第一次个人作业
| 这个作业属于哪个课程 | 22计科12班 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 第一次个人编程作业:设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
GitHub地址:https://github.com/xian226/3222003968
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 (分钟) | 实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| ·Estimate | ·估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 600 | 565 |
| ·Analysis | ·需求分析(包括学习新技术) | 180 | 300 |
| · Design Spec | ·生成设计文档 | 60 | 60 |
| ·Design Review | .设计复审 | 20 | 10 |
| · Coding Standard | ·代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| ·Design | .具体设计 | 15 | 15 |
| ·Coding | .具体编码 | 180 | 200 |
| · Code Review | ·代码复审 | 20 | 10 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 60 |
| ·Test Report | ·测试报告 | 30 | 30 |
| ·Size Measurement | ·计算工作量 | 15 | 10 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 5 | 5 |
| ·合计 | 1330 | 1410 |
计算模块接口的设计与实现过程
(1)函数的设计:
read_text(path): 负责从文件路径读取文本内容。
text_clean(str): 负责对文本进行清洗和分词。
cos(new1, new2): 负责计算两个文本列表的余弦相似度。
(2)关系和流程:
main()函数是程序的入口,它调用read_text()来读取文本,然后使用
text_clean()来清洗和分词,最后使用cos()函数来计算相似度。
read_text()、text_clean()和cos()函数都是main()函数的辅助函数,它们之
间没有直接的调用关系,但都是通过main()函数来协调的。
(3)算法关键点和独到之处:
1.算法的关键点
文本向量化:通过分词和建立词汇表,将文本转换为向量形式,这是计算余弦
相似度的基础。
