实验 3 Spark 和 Hadoop 的安装
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
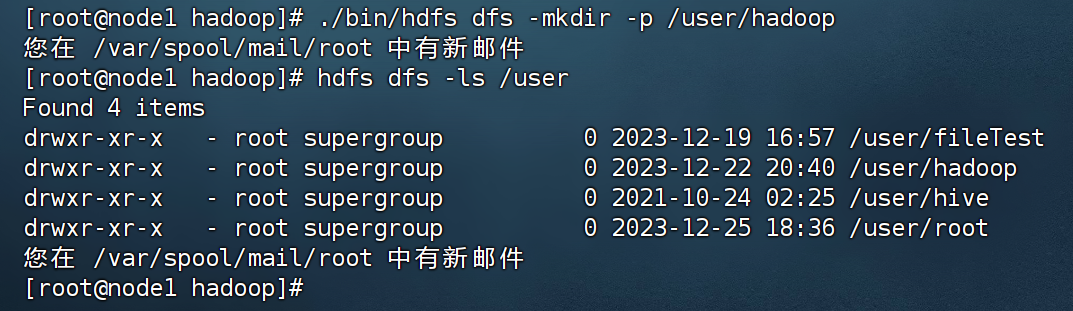
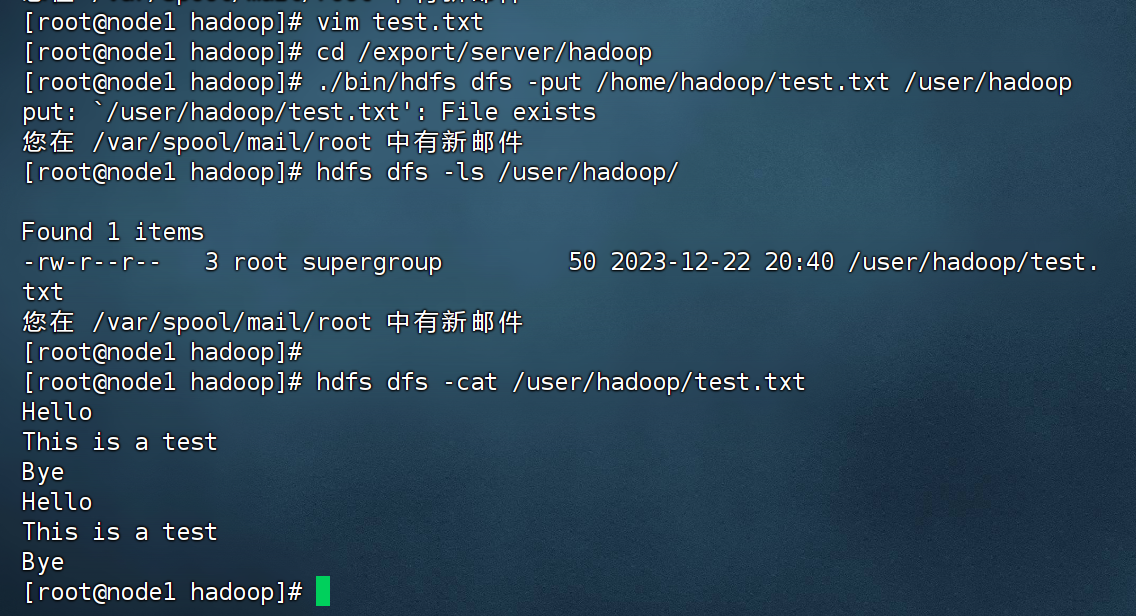
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop” 目录下;
