Python之路【第二篇】:Python基本数据类型
Python基础
对于Python,一切事物都是对象,对象基于类创建
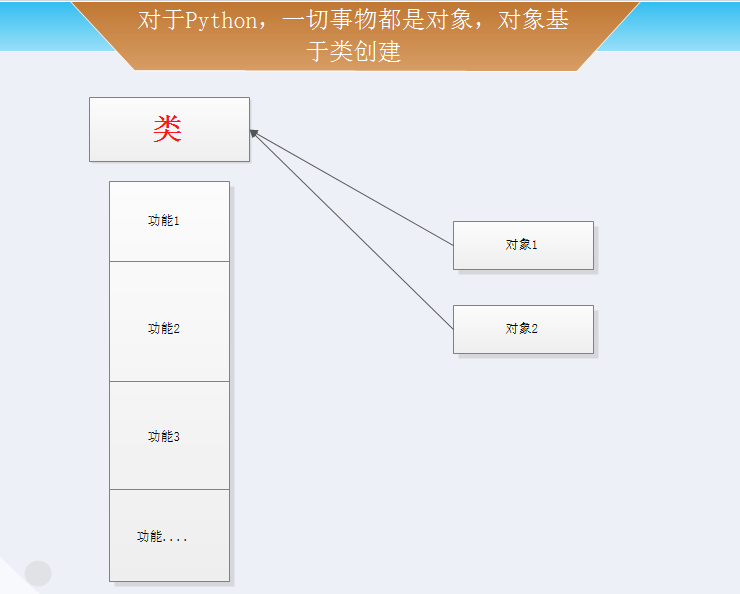
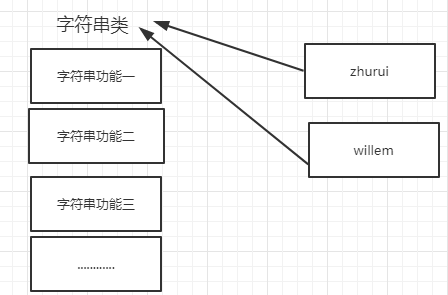
所以,以下这些值都时对象:"zhurui"、22、['北京','上海','深圳'],并且是根据不同的类生成的对象。
一、基本数据类型
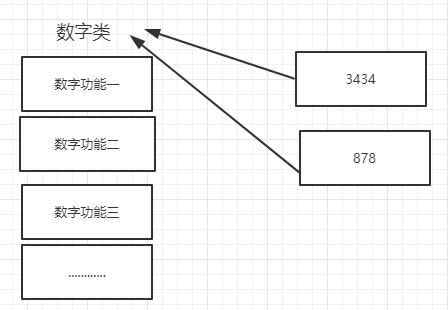
数字(int)
如:21、45、56
每一个整数都具备如下功能:
1 - int
2 将字符串转换为数字
3 例子:
4 a = "123"
5 print(type(a),a)
6 输出结果:
7 >>> a = "123"
8 >>> print(type(a),a)
9 <class 'str'> 123
10
11 b = int(a)
12 print(type(b),b)
13
14 输出结果:
15 >>> b = int(a)
16 >>> print(type(b),b)
17 <class 'int'> 123
18
19 num = "0022"
20 v = int(num, base=16)
21 print(v)
22
23 输出结果:
24 >>> num = "0022"
25 >>> v = int(num, base=16)
26 >>> print(v)
27 34
28
29 - bit_length
30 #当前数字的二进制,至少用n位表示
31 age = 22
32 v = age.bit_length()
33 print(v)
34
35 输出结果:
36 >>> age = 22
37 >>> v = age.bit_length()
38 >>> print(v)
39 5
字符串(str)
1、name.capitalize() #首字母大写
例子:
>>> test = "zhUrui"
>>> v = test.capitalize()
>>> print(v)
Zhurui
2、name.casefold() #所有变小写,casefold更牛逼,很多未知的对相应变小写
例子:
>>> test = "zhUrui"
>>> v1 = test.casefold()
>>> print(v1)
zhurui
>>> v2 = test.lower()
>>> print(v2)
zhurui
3、name.center() #设置宽度,并将内容居中
name.ljust() #设置宽度,变量向左,其他部分用所定义的填充符 填充
name.rjust() #设置宽度,变量向右,其他部分用所定义的填充符 填充
name.zfill() #设置宽度,默认变量向右,其他部分用zfill方法特定的填充符"000" 填充
>>> test = "zhurui"
>>> v = test.center(20,"中")
>>> print(v)
中中中中中中中zhurui中中中中中中中
解释:
# 20 代指总长度
# * 空白未知填充,一个字符,可有可无
输出结果:
中中中中中中中zhurui中中中中中中中
##########################################
>>> test = "zhurui"
>>> v = test.ljust(20,"*") #ljust 变量靠左,其他部分用*填充
>>> print(v)
zhurui**************
##################################
>>> test = "zhurui"
>>> v = test.rjust(20,"*") #rjust 变量靠右,其他部分用*填充
>>> print(v)
**************zhurui
>>> test = "zhurui"
>>> v = test.zfill(20) ##zfill只能用于000填充
>>> print(v)
00000000000000zhurui
4、name.count() #去字符串中寻找,寻找子序列的出现次数
>>> test = "Zhuruizhuruiru"
>>> v = test.count('ru')
>>> print(v)
3
>>> v = test.count('z')
>>> print(v)
1
#########################################
>>> test = "Zhuruizhuruiru"
>>> v = test.count('ru', 5, 6)
>>> print(v)
0
5、name.encode() #将字符串编码成bytes格式
6、name.decode()
7、name.endswith("ui") #判断字符串是否以ui结尾
name.startswith('ui') #判断字符串是否以ui开始
>>> test = "zhurui"
>>> v = test.endswith('ui')
>>> print(v)
True
>>> v = test.startswith('ui')
>>> print(v)
False
8、"Zhu\tRui".expandtabs(10) #输出‘Zhu Rui’, 将\t转换为多长的空格
>>> test = "Zhu\tRui"
>>> v = test.expandtabs(10)
>>> print(v)
Zhu Rui
################################
test = "username\tpassword\temail\nzhurui\t123456\t24731701@qq.com\nzhurui\t123456\t24731701@qq.com\nzhurui\t123456\t24731701@qq.com"
v = test.expandtabs(20)
print(v)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day1/logging.py
username password email
zhurui 123456 24731701@qq.com
zhurui 123456 24731701@qq.com
zhurui 123456 24731701@qq.com
