C++内存对齐
什么是内存对齐
内存对齐是编译器为了便于CPU快速访问而采用的一项技术,用空间换时间提高CPU访问效率。
内存对齐是从硬件层面出现的概念。可执行程序是由一系列CPU指令构成的,CPU指令中有一些指令需要访问内存。最常见的就是“从内存读到寄存器”,以及“从寄存器写到内存”。在老的架构中(包括x86),也有一些运算的指令是可以直接以内存为操作数,那么这些指令也隐含了内存的读取。在很多CPU架构下,这些指令都要求操作的内存地址(更准确的说,操作内存的起始地址)能够被操作的内存大小整除,满足这个要求的内存访问叫做访问对齐的内存(aligned memory access),否则就是访问未对齐的内存(unaligned memory access)。
举例来说,ARM的LDRH指令从内存中读取2个byte到寄存器中。如果指定的内存的地址是0x2587c20,因为0x2587c20这个数能够被2整除,所以这2个byte是对齐的。而如果指定的内存的地址是0x2587c33,因为不能被2整除,所以是未对齐的。
为什么要内存对齐
解释一
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特 类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问,这是一种典型的空间换时间的思想.
解释二
- CPU 对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16 ... 字节;
- 当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣;
- 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则会产生异常。
解释三
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的.它一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度.
现在考虑4字节存取粒度的处理器取int类型变量(32位系统),该处理器只能从地址为4的倍数的内存开始读取数据。
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器.这需要做很多工作.
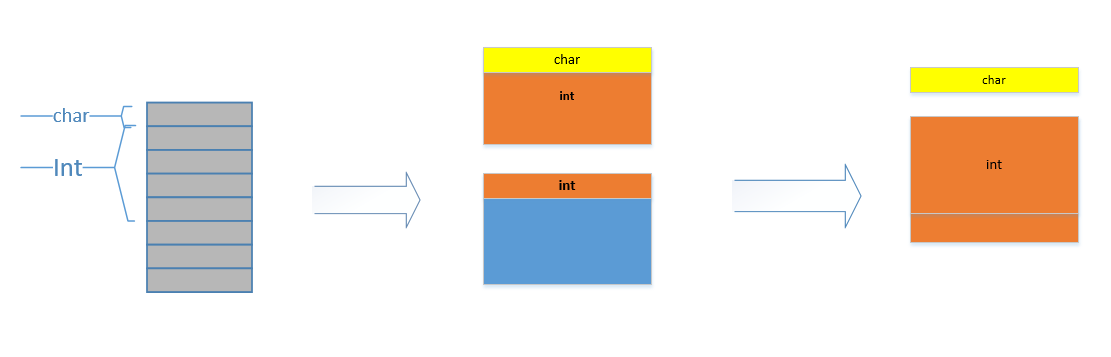
现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
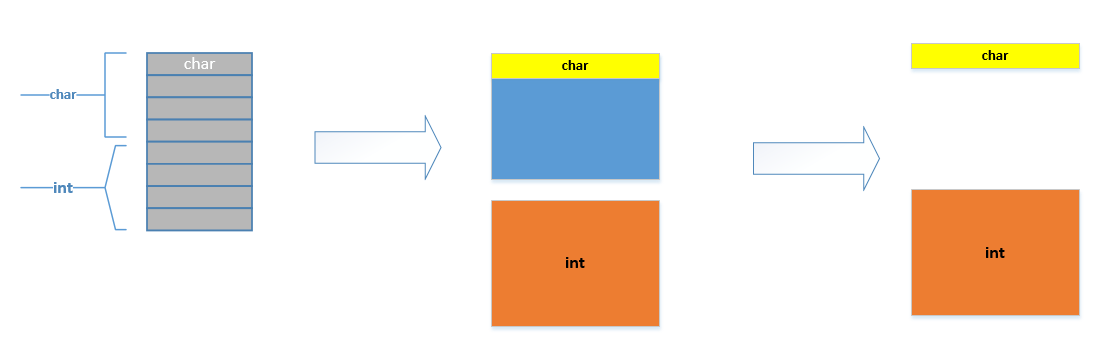
那如果访问未对齐的内存会出现什么结果呢?这个要看CPU。
- 有些CPU架构可以访问未对齐的内存,但是会有性能上的影响,典型的就是x86架构CPU
- 有些CPU会抛出异常
- 有些CPU不会抛出任何异常,会静默地访问错误的地址
- 近几年也有些CPU的一部分指令可以正常访问未对齐的内存,同时不会有性能影响
因为每个CPU对未对齐内存的访问的处理方式都不一样,所以访问未对齐的内存是要尽量避免的。所以就出现了C/C++的内存对齐机制。
内存对齐规则
在C++中每个类型都有两个属性,一个是大小(size),还有一个就是对齐要求(alignment requirement),或称之为对齐量(alignment)。C++标准并没有规定每个类型的对齐量,但是一般都会有这样的规律。
- 所有基础类型的对齐量等于这个类型的大小
- struct, class, union类型的对齐量等于他的非静态成员变量中最大的对齐量。
另外,标准规定所有的对齐量必须是2的幂。
编译器在给一个变量分配内存时,都要算出并满足这个类型的对齐要求。struct和class类型的非静态成员变量的字节数偏移(offset)也要满足各自类型的对齐要求。
举例来说,
class MyObject
{
// c是char类型,对齐要求是1
char c; // MyObject的第一个成员变量,字节数偏移为0,占据MyObject的第一个byte
// i是int类型,对齐要求是4
int i; // 字节数偏移必须是对齐要求4的倍数,且变量i在变量c的后面,于是i的字节数偏移就是4
// 占据MyObject的第5到第8个byte,而第2到第4个byte则是空白填充(padding)
// s是short类型,对齐要求是2
short s; // 对齐要求是2,且s在i的后面,所以s的字节数偏移是8,占据MyObject的第9个和第10个byte
}; // MyObject取最大的,也就是4作为他的对齐要求
// 如果在某个函数中声明了MyObject类型的变量,那么分配给这个变量的内存的起始地址是能够被4整除的
