后缀数组、后缀自动机学习笔记
后缀数组、后缀自动机学习笔记
后缀数组(SA)
前置知识
倍增、计数排序、基数排序。
后缀数组定义
我们约定字符串 \(s\) 的后缀 \(i\) 指 \(s_{i\dots n}\)。
后缀数组(Suffix Array)主要是两个数组 \(sa\) 和 \(rk\),\({sa}_i\) 表示后缀排序后第 \(i\) 小的后缀编号,\({rk}_i\) 表示后缀 \(i\) 的排名。
显然,\({sa}_{{rk}_i}={rk}_{{sa}_i}=i\)。
例如对字符串 \(\texttt{aabaaaab}\) 的后缀排序如下:
\(\mathcal{O}(n^2\log n)\) 求法
这个求法不用我讲吧,直接对着 string 搞 sort,比较字符串是 \(\mathcal{O}(n)\) 的,所以排序是 \(\mathcal{O}(n^2\log{n})\) 的。
\(\mathcal{O}(n\log^2 n)\) 求法
字符串哈希预处理,然后二分求最长公共前缀。
\(\mathcal{O}(n\log^2 n)\) 求法
我们把 \(s_{n+1\dots\infty}\) 全部填充为 \(-\infty\)。
这个做法需要倍增的思想。
设 \({rk}_{w,i}\) 表示 \(s_{i\dots i+w-1}\) 在 \(\{s_{x\dots x+w-i}\mid x\in[1,n]\}\) 的排名,对于 \(i>n\) 我们认为 \({rk}_{w,i}=-\infty\)。
我们可以首先对每个字符进行排序得到 \({rk}_{1,i}\),然后考虑怎么利用 \({rk}_{w,i}\) 求出 \({rk}_{2w,i}\)。只要以 \({rk}_{w,i}\) 为第一关键字,以 \({rk}_{w,i+w}\) 为第二关键字排序,就可以求出 \({rk}_{2w,i}\)。
至于为什么?\({rk}_{w,i}\) 包含了 \(s_{i\dots i+w-1}\) 的信息,\({rk}_{w,i+w}\) 包含了 \(s_{i+w\dots i+2w-1}\) 的信息,类似于 ST 表,把它们合并起来就是 \(s_{i\dots i+2w-1}\) 的信息。
如果用 sort 进行排序,时间复杂度为 \(\mathcal{O}(n\log^2 n)\)。
\(\mathcal{O}(n\log n)\) 做法
既然说“如果用 sort 进行排序”,说明可以不用 sort 进行排序,能够做到更优,省掉一只 \(\log\)。
这时候就需要用到前置知识——计数排序、基数排序了。
需要排序的数组是排名,值域显然为 \([1,n]\),且只有两个关键字,基数排序只需要排序两次,排序的时间复杂度优化为 \(\mathcal{O}(n)\)。
\(\mathcal{O}(n\log n)\) 做法的一些常数优化
(一)如果排名已经互不相同,就没必要继续排序了。例如上表中的 \({rk}_{4,i}\)。
(二)排名数组的值域可能不到 \([1,n]\),可以记一下具体的值域,计数排序时少循环一些。例如上表中的 \({rk}_{1,i}\) 和 \({rk}_{2,i}\)。
(三)减少不连续内存访问。然而这个我不会。
放一份用了常数优化(一)(二)的代码:
//By: Luogu@rui_er(122461)
#include <bits/stdc++.h>
#define rep(x,y,z) for(int x=y;x<=z;x++)
#define per(x,y,z) for(int x=y;x>=z;x--)
#define debug printf("Running %s on line %d...\n",__FUNCTION__,__LINE__)
#define fileIO(s) do{freopen(s".in","r",stdin);freopen(s".out","w",stdout);}while(false)
using namespace std;
typedef long long ll;
const int N = 1e6+5;
char s[N];
int n, sa[N], rk[N], lst[N<<1], id[N], cnt[N];
template<typename T> void chkmin(T& x, T y) {if(x > y) x = y;}
template<typename T> void chkmax(T& x, T y) {if(x < y) x = y;}
int main() {
scanf("%s", s+1);
n = strlen(s+1);
int m = 300; // 值域
rep(i, 1, n) ++cnt[rk[i] = s[i]]; // 计数排序基本操作,统计每个数出现次数
rep(i, 1, m) cnt[i] += cnt[i-1]; // 计数排序基本操作,用前缀和求出每个值的排名
per(i, n, 1) sa[cnt[rk[i]]--] = i; // 计数排序基本操作,利用每个值的排名从右往左算每个数排名并赋值,计数排序不熟的话建议手玩一下
for(int w=1,p=0;;w<<=1,m=p) {
// 基数排序按关键字从不重要到重要排序
// 下面三行是对第二关键字的排序,sa[i] 是 i 的第一关键字,id[i] 表示第二关键字排名为 i 的数,第一关键字的位置
p = 0;
per(i, n, n-w+1) id[++p] = i; // 把最后 w 个第二关键字是无穷小的放进来