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文 件系统中的“/home/hadoop/下载”目录下;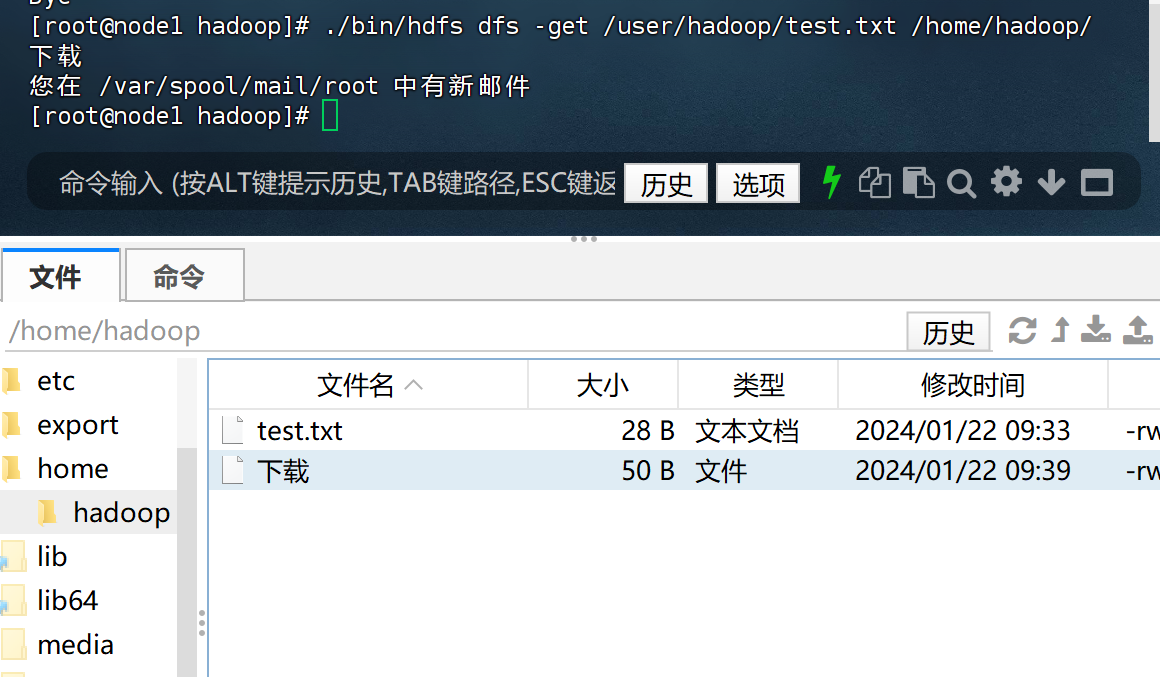
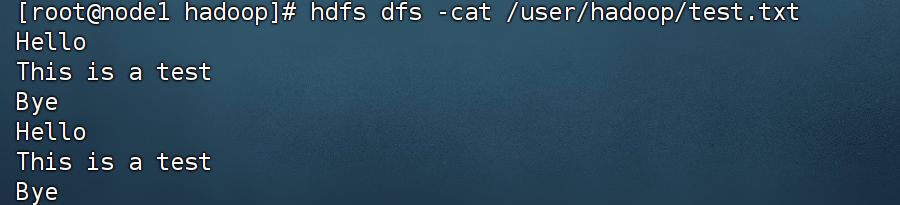
(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;
