Spark环境搭建(五)-----------Spark生态圈概述与Hadoop对比
Spark:快速的通用的分布式计算框架
概述和特点:
1) Speed,(开发和执行)速度快。基于内存的计算;DAG(有向无环图)的计算引擎;基于线程模型;
2)Easy of use,易用 。 多语言(Java,python,scala,R); 多种计算API可调用;可在交互式模式下运行;
3)Generality 通用。可以一站式解决多个不同场景的应用业务
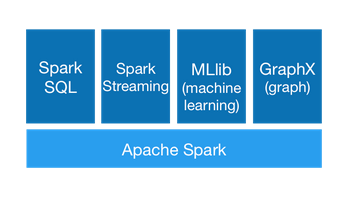
Spark Streaming :用来做流处理
MLlib : 用于机器学习
GraphX:用来做图形计算的
4) Runs Everywhere :
(1)可以运行在Hadoop的yarn,Mesos,standalone(Sprk自带的)这些资源管理和调度的程序之上
(2) 可以连接包括HDFS,Cassandra,HBase,S3这些数据源

产生背景:
1)MapReduce 局限性
(1)代码繁琐(官网有WordOCunt案例)
(2)效率低下:
a) 有结果写入磁盘,降低效率;
b) 通过进程模型,销毁创建效率低
(3)只能支持map和reduce方法
(4) 不适合迭代多次,交互式,流水的处理
2) 框架的多样化
(1)批处理(离线):MapReduce,Hive,Pig
(2)流式处理(实时):Storm,Jstorm
(3)交互式计算 :Impala
综上: 框架的多样化导致生产时所需要的框架繁多,学习运维成本较高,那么有没有一种框架,
既能执行效率高,学习成本低,还能支持批处理和流式处理与交互计算呢?
