade WHERE grade.stuid in (SELECT student.id from student where student.class=1);
-- 如果这两个表大小是反的呢?
SELECT grade.id from grade WHERE EXISTS (SELECT * from student WHERE student.id=grade.stuid);;
# `这里的select 1并不绝对,可以写为select 'X'或者'A','B','C'都可以,当然也可以写 select *,只要是常量就可以。`
四. 索引失效
-
全值匹配我最爱。
-
最佳左前缀法则
-
不在索引列上做任何操作(计算,函数,(自动or手动)类型转换),会导致索引失效二
-
存储引擎不能使用索引中范围条件右边的列
-
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少
select *之类的操作 -
mysq 中使用不等于(!= 或者 < >)的时候无法使用索引会导致全表扫描
-
is null,is not null也无法使用索引 -
like以通配符开头的 (“%abc...”) mysql 索引失效会变成全表扫描的操作,最好改用右边使用通配符 (“abc%”) -
字符串不加 单引号,索引失效,就是相当于把 字符串
"2000"转成 数字2000 -
少用
or,用他来链接,索引会失效
最佳左前缀法则:如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并不跳过索引的中间列。
如果使用
like必须要有百分号的话,尽量将百分号放在 右边,如果两边必须有百分号的话,那么就是用覆盖索引。
索引优化的口诀
-
大头大哥不能死
-
中间兄弟不能断
-
最佳左前缀原则
-
索引列上无计算
-
like 百分加右边
-
范围之后全失效
-
字符串里有引号
下边的小例子,重点记忆一下
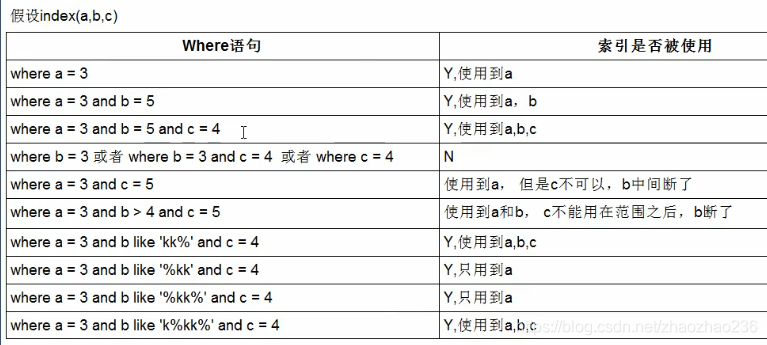
假设index(a,b,c)
| where语句 | 是否用到索引 | 用到的索引 |
|---|---|---|
| where a=3 | Y | 使用到了 a |
| where a=3 and b=5 | Y | 使用到 a,b |
| where a=3 and b=5 and c=4 | Y | 用到了 a,b,c |
| where b=3 或者 where b=3 and c=4 或者 where c=4 | N | |
| where a=3 and c=5 | 部分用到 | 使用到了 a,但是 c不可以,因为 b中间断了 |
| where a=3 and b >4 and c=5 | 部分用到 | 用到了 a 和 b ,c不能 |
| where a=3 and b like "kk%" and c=4 | 是 | 使用到了ABC,注意使用到了abc |
| where a=3 and b like "%kk" and c=4 | 部分用到 | 只用到了a |
| where a=3 and b like "%kk%" and c=4 | 部分用到 | 只用到了a |
| where a=3 and b like "k%kk%" and c=4 | 是 | 用到了 a,b,c |
参考文献
https://www.bilibili.com/video/BV12b411K7Zu?p=241&share_source=copy_web
https://blog.csdn.net/dennis211/article/details/78170079

 浙公网安备 33010602011771号
浙公网安备 33010602011771号