余弦相似度计算:使用向量点积和模长来计算相似度,这是衡量文本相似度的
核心算法。
异常处理:在计算过程中,通过异常处理来避免除以零的错误。
2.独到之处
中文分词:使用jieba进行中文分词,这对于中文文本处理是一个关键步骤,因
为中文文本的分词直接影响到后续的文本分析。
异常处理:在计算余弦相似度时,通过异常处理来确保程序的健壮性,即使在面
对异常数据时也能正常运行。
计算模块接口部分的性能改进
性能分析图(由pycharm profile生成)
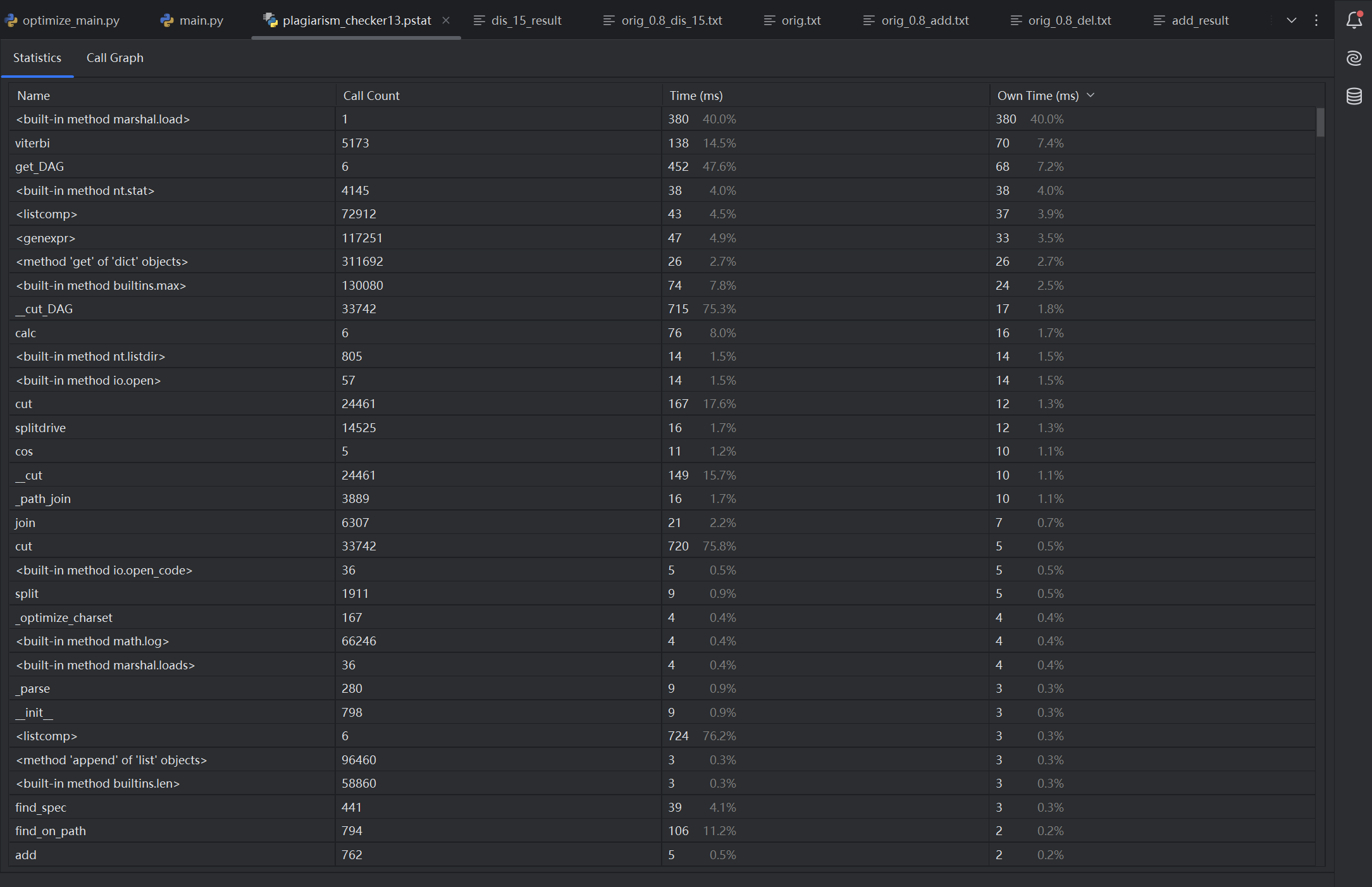
可得:get_DAG和
改进思路:
read_text 函数中使用 file.read() 但文本较大,可以考虑分块读取文件,并逐块处理数据,用file.readline() 逐行读取文件,并将其累加到一个字符串中
并且使用NumPy库来优化向量运算
优化后: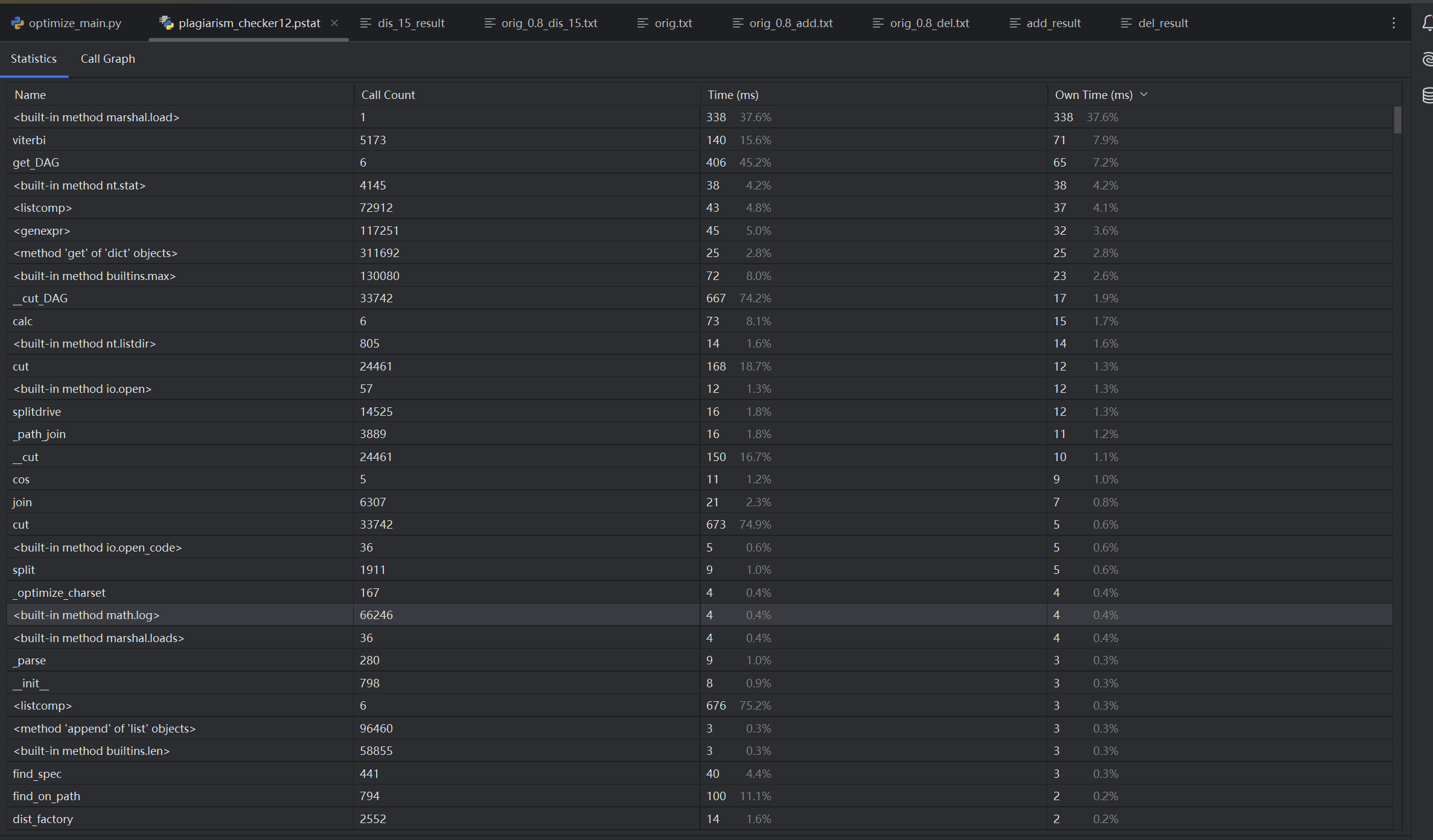
计算模块部分单元测试展示
cos函数测试:
测试代码:
import unittest
from optimize_main import cos # 导入模块和函数
class TestCosineSimilarity(unittest.TestCase):
def test_cosine_similarity_identical_texts(self):
text1 = ['hello', 'world']
text2 = ['hello', 'world']
result = cos(text1, text2)
self.assertEqual(result, 1.0)
def test_cosine_similarity_different_texts(self):
text1 = ['hello', 'world']
text2 = ['goodbye', 'world']
result = cos(text1, text2)
self.assertAlmostEqual(result, 0.5, places=4)
def test_cosine_similarity_empty_texts(self):
text1 = []
text2 = []
result = cos(text1, text2)
self.assertEqual(result, 0.0)
def test_cosine_similarity_one_empty_text(self):
text1 = ['hello']
text2 = []
result = cos(text1, text2)
self.assertEqual(result, 0.0)
def test_cosine_similarity_single_word_texts(self):
text1 = ['hello']
text2 = ['hello']
result = cos(text1, text2)