rep(i, 1, n) if(sa[i] > w) id[++p] = sa[i] - w; // 找第二关键字,如果 sa[i] > w 就可以作为别人的第二关键字,那就把第一关键字的坐标添加进 id 里
// 上面进行了常数优化(二),因为第二关键字的排序不需要使用计数排序
// 下面四行是对第一关键字的排序,使用计数排序,与上面计数排序基本相同,不再解释
memset(cnt, 0, sizeof(cnt));
rep(i, 1, n) ++cnt[rk[id[i]]];
rep(i, 1, m) cnt[i] += cnt[i-1];
per(i, n, 1) sa[cnt[rk[id[i]]]--] = id[i];
memcpy(lst, rk, sizeof(rk)); // 备份一下排名数组,因为下面要修改
p = 0;
rep(i, 1, n) { // 求出每个位置新的排名
if(lst[sa[i]] == lst[sa[i-1]] && lst[sa[i]+w] == lst[sa[i-1]+w]) rk[sa[i]] = p; // 如果与前一名两个关键字都相等,那么它们并列
else rk[sa[i]] = ++p; // 否则排在前一名的后面,即把名次加一
}
if(p == n) { // 常数优化(一),即顺序已经确定不需要继续排序
rep(i, 1, n) sa[rk[i]] = i;
break;
}
}
rep(i, 1, n) printf("%d%c", sa[i], " \n"[i==n]);
return 0;
}
代码加了不少注释,这是无注释代码:
//By: Luogu@rui_er(122461)
#include <bits/stdc++.h>
#define rep(x,y,z) for(int x=y;x<=z;x++)
#define per(x,y,z) for(int x=y;x>=z;x--)
#define debug printf("Running %s on line %d...\n",__FUNCTION__,__LINE__)
#define fileIO(s) do{freopen(s".in","r",stdin);freopen(s".out","w",stdout);}while(false)
using namespace std;
typedef long long ll;
const int N = 1e6+5;
char s[N];
int n, sa[N], rk[N], lst[N<<1], id[N], cnt[N];
template<typename T> void chkmin(T& x, T y) {if(x > y) x = y;}
template<typename T> void chkmax(T& x, T y) {if(x < y) x = y;}
int main() {
scanf("%s", s+1);
n = strlen(s+1);
int m = 300;
rep(i, 1, n) ++cnt[rk[i] = s[i]];
rep(i, 1, m) cnt[i] += cnt[i-1];
per(i, n, 1) sa[cnt[rk[i]]--] = i;
for(int w=1,p=0;;w<<=1,m=p) {
p = 0;
per(i, n, n-w+1) id[++p] = i;
rep(i, 1, n) if(sa[i] > w) id[++p] = sa[i] - w;
memset(cnt, 0, sizeof(cnt));
rep(i, 1, n) ++cnt[rk[id[i]]];
rep(i, 1, m) cnt[i] += cnt[i-1];
per(i, n, 1) sa[cnt[rk[id[i]]]--] = id[i];
memcpy(lst, rk, sizeof(rk));
p = 0;
rep(i, 1, n) {
if(lst[sa[i]] == lst[sa[i-1]] && lst[sa[i]+w] == lst[sa[i-1]+w]) rk[sa[i]] = p;
else rk[sa[i]] = ++p;
}
if(p == n) {
rep(i, 1, n) sa[rk[i]] = i;
break;
}
}
rep(i, 1, n) printf("%d%c", sa[i], " \n"[i==n]);
return 0;
}
UPD 新的写法(感觉这个更好记):
//By: Luogu@rui_er(122461)
#include <bits/stdc++.h>
#define rep(x,y,z) for(int x=y;x<=z;x++)
#define per(x,y,z) for(int x=y;x>=z;x--)
#define debug printf("Running %s on line %d...\n",__FUNCTION__,__LINE__)
#define fileIO(s) do{freopen(s".in","r",stdin);freopen(s".out","w",stdout);}while(false)
using namespace std;
typedef long long ll;
const int N = 2e6+5;
int n, rk[N], sa[N], cnt[N], id[N];
char s[N];
template<typename T> void chkmin(T& x, T y) {if(x > y) x = y;}
template<typename T> void chkmax(T& x, T y) {if(x < y) x = y;}
int main() {
