分布式爬虫(一)------------------分布式爬虫概述
分布式爬虫概述
什么是分布式爬虫:
多个爬虫分布在不同的服务器上,通过状态管理器进行统一调度,达到像URL去重等功能的爬虫系统
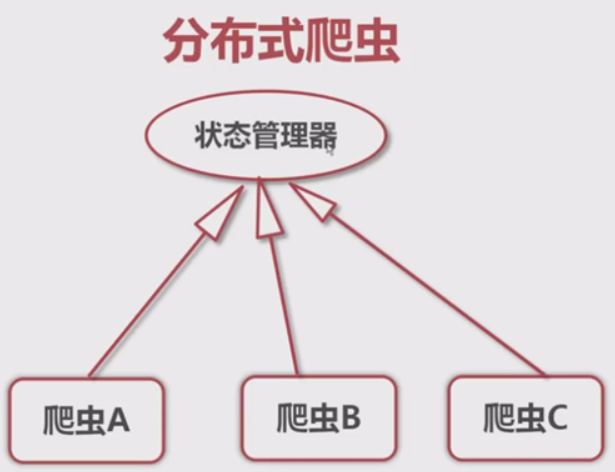
分布式爬虫的优点
1) 充分利用多台机器的宽带加速
2)充分利用多机器的IP加速爬取速度
Scrapy分布式爬虫原理
单机Scrapy爬虫架构
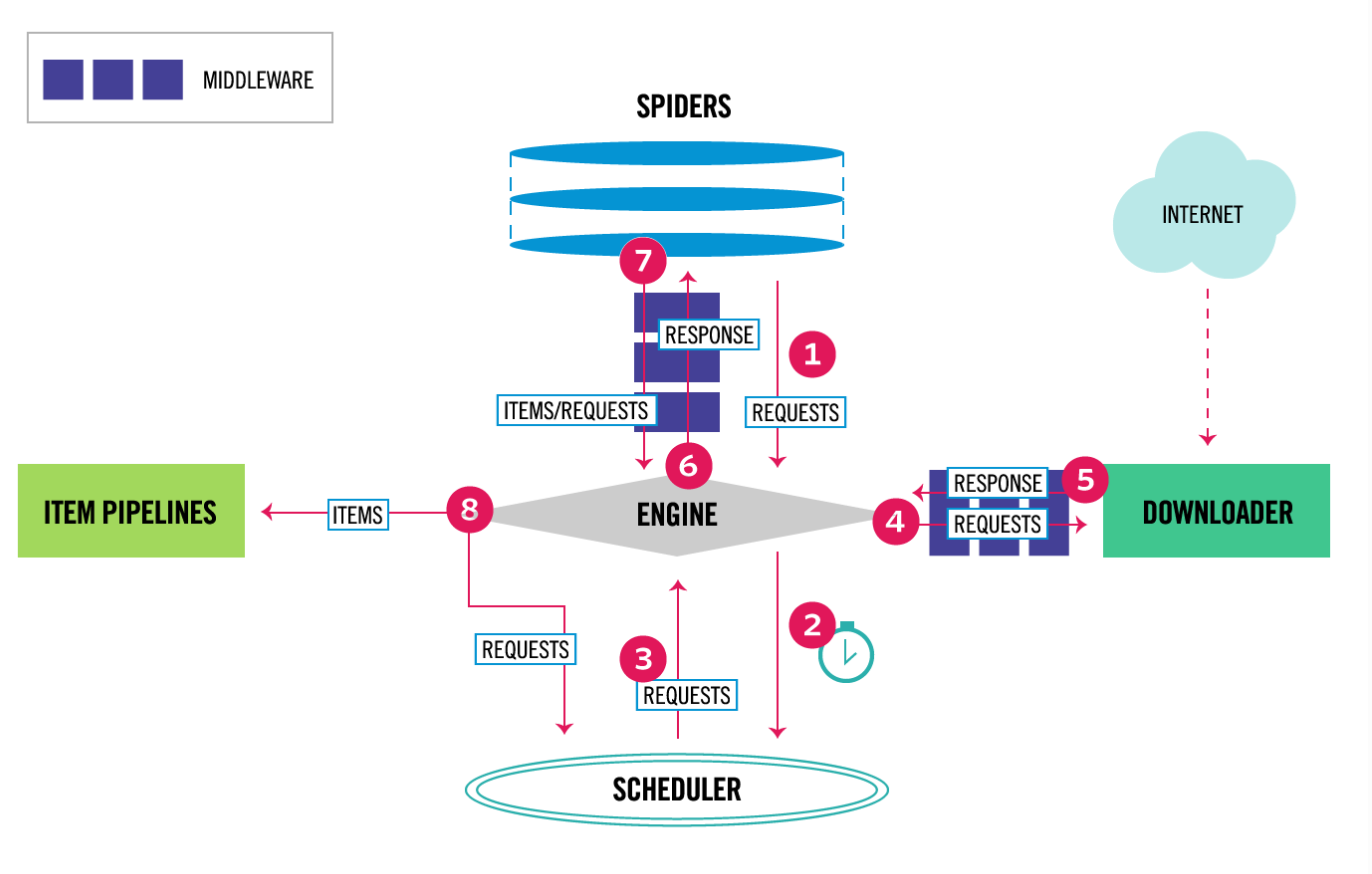
分布式爬虫需要改进的Scrapy
1)requests队列集中管理(在架构图中SCHEDULER中管理)
2)URL去重集中管理
解决方法:
requests队列存储在单机的内存当中,URL去重原理也是存储在内存当中的Set()集合中,解决这两个问题,
可以将这个队列和集合存储在数据库中,进行统一的资源管理。
在选择数据库时推荐使用Redis数据库,它是一个基于内存的数据库,将Requests队列和URL集合存储在内存,避免数据落地,提高效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号