9、name.find(A) #从开始往后找,找到第一个之后,获取其位置即索引,找不到返回-1
## > 或 >=
# 未找到 -1
>>> test = "williamwilliam" >>> v = test.find('am') >>> print(v) 5 >>> v = test.find('t') #找变量中的"t"字符, >>> print(v) -1 ##没有找到,返回负一
10、name.index('a') #找不到,报错
>>> test = "williamwilliam"
>>> v = test.index('a')
>>> print(v)
5
>>> v = test.index('8') ##找字符串中是否
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
11、name.format() #格式化,将一个字符串中的占位符替换为指定的值
>>> test = 'i am {name}, age {a}'
>>> print(test)
i am {name}, age {a}
>>> v = test.format(name='william',a=22)
>>> print(v)
i am william, age 22
>>> test = 'i am {0},age {1}'
>>> print(test)
i am {0},age {1}
>>> v = test.format('william', 22)
>>> print(v)
i am william,age 22
12、name.format_map() #格式化, 传入的值{"name": 'william', "a": 22}
>>> test = 'i am {name}, age {a}'
>>> v1 = test.format(name='zhurui',a=22)
>>> v2 = test.format_map({"name":'zhurui', "a": 19})
>>> print(v1)
i am zhurui, age 22
>>> print(v2)
i am zhurui, age 19
13、name.isalnum() #字符串中是否只包含 字母和数字
>>> test = "234"
>>> v = test.isalnum()
>>> print(v)
True
14、name.isalpha() #是否是字母,汉字
>>> test = "asfdge242"
>>> v = test.isalpha()
>>> print(v)
False
>>> test = "威廉"
>>> v = test.isalpha()
>>> print(v)
True
15、判断输入的是否是数字
>>> test = "二" # 1 , ②
>>> v1 = test.isdecimal ##判断十进制小数
>>> v2 = test.isdigit()
>>> v3 = test.isnumeric() ##判断汉语的数字,比如 "二"
>>> print(v1,v2,v3)
<built-in method isdecimal of str object at 0x00000201FE440AB0> False True
16、name.isprintable() #判断是否存在不可显示的字符
\t 制表符
\n 换行
>>> test = "qepoetewt\tfdfde" >>> v = test.isprintable() >>> print(v) False >>> test = "qepoetewtfdfde" >>> v = test.isprintable() >>> print(v) True
17、name.isspace() #判断是否全部是空格
>>> test = ""
>>> v = test.isspace()
>>> print(v)
False
>>> test = " "
>>> v = test.isspace()
>>> print(v)
True
18、name.istitle() #判断是否是标题,其中必须首字母大写
>>> test = "Return True if all cased characters in S are uppercase"
>>> v1 = test.istitle()
>>> print(v1)
False
>>> v2 = test.title() #将字符串首字母大写
>>> print(v2)
Return True If All Cased Characters In S Are Uppercase
>>> v3= v2.istitle()
>>> print(v3)
True
19、***** name.join() #将字符串中的每一个元素按照指定分隔符进行拼接(五星重点参数)
>>> test = "出任CEO迎娶白富美"
>>> print(test)
出任CEO迎娶白富美
>>> v = '_'.join(test)
>>> print(v)
出_任_C_E_O_迎_娶_白_富_美
>>>
20、name.islower() #判断是否全部是大小写 和 转换为大小写
>>> test = "William"
>>> v1 =test.islower() #判断是否全都是小写
>>> v2 = test.lower() #将变量转换为小写
>>> print(v1, v2)
False william
>>>
###################################
>>> test = "William"
>>> v1 =test.isupper() #判断是否全都是大写
>>> v2 = test.upper() #将变量转换为大写
>>> print(v1, v2)
False WILLIAM
21、移除指定字符串,优先最多匹配
>>> test = 'xa'
>>> v1 =test.isupper()
>>> v = test.lstrip("xa")
>>> print(v)
>>> v = test.rstrip("92exxxexxa")
>>> print(v)
>>> v = test.strip("xa")
>>> print(v)
###################################
