

一、re举例
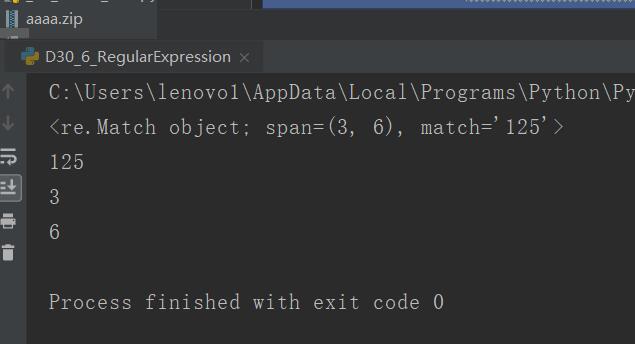
import re #查找数字 p = re.compile(r"\d+") #在字符串“ongahjeuf125”中及逆行查找,按照规则p指定的正则进行查找 m = p.match("ong125fdsgdsf48515",3,20)#后面的参数序号3到6的搜索范围 print(m) #上述代码说明 #1.match可以输入参数表示起始位置 #2.查找到的结果只包含一个,表示第一次进行匹配成功的内容 print(m[0])#直接打印出了匹配的内容 print(m.start(0))#打印匹配内容从哪里开始的 print(m.end(0))#打印匹配内容从哪里结束的
2.再举个例子:可以分组获取内容
#参数中re.I代表忽略大小写 p1 = re.compile(r"([a-z]+) ([a-z]+)",re.I) m1 = p1.match("I am relly good man") print(m1) print(m1.group(0)) print(m1.start(0)) print(m1.end(0)) print("===================") print(m1.group(1)) print(m1.start(1)) print(m1.end(1)) print("===================") print(m1.group(2)) print(m1.start(2)) print(m1.end(2)) print("===================") print(m1.groups())

3.查找
(1)search(str,pos[,endpox]]):在字符串中查找匹配,pos和endpos表示起始位置
(2)findall:查找所有
(3)finditer:查找,返回一个iter结果
4.替换
sub(rep1,str[,count])
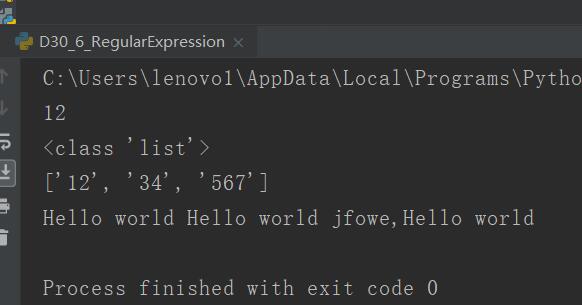
p2 = re.compile(r"\d+") m2 = p2.search("one12two34three567four") print(m2.group()) m3 = p2.findall("one12two34three567four") print(type(m3)) print(m3) p3 = re.compile(r"(\w+) (\w+)") s = "hello 123 wang 456 jfowe,i jodf " ret = p3.sub(r"Hello world",s) print(ret)
5.注意
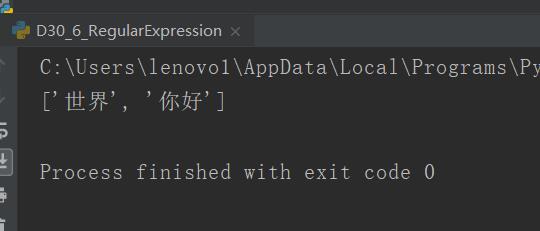
大部分中文内容表示范围是[u4e00-u9fa5],不包括全角标点
title = "世界 你好,hello moto" p4 = re.compile(r"[\u4e00-\u9fa5]+") rst = p4.findall(title) print(rst)
二、源码
D31_1_RexLearning.py
https://github.com/ruigege66/Python_learning/blob/master/D31_1_RexLearning.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料