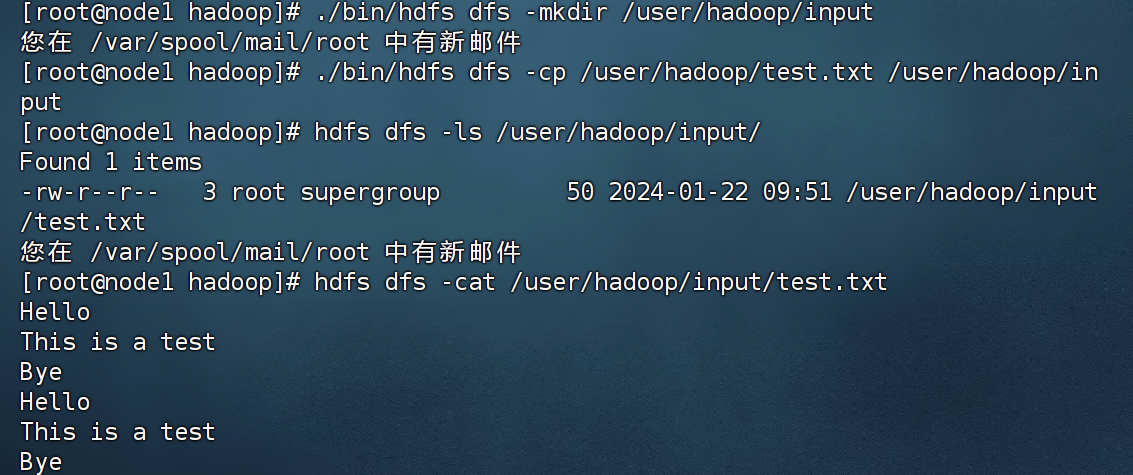
删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”
目录下的 input 子目录及其子目录下的所有内容。
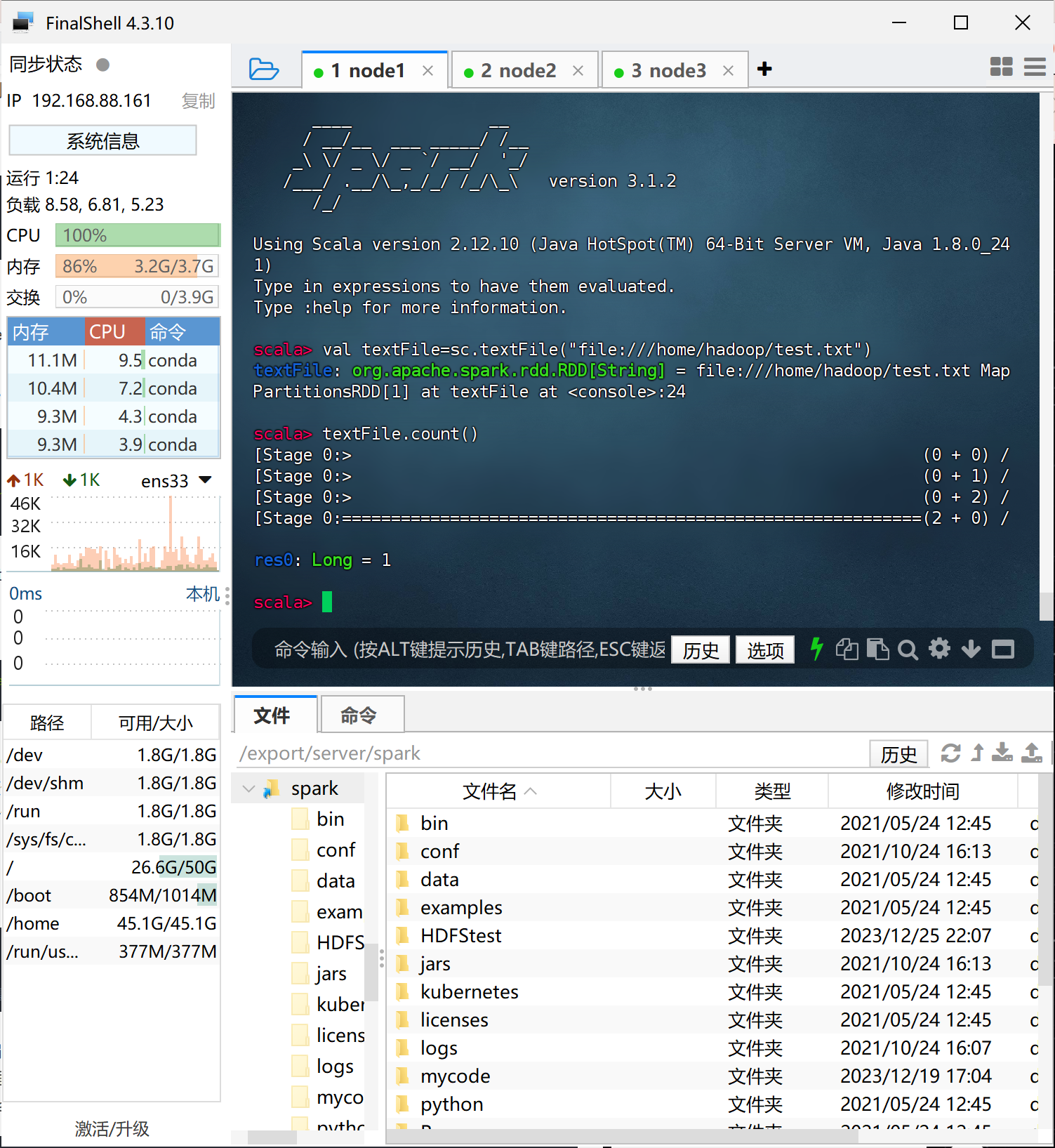
Spark 读取文件系统的数据
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文
