3.awk数组详解及企业实战案例
awk数组详解及企业实战案例
3.打印数组:
[root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]="zhuzhu";for(key in array) print key,array[key]}'1 zhurui2 zhuzhu[root@nfs-server test]#
[root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]="zhuzhu";}END {for(key in array) print key,array[key]}'/etc/hosts1 zhurui2 zhuzhu
把文件内容第一列作为下标,第二列作为值,放入数组然后输出。[root@nfs-server test]# cat t3.log1 zhurui2 zhuzhu[root@nfs-server test]# awk 'BENGIN{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log[root@nfs-server test]# awk '{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log1 zhurui2 zhuzhu

4、脚本:
#!/bin/awkBEGIN{array[1]="zhurui"array[2]="zhuzhu"for(key in array)print key,array[key];}
[root@nfs-server test]# awk -f t2.awk1 zhurui2 zhuzhu[root@nfs-server test]#
5.把文件内容第一列作为下标k,第二列作为值S[k],放入数组S[]然后输出。
[root@nfs-server test]# cat t3.log1 zhurui2 zhuzhu[root@nfs-server test]# awk 'BENGIN{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log[root@nfs-server test]# awk '{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log1 zhurui2 zhuzhu
运用综上理解,请做考试题:处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和SOHU面试题)
test.log
[root@nfs-server test]# awk -F "/"'{S[$3]=S[$3]+1;}END{for(k in S) print k,S[k]}' test.logmp3.judong.org 1post.judong.org 2www.judong.org 3
最终答案:
[root@nfs-server test]# awk -F "/"'{S[$3]++}END{for(k in S) print k,S[k]}' test.log|sort -rn -k2|headwww.judong.org 3post.judong.org 2mp3.judong.org 1[root@nfs-server test]#
例3:统计Web日志单IP访问排名(这个工作中常用,面试也常用)
对于统计访问连接IP个数的答案为:
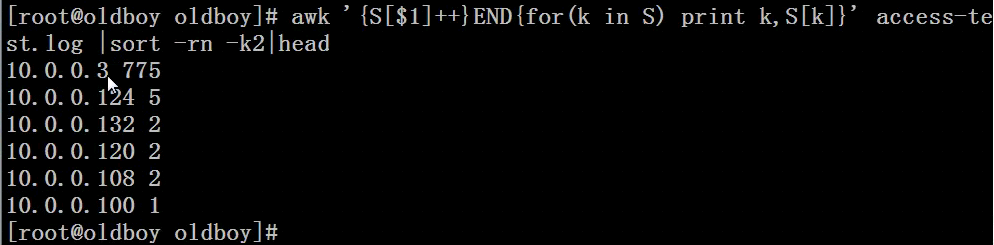
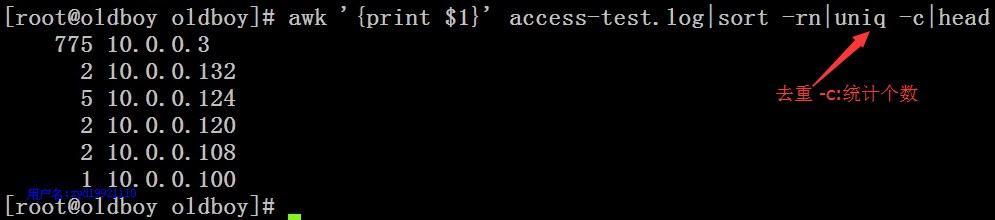
[root@nfs-server test]# awk -F " "'{S[$1]=S[$1]+1;}END{for (k in S) print k,S[k]}' access-test.log|sort -rn|head ##此方法较复杂10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001[root@nfs-server test]# awk -F " "'{S[$1]++;}END{for (k in S) print k,S[k]}' access-test.log|sort -rn|head ##上一步的简化版10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001[root@nfs-server test]# awk -F " "'{Z[$1]++;}END{for (k in Z) print k,Z[k]}' access-test.log|sort -rn|head10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001
方法1:
方法2:
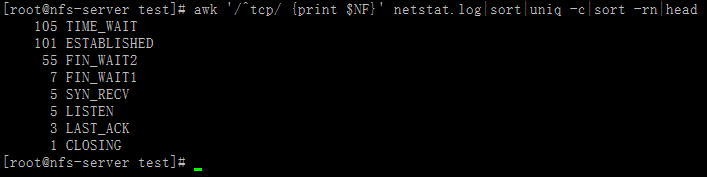
例4:统计企业工作中高并发linux服务器不同网络连接状态对应的数量

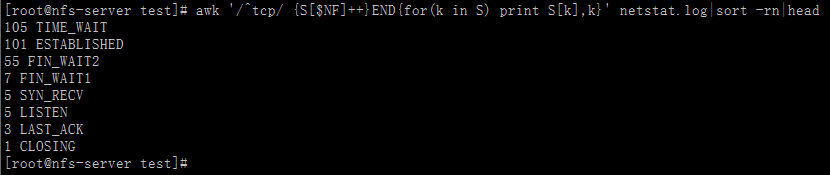
方法1:
[root@nfs-server test]# awk '/^tcp/ {S[$NF]++}END{for(k in S) print S[k],k}' netstat.log|sort -rn|head105 TIME_WAIT101 ESTABLISHED55 FIN_WAIT27 FIN_WAIT15 SYN_RECV5 LISTEN3 LAST_ACK1 CLOSING[root@nfs-server test]#
方法2:
[root@nfs-server test]# awk '/^tcp/ {print $NF}' netstat.log|sort|uniq -c|sort -rn|head105 TIME_WAIT101 ESTABLISHED55 FIN_WAIT27 FIN_WAIT15 SYN_RECV5 LISTEN3 LAST_ACK1 CLOSING[root@nfs-server test]#
例5:
分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小
########## 今天的苦逼是为了不这样一直苦逼下去!##########

 浙公网安备 33010602011771号
浙公网安备 33010602011771号