# test.lstrip()
# test.rstrip()
# test.strip()
# 去除左右空白
# v = test.lstrip()
# v = test.rstrip()
# v = test.strip()
# print(v)
# print(test)
# 去除\t \n
# v = test.lstrip()
# v = test.rstrip()
# v = test.strip()
# print(v)
22、对应关系替换
>>> test = "aeiou"
>>> test1 = "12345"
>>> v = "asidufkasd;fiuadkf;adfkjalsdjf"
>>> m = str.maketrans("aeiou", "12345")
>>> new_v = v.translate(m)
>>> print(new_v)
1s3d5fk1sd;f351dkf;1dfkj1lsdjf
23、name.partition() #分割为三部分
>>> test = "testegerwerwegwewe"
>>> v = test.partition('s')
>>> print(v)
('te', 's', 'tegerwerwegwewe')
>>> v = test.rpartition('s')
>>> print(v)
('te', 's', 'tegerwerwegwewe')
>>>
24、name.split() #分格为指定个数
>>> test = "sagesgegessress"
>>> v = test.split('s',2)
>>> print(v)
['', 'age', 'gegessress']
>>>
25、分割, 只能根据,true, false:是否保留换行
>>> test = "fwerwerdf\frweqnndasfq\fnaqewrwe"
>>> v = test.splitlines(False)
>>> print(v)
['fwerwerdf', 'rweqnndasfq', 'naqewrwe']
26、以xxx开头,以xx结尾
>>> test = "backend 1.2.3.4"
>>> v = test.startswith('a')
>>> print(v)
False
>>> test.endswith('a')
False
27、name.swapcase() #大小写转换
>>> test = "WiiLiAm"
>>> v = test.swapcase()
>>> print(v)
wIIlIaM
28、name.isidentifier() #字母,数字,下划线 :标识符 def class
>>> a = "def"
>>> v = a.isidentifier()
>>> print(v)
True
29、name.replace() #将指定字符串替换为指定字符串,替换功能相当于sed
>>> test = "williamwilliamwilliam"
>>> v = test.replace("am", "bbb")
>>> print(v)
willibbbwillibbbwillibbb
>>> v = test.replace("am", "bbb",2)
>>> print(v)
willibbbwillibbbwilliam
>>>
字符串总结
################7个基本魔法#################
join # '_'.join("asdfdfsdsf")
split
find
strip
upper
lower
replace(相当于sed替换功能)
################4个灰魔法#################
一、for循环
格式:
for 变量名 in 字符串:
变量名
break
continue
例子:
test = "好看的妹子有种冲我来"
for item in test:
print(item)
break
输出结果为:
好
例子2:
test = "好看的妹子有种冲我来"
index = 0
while index < len(test):
v = test[index]
print(v)
index += 1
print('============')
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day12/index1.py
好
看
的
妹
子
有
种
冲
我
来
============
例子3:(比较break跟continue的区别)
test = "好看的妹子有种冲我来"
for item in test:
print(item)
break
输出结果为:
好
for item in test:
print(item)
continue
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day12/index1.py
好
看
的
妹
子
有
种
冲
我
来
二、索引,下标,获取字符串中的某一个字符
test = "好看的妹子有种冲我来"
v = test[3]
print(v)
输出结果为:
妹
三、切片
v = test[0:1] #标识大于等于0,小于1(0<= <1)
print(v)
输出结果为:
好
四、获取长度
Python3: len获取当前字符串中由几个字符组成
v = len(test)
print(v)
输出结果为:
10
注意:
len("asdf")
for循环
索引
切片
五、获取连续或不连续的数字
Python2中直接创建在内容中
Python3中只有for循环时,才一个一个创建
例子:
r1 = range(10)
print(r1)
输出结果为:
10
range(0, 10)
执行for循环时:
才会一个一个创建打印
r2 = range(1,10)
r3 = range(1,10,2)
帮助创建连续的数字,通过设置步长来指定不连续
v = range(0, 100, 5) #括号中的5代表步长
for item in v:
print(item)
练习题:根据用户输入的值,输出每一个字符以及当前字符所在的索引位置
将文字 对应的索引打印出来:
方法1:
test = input(">>>")
print(test) # test = qwe test[0] test[1]
l = len(test) # l = 3
print(l)
r = range(0,l) # 0,3
for item in r:
print(item, test[item]) # 0 q,1 w,2 e
方法2:
test = input('>>>')
for item in range(0, len(test)):
print(item, test[item])
##################### 1个深灰魔法 ######################
字符串一旦创建,不可修改
一旦修改或者拼接,都会造成重新生成字符串
name = "william"
age = "22"
info = name + age
print(info)
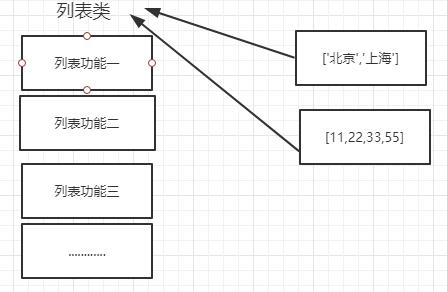
列表(list)
如:["william",'zhurui']、["ray","william"]
#################深灰魔法#####################
1、列表格式
# 中括号括起来 # , 逗号分隔每个元素 # 列表中的元素可以是 数字,字符串,列表,布尔值.. 所有的都能放进去 # “集合”, 内部放置任何东西
2、列表中可以嵌套任何类型
# 列表中的元素可以是 数字,字符串,列表,布尔值.. 所有的都能放进去 # “集合”, 内部放置任何东西
3、索引取值
# list # 类,列表
li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True] # 通过list类创建的对象,li
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> print(li[2])
9
>>> print(li[4][0])
朱锐
4、切片,切片结果也是列表
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> print(li[3:-1])
['age', ['朱锐', ['19', 10], '朱'], 'william']
5、列表是可迭代的所以for循环、while循环都通用
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> for item in li:
... print(item)
...
1
12
9
age
['朱锐', ['19', 10], '朱']
william
True
>>>
####列表元素,可以被修改
6、通过索引的方式修改
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> li[0] = "zhurui"
>>> print(li)
['zhurui', 12, 9, 'age', ['朱锐', ['19', 10], '朱'], 'william', True]
>>> li[1] = [11,22,44] #将原来索引1所对应内存中的12,赋值一个新的列表[11,22,44]
>>> print(li)
['zhurui', [11, 22, 44], 9, 'age', ['朱锐', ['19', 10], '朱'], 'william', True]
>>>
7、通过切片的方式修改列表中的元素
#修改中还有一个特殊的方法del
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> del li[1]
>>> print(li)
[1, 9, 'age', ['朱锐', ['19', 10], '朱'], 'william', True]
>>>
#通过切片的方式删除
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> del li[2:6] #2<= <6
>>> print(li)
[1, 12, True]
>>>
#通过切片的方式修改
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> li[1:3] = [120,90]
>>> print(li)
[1, 120, 90, 'age', ['朱锐', ['19', 10], '朱'], 'william', True]
>>>
8、in 操作
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True] >>> v1 = "朱锐" in li >>> print(v1) False >>> v2 = "age" in li >>> print(v2) True >>> v3 = "william" in li >>> print(v3) True
####列表中的元素
9、操作
>>> li = [1, 12, 9, "age", ["朱锐", ["19", 10], "朱"], "william", True]
>>> li[4][1][0]
'19'
10、转换
>>> s = 123
>>> a = "123"
>>> int(a) #将字符串转换为数字
123
>>> a = 123
>>> str(a) #将数字转换为字符串
'123'
##字符串转换为列表
>>> li = list("asdfgeqrererdfgaf") #字符串转换为列表实质是内部使用了for循环
>>> print(li)
['a', 's', 'd', 'f', 'g', 'e', 'q', 'r', 'e', 'r', 'e', 'r', 'd', 'f', 'g', 'a', 'f']
>>>
>>> s = "erewsfsasdfe"
>>> new_li = list(s)
>>> print(new_li)
['e', 'r', 'e', 'w', 's', 'f', 's', 'a', 's', 'd', 'f', 'e']
##列表转换为字符串,有两种处理方法:
1、需要自己写for循环一个一个处理:
>>> li = [12,14,146,"343","william"]
>>> r = str(li)
>>> print(r)
[12, 14, 146, '343', 'william'] #当直接将列表使用str转换为字符串时,其他的都无变化,只是双引号变为单引号
>>> s = "" #定义一个空的字符串
>>> for i in li: #循环列表
... s += str(i) #使用for循环将列表中的元素转换为字符串与空字符串相加,得到新的变量s
...