// 因为struct、class、union类型的数组的每个元素都要内存对齐
// 所以一般来说struct、class、union的大小都是这个类型的对齐量的整数倍
// 所以MyObject的大小是12,也就是说,变量s后面会有2个byte的空白填充。
因为C++中所有内存访问都是通过变量的读写来访问的,这个机制确保了所有变量都满足了内存对齐,也就确保了程序中所有内存访问都是对齐的。
当然,C++不会阻止我们去访问未对齐的内存。例如,以下的代码就很可能会访问未对齐的内存:
char buf[10];
int* ptr = (int*)(buf + 1);
++*ptr;
这类代码是我们在实际工作中也是能遇到的。事实上这种写法是比较危险的,因为他很可能会去访问未对齐的内存。这也是为什么写c++大家都不推荐用c风格的类型转换写法,而是要用static_cast, dynamic_cast, const_cast与reinterpret_cast。这样的话,上面的代码就必须要使用reinterpret_cast,大家都知道reinterpret_cast是很危险的,也许就会想办法避免这样的逻辑。
内存对齐原则及作用
struct/class/union内存对齐原则有四个:
- 数据成员对齐:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节, 则要从4的整数倍地址开始存储),基本类型不包括struct/class/uinon。
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部"最宽基本类型成员"的整数倍地址开始存储.(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储.)。
- 收尾工作:结构体的总大小,也就是sizeof的结果,.必须是其内部最大成员的"最宽基本类型成员"的整数倍.不足的要补齐.(基本类型不包括struct/class/uinon)。
- sizeof(union),以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行
- 结合1、2可推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果
#include <iostream>
using namespace std;
#pragma pack(8)
// 64位系统,pack为8
struct Node
{
bool cd; // 第一个成员,偏移量为0,此时占用1个字节,[0,1)
int id; // 第二个成员,sizeof int = 4, 4 < 8, 所以对齐数为4,
// 偏移量必须为4的整数倍, 4*1满足不会覆盖前面成员同时不至于浪费太多数据,所以偏移量为4
// 由于char只占一个字节,所以[1,4)必须填充为0,此时id占用 [4,8)
bool bd;// 第三个成员,sizeof bool = 1, 1 < 4, 所以对齐数为1, 偏移量为1且不会覆盖前成员的最小整数倍,故为8,占用[8,9)位置
};
// 此时结构体占据[0, 9), 根据结构体对齐规则,Node按照当前所有成员中的最大对齐数对齐,即4,所以此时结构体实际占用空间为[0,12),[9,12)位置填充0
int main() {
cout << "sizeof no = " << sizeof(Node) << endl;
Node no;
// 查看成员地址分布
cout << "cd " << &(no.cd) << endl;
cout << "id " << &(no.id) << endl;
cout << "bd " << &(no.bd) << endl;
}
sizeof no = 12
cd 0x94965ffcd4
id 0x94965ffcd8
bd 0x94965ffcdc
由于不同CPU对非对齐内存的操作不一致,因为程序员来通过一些编程习惯来尽可能避免这些问题。
比如: 结构体/类中相同类型的成员变量最好写在一起
控制对齐方式
在 C++ 中,可以使用一些方法来控制内存对齐方式:
alignof运算符:alignof运算符返回给定类型的对齐要求(以字节为单位)。
alignof(int); // 返回 int 类型的对齐要求
alignas关键字:alignas关键字用于指定特定类型或对齐要求的对齐方式。
alignas(16) char buffer[1024]; // 将 buffer 数组的对齐方式设置为 16 字节
#pragma pack指令:#pragma pack指令可用于修改结构体的对齐方式,从而实现结构体的紧凑排列。