件的行数;
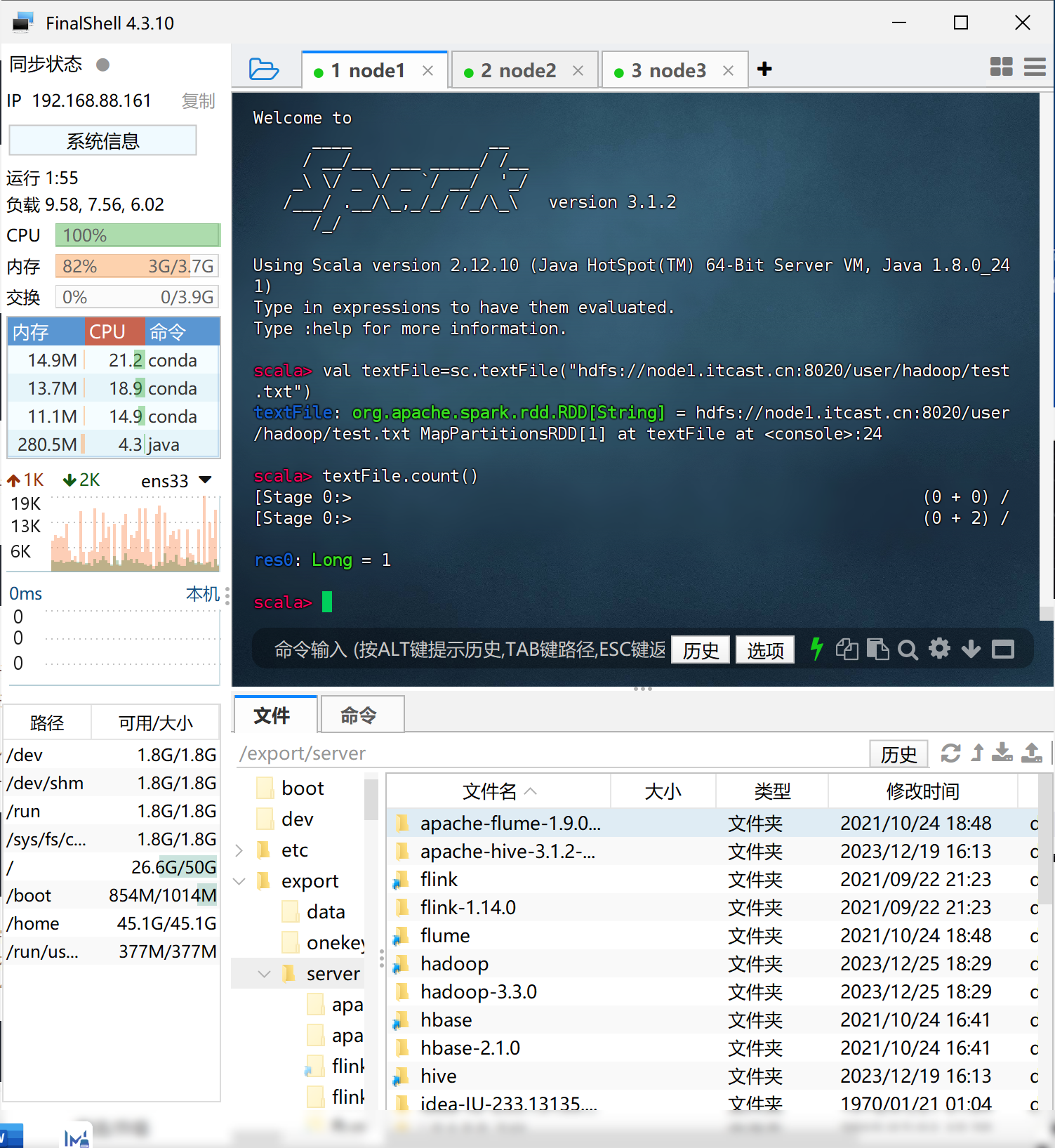
在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;
编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,
并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署