>>> print(s)
1214146343william
2、直接使用字符串join方法:只仅仅适用于列表中的元素只有字符串
>>> li = ["4324","william"]
>>> v = "".join(li)
>>> print(v)
4324william
##补充:字符串创建后,不可修改
>>> v = "william"
>>> v = v.replace('w','am') #使用字符串的方法,将w替换为am
>>> print(v)
amilliam
>>> li = [11,232,434,45]
>>> li[0]
11
>>> li[0] = 999 #重新赋值标识为的值
>>> print(li)
[999, 232, 434, 45]
##字符串创建后,如果修改会报错
>>> s = "william"
>>> s[0]
'w'
>>> s[0] = "E"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
##############灰魔法: list类中提供的方法#####################
1、原来值最后追加,不需要再定义变量
#参数
# 对象.方法(..) #li对象调用append方法
>>> li = [13,15,45,56,78]
>>> li.append(5)
>>> li.append("william")
>>> li.append([134,34232])
>>> print(li)
[13, 15, 45, 56, 78, 5, 'william', [134, 34232]]
>>>
2、清空列表
>>> print(li)
[13, 15, 45, 56, 78, 5, 'william', [134, 34232]]
>>> v = list(li)
>>> print(v)
[13, 15, 45, 56, 78, 5, 'william', [134, 34232]]
>>> v.clear()
>>> print(v)
[] #列表为空
3、拷贝,浅拷贝,需要新值接收
>>> li = [12,13,14,15,16]
>>> v = li.copy()
>>> print(v)
[12, 13, 14, 15, 16]
>>>
4、计算元素出现的次数
>>> li = [12,13,14,13,16]
>>> v = li.count(13)
>>> print(v)
2
5、扩展原列表,参数:可迭代对象,内部执行for循环
>>> li = [11,22,33,44,22,45]
>>> li.append([798, "朱锐"])
>>> print(li)
[11, 22, 33, 44, 22, 45, [798, '朱锐']]
>>>
>>> li.extend([798,"朱锐"]) #extend的实质就是下面执行的for循环中append追加
>>> print(li)
[11, 22, 33, 44, 22, 45, [798, '朱锐'], 798, '朱锐']
>>> for i in [798, "朱锐"]:
... li.append(i)
...
>>> print(li)
[11, 22, 33, 44, 22, 45, [798, '朱锐'], 798, '朱锐', 798, '朱锐']
6、根据值获取当前值索引位置(左边优先)
>>> li = [12,14,15,16,18,45]
>>> v = li.index(15)
>>> print(v)
2
7、在指定索引位置插入元素
>>> li = [12,14,15,16,18,45]
>>> li.insert(0,99)
>>> print(li)
[99, 12, 14, 15, 16, 18, 45]
8、删除某个值(1.指定索引;2.默认最后一个),并获取删除的值
>>> li = [12,14,15,16,18,45]
>>> v = li.pop()
>>> print(li)
[12, 14, 15, 16, 18]
>>> print(v)
45
>>>
>>> li = [12,14,15,16,18,45]
>>> v = li.pop(3) #跟索引的值,删除索引的值
>>> print(li)
[12, 14, 15, 18, 45]
>>> print(v)
16
9、删除列表中的指定值,左边优先
>>> li = [12,14,15,16,18,45]
>>> li.remove(14)
>>> print(li)
[12, 15, 16, 18, 45]
10、将当前列表进行翻转
>>> li = [12,14,15,16,18,45]
>>> li.reverse()
>>> print(li)
[45, 18, 16, 15, 14, 12]
>>>
11、列表的排序
>>> li = [13,34,23,12,45,67]
>>> li.sort()
>>> print(li)
[12, 13, 23, 34, 45, 67]
>>> li.sort(reverse=True)
>>> print(li)
[67, 45, 34, 23, 13, 12]
后面更新:
#cmp
#key
#sorted
总结:
################################################ # 列表,有序,元素可以被修改 # 列表 # list # li = [111.345,345,456] ################################################ # 元祖,元素不可被修改,不能被增加或者删除 # tuple # tu = (11,22,33,44,) # tu.count(22) 获取指定元素在元祖中出现的次数 # tu.index(22)
元祖(tuple)
################# 深灰魔法 ##################
1、书写格式
# tu = (123,"william",(11,22),[(33,34)],True,34,56,) # 一般写元祖的时候,推荐在最后加,"逗号"; # 元素不可被修改,不能被增加或者删除
2、索引
>>> tu = (123,"william",(11,22),[(33,34)],True,34,56,)
>>> v = tu[1]
>>> print(v)
william
3、切片
>>> tu = (123,"william",(11,22),[(33,34)],True,34,56,)
>>> r = tu[0:2]
>>> print(r)
(123, 'william')
4、可以被for循环,可迭代对象
>>> tu = (123,"william",(11,22),[(33,34)],True,34,56,)
>>> for item in tu:
... print(item)
...