结论:Spark诞生
Spark与Hadoop对比:
Hadoop生态系统
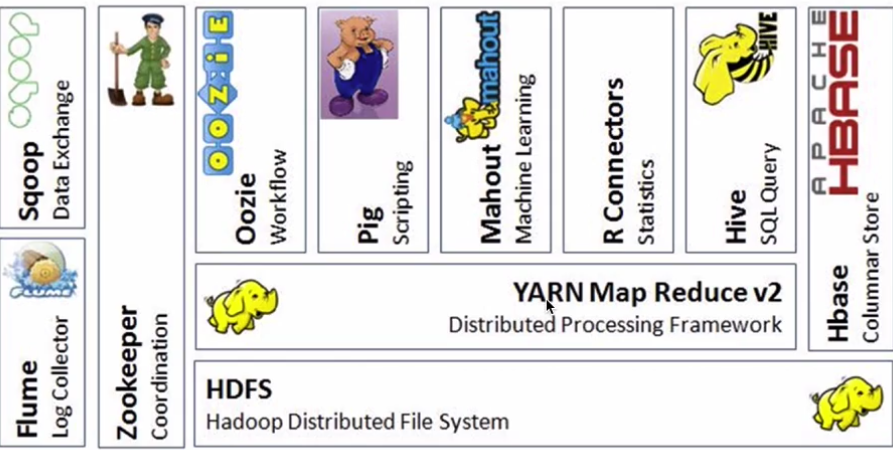
Hive:数据仓库
R:数据分析
Mahout:机器学习库
pig:脚本语言,跟Hive类似
Oozie:工作流引擎,管理作业执行顺序
Zookeeper:用户无感知,主节点挂掉选择从节点作为主的
Flume:日志收集框架
Sqoop:数据交换框架,例如:关系型数据库与HDFS之间的数据交换
Hbase : 海量数据中的查询,相当于分布式文件系统中的数据库
BDAS:Berkeley Data Analytics Stack(伯克利数据分析平台)
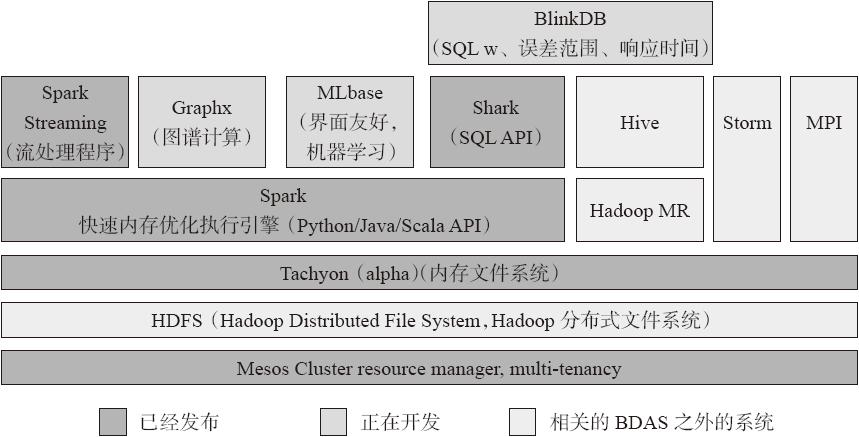
Spark与Hadoop生态圈对比
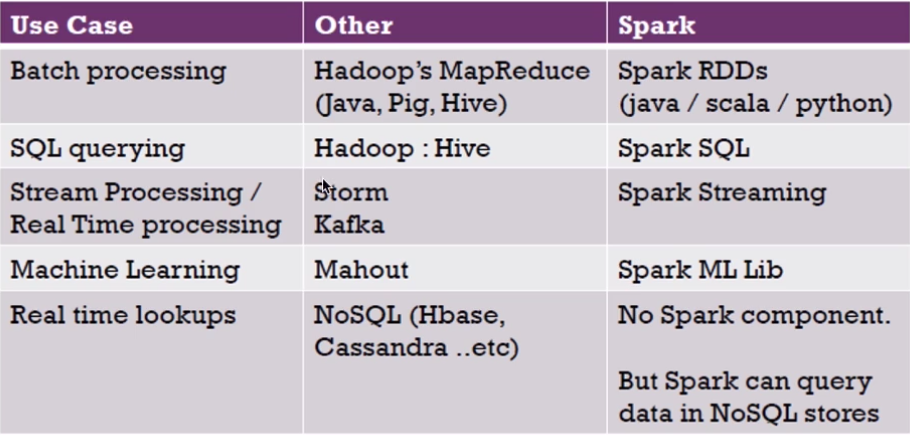
注意:在对实时的查询来说,Spark只是一个快速的分布式计算框架,所以没有存储的框架,但是可以连接多个存储的数据源
Hadoop与Spark对比
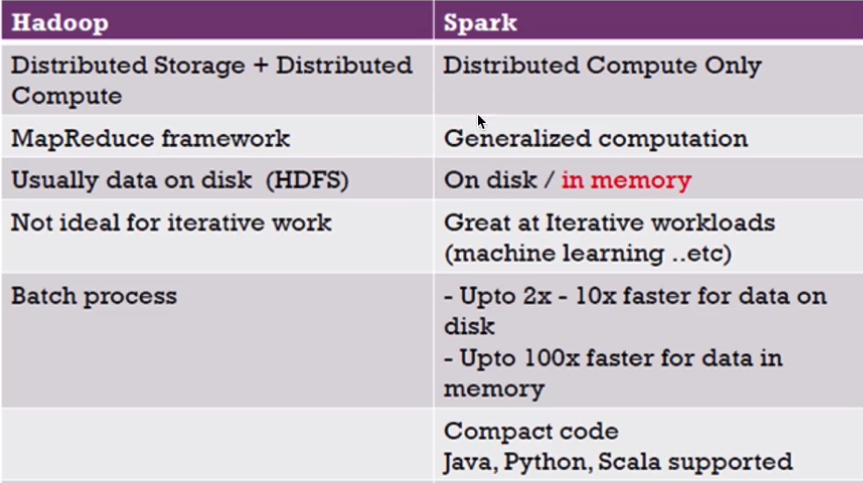
MapReduce与Spark对比:
MapReduce:若进行多次计算,MP则需要将上一次执行结果写入到磁盘,叫做数据落地
Spark:直接将存储在内存中的结果拿来使用,没有数据落地

Spark与Hadoop的协作性
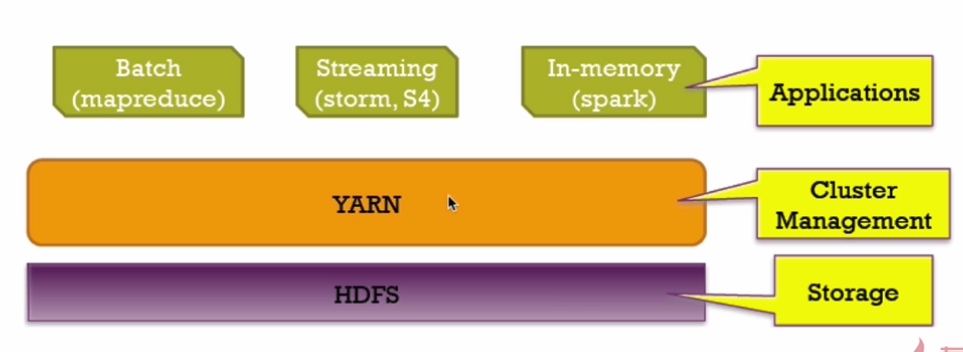
Spark概述和与Hadoop对比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号