

Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行。
环境准备:
1,Maven环境搭建,版本Apache Maven 3.3.9,jar包管理工具;
2,JDK环境搭建,版本1.7.0_51,hadoop由Java编写;
3 ,Scala 环境搭建,版本 2.11.8,spark是scala编写的;
4 ,spark 源码包,从官网选择

编译前准备:
0,Maven ,JDK,Scala解压安装,并加入到环境变量中
1,wget 源码到~/source 并且 tar -zxvf spark-2.1.0.tgz
2 , 加入cdh仓库,在spark-2.1.0/pom.xml
1 <repository> 2 <id>cloudera-releases</id> 3 <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> 4 <releases> 5 <enabled>true</enabled> 6 </releases> 7 <snapshots> 8 <enabled>false</enabled> 9 </snapshots> 10 </repository>
编译:
1) 根据自己的机器实际情况,合理的分配内存给JVM, 通过命令:export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
2) 在spark-2.1.0/下通过命令:
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
或者通过mvn方式直接编译(maven编译完成没有一个大的完整的包使用)
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -DskipTests clean package
这个编译过程大约两个小时,更网速有关,有的Jar包需要FQ下载,所有时间教长
编译完成会在spark-2.1.0/下产生一个spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz包,将它解压,加入到环境变量就算结束了。
解读编译命令:
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package
1) -Dhadoop.version=2.6.0
在编译命令上在外部指定(修改)<hadoop.version>2.2.0</hadoop.version> 默认的2.2.0 改为2.6.0
在spark根目录下的pom.xml文件中,部分源码如下,可以看出默认的hadoop版本是2.2.0
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF8</project.reporting.outputEncoding> <java.version>1.7</java.version> <maven.version>3.3.9</maven.version> <sbt.project.name>spark</sbt.project.name> <slf4j.version>1.7.16</slf4j.version> <log4j.version>1.2.17</log4j.version> <hadoop.version>2.2.0</hadoop.version> <protobuf.version>2.5.0</protobuf.version> <yarn.version>${hadoop.version}</yarn.version> <flume.version>1.6.0</flume.version> <zookeeper.version>3.4.5</zookeeper.version> <curator.version>2.4.0</curator.version> <hive.group>org.spark-project.hive</hive.group> <!-- Version used in Maven Hive dependency --> <hive.version>1.2.1.spark2</hive.version> <!-- Version used for internal directory structure --> <hive.version.short>1.2.1</hive.version.short> <derby.version>10.12.1.1</derby.version> <parquet.version>1.8.1</parquet.version> <hive.parquet.version>1.6.0</hive.parquet.version> <jetty.version>9.2.16.v20160414</jetty.version> <javaxservlet.version>3.1.0</javaxservlet.version>
</properties>
2) -Phadoop-2.6
在源码pom.xml中,通过外部指定的<profile>的id来选择编译时所用到的<profile>
源码中,-Phadoop-2.6来选择id为hadoop-2.6的<profile>作为编译条件
<profile> <id>hadoop-2.2</id> <!-- SPARK-7249: Default hadoop profile. Uses global properties. --> </profile> <profile> <id>hadoop-2.3</id> <properties> <hadoop.version>2.3.0</hadoop.version> <jets3t.version>0.9.3</jets3t.version> </properties> </profile> <profile> <id>hadoop-2.4</id> <properties> <hadoop.version>2.4.1</hadoop.version> <jets3t.version>0.9.3</jets3t.version> </properties> </profile> <profile> <id>hadoop-2.6</id> <properties> <hadoop.version>2.6.4</hadoop.version> <jets3t.version>0.9.3</jets3t.version> <zookeeper.version>3.4.6</zookeeper.version> <curator.version>2.6.0</curator.version> </properties> </profile> <profile> <id>hadoop-2.7</id> <properties> <hadoop.version>2.7.3</hadoop.version> <jets3t.version>0.9.3</jets3t.version> <zookeeper.version>3.4.6</zookeeper.version>
3) -Phive -Phive-thriftserver和-Pyarn,同上面选择hadoop的profile一样,编译时加上对hive和yarn的支持
4) -DskipTests clean package 编译过程中,跳过测试,实例包等,不进行编译;
./dev/make-distribution.sh  --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
--name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
1)./dev/make-distribution.sh 通过在dev下的make-distribution.sh编译
2)--name 2.6.0-cdh5.7.0 --tgz 编译后打成一个名为spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz 的tgz包
2)-Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver 同maven一样,通过id选择<profile>中的内容,进而支持某个模块
3)-Dhadoop.version=2.6.0-cdh5.7.0 指定hadoop的版本
make-distribution.sh源码阅读
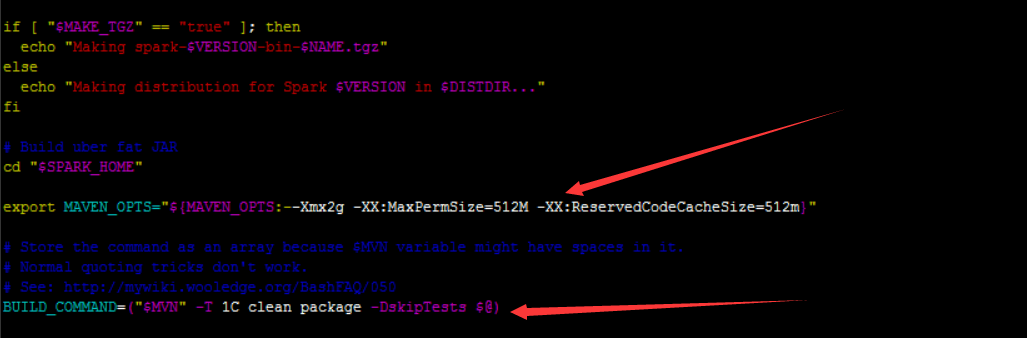
在上图中可以看出,编译脚本已经加入export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m",并且加入了跳过检测包的语句

--mvn 后面添加在编译mvn时选择的版本和<profile>

打包命令,以及报名的命名规则
到此,spark源码记录完毕。
