

一、访问网络的两种方法
1.get:利用参数给服务器传递信息;参数为dict,然后parse解码
2.post:一般向服务器传递参数使用;post是把信息自动加密处理;如果想要使用post信息,需要使用到data参数
3.Content-Type:application/x-www.form-urlencode
4.Content-Length:数据长度
5.简而言之,一旦更改请求方法,请注意其他请求头信息相适应
6.urllib.parse.urlencode可以将字符串自动转换为上面的信息。
案例:利用parse模块模拟post请求分析百度翻译:分析步骤:
(1)打开谷歌浏览器,F12
(2)尝试输入单词girl,发想每敲击一个字母后都会有一个请求
(3)请求地址是:http://fanyi.baidu.com/sug
(4)打开network-XHR-sug
from urllib import request,parse #负责处理json格式的模块 import json """ 大致流程: (1)利用data构造内容,然后urlopen打开 (2)返回一个json格式的结果 (3)结果就应该是girl的释义 """ baseurl = "https://fanyi.baidu.com/sug" #存放迎来模拟form的数据一定是dict格式 data = { #girl是翻译输入的英文内容,应该是由用户输入,此处使用的是硬编码 "kw":"girl" } #需要使用parse模块对data进行编码 data = parse.urlencode(data).encode("utf-8") #我们需要构造一个请求头,请求头应该至少包含传入的数据的长度 #request要求传入的请求头是一个dict格式 headers = { #因为使用了post,至少应该包含content-length字段 "Content-length":len(data) } #有了headers,data,url就可以尝试发出请求了 rsp = request.urlopen(baseurl,data=data)#,headers=headers json_data = rsp.read().decode() print(json_data) #把json字符串转化为字典 json_data = json.loads(json_data) print(json_data) for item in json_data["data"]: print(item["k"],"--",item["v"])
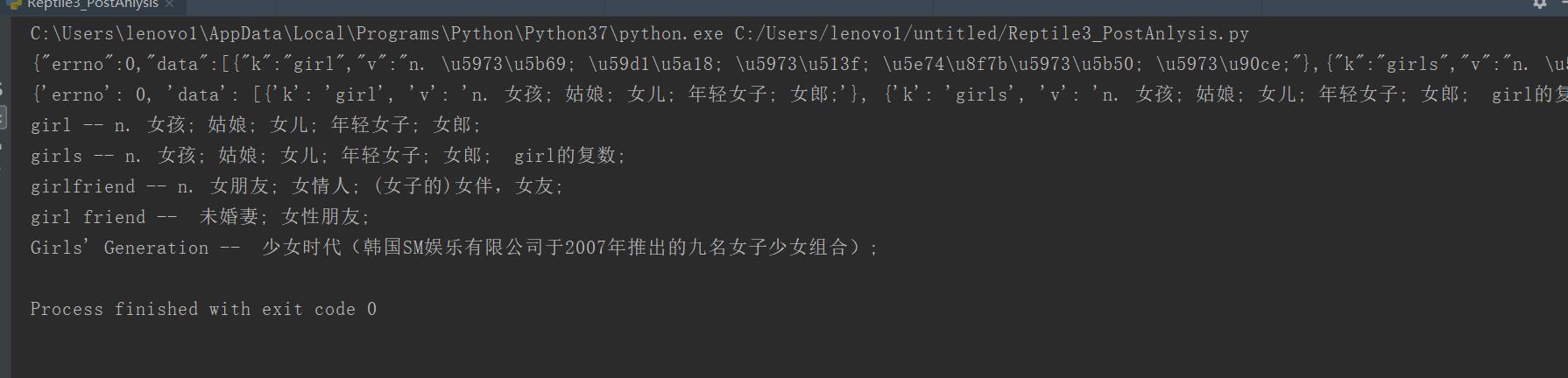
二、为了更多的设置请求信息,单纯的通过urlopen函数已经不太好用了;需要利用request.Request类
这里只修改一部分代码,其他的代码都不变,依然可以得到相同的结果。
#构造一个Request的实例,就是借用这个类,来把能够传入的头信息进行封装扩展 req = request.Request(url=baseurl,data=data,headers=headers) #有了headers,data,url就可以尝试发出请求了 rsp = request.urlopen(req)#,headers=headers
三、源码
Reptile3_PostAnlysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile3_PostAnlysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料