123
william
(11, 22)
[(33, 34)]
True
34
56
5、转换
>>> s = "asdfgher"
>>> li = ["asdfg","asgewerf"]
>>> tu = ("asdf","asfdf")
>>> v = tuple(s) #字符串转换为元祖
>>> print(v)
('a', 's', 'd', 'f', 'g', 'h', 'e', 'r')
>>> v = tuple(li) #列表转换为元祖
>>> print(v)
('asdfg', 'asgewerf')
>>> v = "_".join(tu) #使用分隔符,将元祖分开
>>> print(v)
asdf_asfdf
>>> li = ["asdf","asdfdghsd"]
>>> li.extend((11,22,33)) #列表后面追加元祖,效果就是将元祖的特征小括号去掉,直接将元素追加到后面
>>> print(li)
['asdf', 'asdfdghsd', 11, 22, 33]
6、元祖的一级元素不可修改/删除/增加
>>> tu = (111,"william",(11,22),[(33,44)],True,33,44,)
>>> v = tu[3][0][0] #根据索引取值
>>> print(v)
33
>>> v = tu[3]
>>> print(v)
[(33, 44)]
>>> tu[3][0] = 789 #根据索引间接修改值
>>> print(tu)
(111, 'william', (11, 22), [789], True, 33, 44)
>>>
字典(dict)
字典一种 key - value 的数据类型,使用就像我们上学用的字典,通过笔画、字母来查对应页的详细内容。
1、基本结构:
#字典
#dict
dit = {
"k1":"v1" #键值对
"k2":"v2"
}
字典的特性:
● dict是无序的
● key必须是唯一的,所以天生去重
2、字典的value可以是任何值
>>> info = {
... "k1": 18,
... "k2": True,
... "k3": [
... 11,
... [],
... (),
... 22,
... 33,yy
... {
... 'kk1': 'vv1',
... 'kk2': 'vv2',
... 'kk3': (11,22),
... }
... ],
... "k4": (11,22,33,44)
... }
>>> print(info)
{'k1': 18, 'k3': [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}], 'k4': (11, 22, 33, 44), 'k2': True}
>>>
3、布尔值(1,0)、列表、字典不能作为字典的key
>>> info ={
... 1: 'asdf',
... "k1": 'asdf',
... True: "123",
... # [11,22]: 123
... (11,22): 123,
... # {'k1':'v1'}: 123
...
... }
>>> print(info)
{'k1': 'asdf', 1: '123', (11, 22): 123}
>>> info ={
... 1: 'asdf',
... "k1": 'asdf',
... True: "123",
... [11,22]: 123 #列表不能作为字典的key,否则会报错
... # {'k1':'v1'}: 123
...
... }
Traceback (most recent call last):
File "<stdin>", line 5, in <module>
TypeError: unhashable type: 'list'
>>> info ={
... 1: 'asdf',
... "k1": 'asdf',
... True: "123",
... #[11,22]: 123
... {'k1':'v1'}: 123 #字典不能作为字典的key,否则会报错
...
... }
Traceback (most recent call last):
File "<stdin>", line 6, in <module>
TypeError: unhashable type: 'dict'
>>>
4、字典无序
>>> info = {
... "k1": 18,
... "k2": True,
... "k3": [
... 11,
... [],
... (),
... 22,
... 33,
... {
... 'kk1': 'vv1',
... 'kk2': 'vv2',
... 'kk3': (11,22),
... }
... ],
... "k4": (11,22,33,44)
... }
>>> print(info)
{'k1': 18, 'k4': (11, 22, 33, 44), 'k2': True, 'k3': [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]}
>>>
5、索引方式找到指点元素
>>> info = {
... "k1": 18,
... 2: True,
... "k3": [
... 11,
... [],
... (),
... 22,
... 33,
... {
... 'kk1': 'vv1',
... 'kk2': 'vv2',
... 'kk3': (11,22),
... }
... ],
... "k4": (11,22,33,44)
... }
输出结果:
>>> v = info['k1']
>>> print(v)
18
>>> v = info[2]
>>> print(v)
True
>>> v = info['k3'][5]['kk3'][0]
>>> print(v)
11
6、字典支持del删除
>>> info = {
... "k1": 18,
... 2: True,
... "k3": [
... 11,
... [],
... (),
... 22,
... 33,
... {
... 'kk1': 'vv1',
... 'kk2': 'vv2',
... 'kk3': (11,22),
... }
... ],
... "k4": (11,22,33,44)
... }
>>> del info['k1']
>>> del info['k3'][5]['kk1']
>>> print(info)
{'k4': (11, 22, 33, 44), 2: True, 'k3': [11, [], (), 22, 33, {'kk2': 'vv2', 'kk3': (11, 22)}]}
7、for循环
>>> info = {
... "k1": 18,
... 2: True,
... "k3": [
... 11,
... [],
... (),
... 22,
... 33,
... {
... 'kk1': 'vv1',
... 'kk2': 'vv2',
... 'kk3': (11,22),
... }
... ],
... "k4": (11,22,33,44)
... }
>>> for item in info:
... print(item)
...
k1
k4
2
k3
>>> for item in info.keys():
... print(item)
...
k1
k4
2
k3
>>> for item in info.values():
... print(item)
...