#pragma pack(push, 1) // 将当前对齐方式压入堆栈,并设置为 1 字节对齐
struct MyStruct {
char c;
int i;
};
#pragma pack(pop) // 恢复之前的对齐方式`
示例
#include <iostream>
struct MyStruct {
char c;
int i;
double d; };
int main() {
std::cout << "Size of char: " << sizeof(char) << std::endl;
std::cout << "Size of int: " << sizeof(int) << std::endl;
std::cout << "Size of double: " << sizeof(double) << std::endl;
std::cout << "Alignment requirement for MyStruct: " << alignof(MyStruct) << std::endl; return 0;
}
在这个示例中,MyStruct 结构体的对齐值是 alignof(MyStruct),它通常等于其最大成员的大小,这个值决定了结构体在内存中的排列方式
在x86(32位机器)平台下,GCC编译器默认按4字节对齐: 64位,默认为8字节对齐
如:结构体4字节对齐,即结构体成员变量所在的内存地址是4的整数倍。
可以通过使用gcc中的_attribute_选项来设置指定的对齐大小
① attribute((packed)),让所作用的结构体取消在编译过程中的优化对齐,按照实际占用字节数进行对齐
② attribute((aligned (n))),让所作用的结构体成员对齐在n字节边界上。如果结构体中有成员变量的字节长度大于n,则按照最大成员变量的字节长度来对齐。
示例
#include <iostream>
// use attribute to pack
struct Node1
{
int id;
char cd;
}__attribute__ ((packed)) no1;
struct Node2
{
int id;
char cd;
}no2;
// use attribute to align
struct Node3
{
int id;
char cd;
}__attribute__ ((aligned(16))) no3;
int main()
{
std::cout << "use attribute to pack" << std::endl;
std::cout << "sizeof no1: " << sizeof(no1) << std::endl;
std::cout << "sizeof no2: " << sizeof(no2) << std::endl;
std::cout << "sizeof no3: " << sizeof(no3) << std::endl;
}
use attribute to pack
sizeof no1: 5
sizeof no2: 8
sizeof no3: 16
常见CPU的未对齐内存访问
根据Intel最新的Intel 64及IA-32架构说明书,Intel 64及IA-32架构都支持未对齐内存的访问,但是会有性能上的额外开销(详见http://www.intel.com/products/processor/manuals)。但是实际上最近的Core系列CPU已经可以无额外开销访问未对齐的内存。
而手机上最常见的ARMv8架构,如果是普通的、不做多核同步的未对齐的内存访问,那么CPU可能会产生对齐错误(alignment fault)或者执行未对齐内存操作。换句话说,到底会报错还是正常执行,是要看具体CPU的实现的。即使是执行正常操作,也会有一些限制。例如,不能保证读写的原子性(操作一个byte的除外),很可能产生额外的开销等(详见https://developer.arm.com/docs/ddi0487/latest/arm-architecture-reference-manual-armv8-for-armv8-a-architecture-profile)。ARMv8中的Cortex-A系列是手机上常见的CPU家族,他们就可以正常处理未对齐内存访问,但是一般会有额外的开销(详见http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.faqs/ka15414.html)。
关于C++类的内存对齐,详解可看下一章:C++类的内存对齐 - RunTimeErrors - 博客园
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号