self.assertEqual(result, 1.0)
def test_cosine_similarity_complex_case(self):
text1 = ['the', 'quick', 'brown', 'fox']
text2 = ['the', 'slow', 'brown', 'dog']
result = cos(text1, text2)
self.assertAlmostEqual(result, 0.5, places=4)
if name == 'main':
unittest.main()
测试思路:
相同文本:测试函数对完全相同的文本应该返回1.0,因为它们的相似度应为
100%。
不同文本:测试函数对具有一些共同单词的不同文本进行比较,检查结果是否合
理。
空文本:测试函数处理完全为空的文本时的行为,预计应返回0.0。
一个空文本:测试一个文本为空,另一个文本非空的情况,确保结果为0.0。
单词文本:测试只有一个单词的文本,检查函数是否能正确处理单一单词的情况
复杂文本
部分重叠文本
大小写字母文本
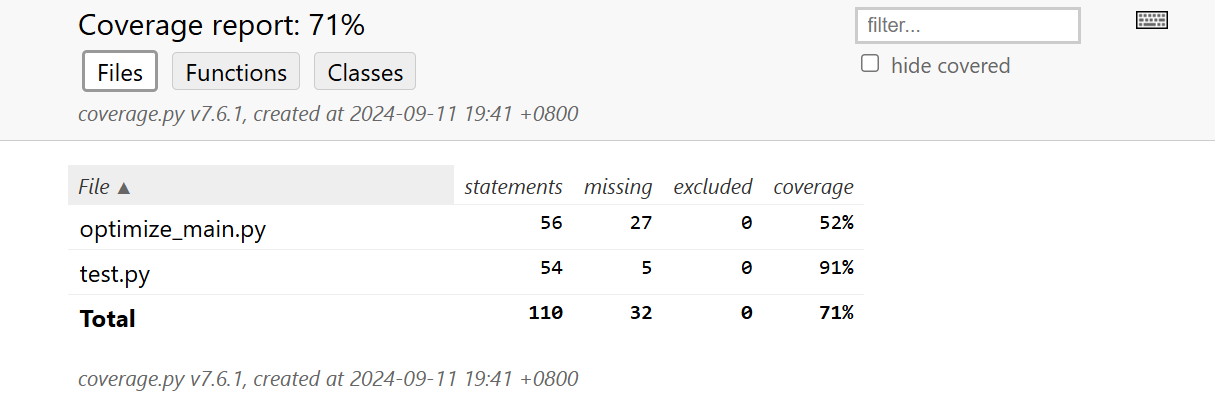
测试覆盖率截图:
计算模块部分异常处理说明
文件未找到异常
设计目标:
当指定的文件路径错误,或者文件不存在时,触发此异常,提示用户检
查文件路径的正确性
单元测试场景:
测试当文件路径不正确时,程序是否正确捕获异常并打印错误信息。
测试样例:
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError):
read_text('non_existent_file.txt')
未知错误
设计目标:
捕获所有其他未预料的异常,确保程序在意外情况下不会崩溃,并提示详细的错误
信息。
单元测试场景:
模拟可能抛出其他异常的情况,验证通用异常捕获是否有效。
测试样例:
def test_unknown_error(self):
def faulty_read_text(path):
raise Exception("未知错误")
with self.assertRaises(Exception):
faulty_read_text('some_path.txt')
余弦相似度计算异常
设计目标:
处理在余弦相似度计算过程中可能出现的ZeroDivisionError(当其中一个向量
的模为零时),防止数学错误导致程序崩溃。
单元测试场景:
当一个文本为空时,测试是否能够返回相似度为0。
测试样例:
def test_cosine_similarity_one_empty_text(self):
text1 = ['hello']
text2 = []
result = cos(text1, text2)
self.assertEqual(result, 0.0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号