Flink流式计算
1、spark:DStream
Flink:DataStream
2、Flink Time
处理乱序 watemark(水位线机制)
3、个别数据
4、状态容错(面试项目重点)
5、Flink+Kafka项目应用
数据源-------》数据采集-----》kafka-----》流计算(spark/Flink)------》数据输出
获取的每个变量都不可以变 分布式缓存 1、flink(hadoop) 例子: hdfs://mycluster/user/hiver/user.log 自定义RichMapFuntion 2.1通过nc发送数据 [root@hadoop3-1 ~]# nc -lk 9999 2.2启动flink 应用 2.3窗口触发 key:9527,eventtime:[2020-02-22 16:16:34.000],currentMaxTimestamp:[2020-02-22 16:16:34.000],watermark:[2020-02-22 16:16:24.000] (9527),窗口元素个数:[1],窗口元素最小值:[2020-02-22 16:16:22.000],窗口元素最大值:[2020-02-22 16:16:22.000],窗口起始值:[2020-02-22 16:16:21.000],窗口结束值:[2020-02-22 16:16:24.000] 3.测试总结: window窗口大小间隔跟TumblingEventTimeWindows.of(Time.seconds(3)设置有关,但是窗口的起始值和结束值跟数据本身没有关系,而是系统定义好的。 窗口触发计算需要满足两个条件 a)watermark时间>=window_endtime b)[window_starttime,window_endtime)窗口中必须有至少输入数据
案例:
package com.djt.flink.BACD; import org.apache.commons.io.FileUtils; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import java.io.File; import java.util.ArrayList; import java.util.HashMap; import java.util.List; /** * @author dajiangtai * @create 2020-02-18-17:29 */ public class DistributedCacheDemo { public static void main(String[] args) throws Exception{ //获取运行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //1.添加分布式缓存文件 env.registerCachedFile("D:\\study\\data\\2020\\city.txt","city.txt"); //源数据 ArrayList<Tuple2<Integer, String>> list = new ArrayList<>(); list.add(new Tuple2(101,"1.1万亿")); list.add(new Tuple2(102,"1万亿")); list.add(new Tuple2(103,"8千亿")); DataSource<Tuple2<Integer,String>> data = env.fromCollection(list); DataSet<String> result = data.map(new RichMapFunction<Tuple2<Integer,String>, String>() { HashMap<Integer, String> allMap = new HashMap<Integer, String>(); @Override public void open(Configuration parameters) throws Exception { super.open(parameters); //2.获取分布式缓存文件 File myFile = getRuntimeContext().getDistributedCache().getFile("city.txt"); List<String> lines = FileUtils.readLines(myFile); for (String line : lines) { String[] split = line.split(","); allMap.put(Integer.parseInt(split[0]),split[1]); System.out.println("line:" + line); } } @Override public String map(Tuple2<Integer,String> value) throws Exception { //3.使用分布式缓存文件 String province = allMap.get(value.f0); return province+","+value.f1; } }); result.print(); } }
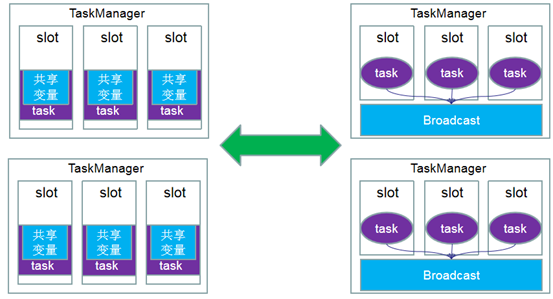
总结:可以理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。如果不使用broadcast,则在每个节点中的每个task中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
用法
1:初始化数据
DataSet<Integer> toBroadcast = env.fromElements(1, 2, 3)
2:广播数据
.withBroadcastSet(toBroadcast, "broadcastSetName");
3:获取数据
Collection<Integer> broadcastSet = getRuntimeContext().getBroadcastVariable("broadcastSetName");
触发了30到33的数据
########## 今天的苦逼是为了不这样一直苦逼下去!##########

 浙公网安备 33010602011771号
浙公网安备 33010602011771号