18
(11, 22, 33, 44)
True
[11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
>>>
##以下两种方法等价于
>>> for item in info.keys():
... print(item,info[item])
...
k1 18
k4 (11, 22, 33, 44)
2 True
k3 [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
>>>
>>> for k,v in info.items(): #会把dict转成list,数据量大时莫用
... print(k,v)
...
k1 18
k4 (11, 22, 33, 44)
2 True
k3 [11, [], (), 22, 33, {'kk1': 'vv1', 'kk2': 'vv2', 'kk3': (11, 22)}]
>>>
补充关于布尔值:
8、根据序列,创建字典,并指定统一的值
>>> v = dict.fromkeys(["k1",123,"999"],123) #分别指定列表中元素作为key,而123作为value,创建新的字典
>>> print(v)
{'999': 123, 'k1': 123, 123: 123}
>>> v = dict.fromkeys(("k1",123,"999",),123) #分别指定元祖中元素作为key,而123作为value,创建新的字典
>>> print(v)
{'999': 123, 'k1': 123, 123: 123} #生成新的字典
>>>
9、根据key获取值,key不存在时,可以指定默认值(None)
v= dic['k12121312']
print(v)
v = dic.get('k1',11111)
print(v)
10、删除并获取值
>>> v = dic.pop('k1',90)
>>> print(dic,v)
{'k2': 'v2'} v1
>>> dic = {
... "k1": 'v1',
... "k2": 'v2'
... }
>>> v = dic.pop("k1")
>>> print(v)
v1
>>> print(dic)
{'k2': 'v2'}
>>> k,v = dic.popitem()
>>> print(dic,k,v)
{} k2 v2
11、设置值
#已存在,不设置,获取当前key对应的值
#不存在,设置,获取当前key对应的值
>>> dic = {
... "k1": 'v1',
... "k2": 'v2'
... }
>>> v = dic.setdefault('k1111','123')
>>> print(dic,v)
{'k1111': '123', 'k1': 'v1', 'k2': 'v2'} 123
>>>
12、更新
>>> dic = {
... "k1":'v1',
... "k2":'v2'
... }
>>> dic.update({'k1':'11dfe','k3':123})
>>> print(dic)
{'k3': 123, 'k1': '11dfe', 'k2': 'v2'}
>>>
>>> dic.update(k1=236,k3=345,k5="asdf")
>>> print(dic)
{'k3': 345, 'k5': 'asdf', 'k1': 236, 'k2': 'v2'}
>>>
###################整理######################
# 一、数字
# int(..)
# 二、字符串
# replace/find/join/strip/startswith/split/upper/lower/format
# tempalte = "i am {name}, age : {age}"
# # v = tempalte.format(name='william',age=22)
# v = tempalte.format(**{"name": 'william1','age': 23})
# print(v)
# 三、列表
# append、extend、insert
# 索引、切片、循环
# 四、元组
# 忽略
# 索引、切片、循环 以及元素不能被修改
# 五、字典
# get/update/keys/values/items
# for,索引
# dic = {
# "k1": 'v1'
# }
# v = "k1" in dic
# print(v)
# v = "v1" in dic.values()
# print(v)
# 六、布尔值
# 0 1
# bool(...)
# None "" () [] {} 0 ==> False
set集合
set是一个无序且不重复的元素集合
作用:去重,关系运算
#定义:
知识点回顾
可变类型是不可hash类型(列表、字典)
不可变类型是可hash类型(数字、字符串、元祖)
#定义集合:
集合:可以包含多个元素,用逗号分割,
集合的元素遵循三个原则:
1、每个元素必须是不可变类型(可hash,可作为字典的key)
2、没有重复的元素
3、无序
注意集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
#优先掌握的操作
#1、长度len
#2、成员运算in和not in
#3、 &交集
#4、 |并集
#5、 -差集
#6、 ^对称差集
#7、 ==
#8、 父集: >,>=
#9、 子集: <,<=
基本操作
1、添加(add())
s = set(['william', 'zhurui', 'grace'])
print(s)
运行结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'william', 'zhurui', 'grace'}
s = {1,2,3,4,5,6}
s.add('s') #添加字符串s
s.add('3') #添加字符串3
s.add(3) #添加数字3,原来集合中有元素3,新的集合是去重后的结果
print(s)
输出结果:
{1, 2, 3, 4, 5, 6, '3', 's'}
2、添加多项(update())
s1 = {1,2}
s2 = {1,2,3}
s1.update(s2)
print(s1)
s1 = {1,2}
s2 = {1,2,3}
s1.update([1,2,3,4])
s1.add() #更新一个值时用到
s1.union(s2) #不更新
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{1, 2, 3, 4}
3、清空(clear())
1 s = {1,2,3,4,5,6}
2 s.clear()
3 print(s)
4 输出结果:
5 C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
6 set()
4、删除(pop(),remove(),discard())
①pop() 随机删
1 s = ['william', 12, 13, 14, 16, 89]
2 s1 = set(s)
3 print(s1)
4 输出结果:
5 C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
6 {12, 13, 14, 16, 'william', 89}
7 s1.pop()
8 print(s1)
9 输出结果为:
10 C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
11 {12, 13, 'william', 14, 16, 89}
12 {13, 'william', 14, 16, 89}
注:pop是随机删除集合中的某个元素;
②remove() 指定删除
s = ['william', 12, 13, 14, 16, 89]
s1 = set(s)
print(s1)
s1.remove('william')
print(s1)
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{89, 12, 13, 14, 16, 'william'}
{89, 12, 13, 14, 16} #跟上面集合对比,william元素被删除
name.remove('zhurui') #删除元素不存在会报错
s = ['william', 12, 13, 14, 16, 89]
s1 = set(s)
s1.remove('zhurui') #zhurui这个元素不存在
print(s1)
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
Traceback (most recent call last):
File "C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py", line 44, in <module>
s1.remove('zhurui')
KeyError: 'zhurui'
name.discard('zhurui') #删除元素不存在不会报错
s = ['william', 12, 13, 14, 16, 89]
s1 = set(s)
s1.discard('zhurui') #删除一个没有的元素,执行结果并没有报错
print(s1)
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'william', 12, 13, 14, 16, 89}
注:用remove删除时,当元素不存在,会报错;
③discard()
s = ['william', 12, 13, 14, 16, 89]
s1 = set(s)
s1.discard('zhurui') #删除一个没有的元素,执行结果并没有报错
print(s1)
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'william', 12, 13, 14, 16, 89}
注:用discard删除不存在的元素时,不会出现报错
5、长度(len())
name_1 = [1,2,3,4,7,8,7,10]
name_1 = set(name_1)
print(len(name_1))
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
7
6、x in s
>>> name_1 = [1,2,3,4,7,8,7,10]
>>> name_1 = set(name_1)
>>> 1 in name_1
True
name_1 = [1,2,3,4,7,8,7,10]
name_1 = set(name_1)
# print(len(name_1))
print(1 in name_1)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
True
7、x not in s
name_1 = [1,2,3,4,7,8,7,10]
name_1 = set(name_1)
# print(len(name_1))
print(13 not in name_1)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
True
关系测试
1、交集(intersection())
python_l=['lcg','szw','zjw','lcg']
linux_l=['lcg','szw','sb']
p_s = set(python_l)
l_s = set(linux_l)
print(p_s, l_s)
print(p_s.intersection(l_s)) #跟&方法方法一样都是求交集
print(p_s&l_s)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'zjw', 'szw', 'lcg'} {'szw', 'lcg', 'sb'}
{'szw', 'lcg'}
{'szw', 'lcg'}
2、并集(union())
python_l=['lcg','szw','zjw','lcg']
linux_l=['lcg','szw','sb']
p_s = set(python_l)
l_s = set(linux_l)
print(p_s, l_s)
print(p_s.union(l_s))
print(p_s|l_s) #并集符号形式表示
输出结果为:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'lcg', 'zjw', 'szw'} {'sb', 'lcg', 'szw'}
{'lcg', 'sb', 'zjw', 'szw'}
{'lcg', 'sb', 'zjw', 'szw'}
3、差集(difference())
python_l=['lcg','szw','zjw','lcg']
linux_l=['lcg','szw','sb']
p_s = set(python_l)
l_s = set(linux_l)
print('差集', p_s-l_s)
print(p_s.difference(l_s))
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
差集 {'zjw'}
{'zjw'}
print('差集', l_s-p_s)
print(l_s.difference(p_s))
输出结果:
差集 {'sb'}
{'sb'}
4、交叉补集(symmetric_difference()) #把两个集合没有交集的数值取出来
python_l=['lcg','szw','zjw','lcg']
linux_l=['lcg','szw','sb']
p_s = set(python_l)
l_s = set(linux_l)
print(p_s, l_s)
print(p_s.symmetric_difference(l_s))
print(p_s^l_s)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
{'lcg', 'zjw', 'szw'} {'lcg', 'szw', 'sb'}
{'zjw', 'sb'} #将两个集合对比,剔除相同部分,差异的部分组成新的集合就是我们想要的结果
5、(difference_update())
python_l = ['lcg', 'szw', 'zjw', 'lcg']
linux_l = ['lcg', 'szw', 'sb']
p_s = set(python_l)
l_s = set(linux_l)
print('差集', p_s-l_s)
p_s.difference_update(l_s)
print(p_s)
6、isdisjoint() #判断两个集合是否有交集,没有交集,则返回True
s1 = {1,2,3,}
s2 = {3,4,5,6}
print(s1.isdisjoint(s2)) #判断二者有无共有部分
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
False #两个集合有交集,返回False
7、issubset() #判断一个集合是否是另一个集合的子集
s1 = {1,2}
s2 = {1,2,3}
print(s1.issubset(s2)) #判断s1 是否是s2的子集,相当于s1 <= s2
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
True
8、issuperset() #判断一个集合是否是另一个集合的父集
s1 = {1,2,3}
s2 = {1,2}
print(s1.issuperset(s2))#s1是s2的父集,为真则返回True
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/set_集合.py
True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号