scanf("%s", s+1);
n = strlen(s+1);
rep(i, 1, n) {
sa[i] = i;
rk[i] = s[i];
}
int m = max(n, 300), p = 0;
for(int w=1;;w<<=1,m=p) {
// sort key 2
memset(cnt, 0, sizeof(cnt));
memcpy(id, sa, sizeof(sa));
rep(i, 1, n) ++cnt[rk[id[i]+w]];
rep(i, 1, m) cnt[i] += cnt[i-1];
per(i, n, 1) sa[cnt[rk[id[i]+w]]--] = id[i];
// sort key 1
memset(cnt, 0, sizeof(cnt));
memcpy(id, sa, sizeof(sa));
rep(i, 1, n) ++cnt[rk[id[i]]];
rep(i, 1, m) cnt[i] += cnt[i-1];
per(i, n, 1) sa[cnt[rk[id[i]]]--] = id[i];
// update rk
p = 0;
memcpy(id, rk, sizeof(rk));
rep(i, 1, n) {
if(id[sa[i]] == id[sa[i-1]] && id[sa[i]+w] == id[sa[i-1]+w]) rk[sa[i]] = p;
else rk[sa[i]] = ++p;
}
if(p == n) break;
}
rep(i, 1, n) printf("%d%c", sa[i], " \n"[i==n]);
return 0;
}
\(\mathcal{O}(n)\) 做法
然而一般来讲时间复杂度瓶颈不在后缀排序,而且这两个太毒瘤了,所以不想学。
height 数组
最长公共前缀(LCP)
两个字符串 \(s,t\) 的 LCP 为最大的满足 \(\forall i\in[1,x],s_i=t_i\) 的 \(x\),显然 \(x\in[0,\min(|s|,|t|)]\)。
height 数组定义
对于字符串 \(s\),我们称 \(s_{i\dots n}\) 为“后缀 \(i\)”,记 \(lcp(i,j)\) 表示后缀 \(i\) 和后缀 \(j\) 的 LCP,则定义 height 数组满足 \({height}_i=lcp({sa}_{i-1},{sa}_i)\)。特别地,\({height}_1=0\)。
\(\mathcal{O}(n)\) 求 height 数组
引理一:\(lcp(i,j)=\min\{{height}_k\mid {rk}_i < k\le {rk}_j\}\ ({rk}_i < {rk}_j)\)。
感性理解,因为按字典序排列,所以排的越远相似度(LCP)越低。
严格证明可以参考论文。
引理二:\({height}_{{rk}_i}\ge {height}_{{rk}_{i-1}}-1\)。
证明:设 \(h_i={height}_{{rk}_i}\),即后缀 \(i\) 和排在它前一名的后缀的 LCP,原式化为 \(h_i\ge h_{i-1}-1\)。
设 \({sa}_{{rk}_{i-1}-1}=k\),即排在后缀 \(i-1\) 前一名的是后缀 \(k\)。
如果 \(h_{i-1}\le 1\),显然成立。
如果 \(h_{i-1} > 1\),因为后缀 \(k\) 和后缀 \(i-1\) 的 LCP 大于一,所以第一个字符对字符串大小的比较没有影响,得到后缀 \(k+1\) 排在后缀 \(i\) 前面,且 \(lcp(k+1,i)=h_{i-1}-1\)。根据引理一 \(h_i\ge h_{i-1}-1\) 成立。
综上,\({height}_{{rk}_i}\ge {height}_{{rk}_{i-1}}-1\)。
说了这么多,是时候来讲讲 \(\mathcal{O}(n)\) 求 height 数组的算法了,这个算法就是——暴力。复杂度?根据引理二显然。
代码:
rep(i, 1, n) {
int j = height[rk[i-1]];
if(j) --j;
while(a[i+j] == a[sa[rk[i]-1]+j]) ++j;
height[rk[i]] = j;
}
SA 和 height 数组练习题
P3809 【模板】后缀排序、P6456 [COCI2006-2007#5] DVAPUT、P4051 [JSOI2007]字符加密等。
然后 OI Wiki 有不少题。
后缀自动机(SAM)
前置知识
等价类。
zpl 要求我解释解释,那我试试吧。
我们定义一个集合 \(S\) 上的等价关系 \(\sim\),对于一个元素 \(a\in S\),所有满足 \(b\in S\) 且 \(a\sim b\) 的元素 \(b\) 都在 \(a\) 的等价类中。
举几个例子:
- \(S\) 是北京市常住人口的集合,定义等价关系 \(\sim\) 为住在同一个区,则所有住在海淀区的人在同一个等价类中,但住在海淀区的人和住在朝阳区的人不在同一个等价类中。
- \(S\) 是整数集合 \(\Z\),定义等价关系 \(\sim\) 为模 \(2\) 余数相等,则所有奇数在同一个等价类中,所有偶数在同一个等价类中。
- \(S\) 是分数集合 \(\Z\times(\Z\setminus\{0\})\)(也就是有理数集合 \(\Q\) 的分数形式),定义等价关系 \((a,b)\sim(c,d)\) 为 \(ad=bc\),则所有满足 \(\frac{a}{b}=\frac{c}{d}\) 的分数在同一个等价类中。
定义
下文记 \(\Sigma\) 为字符集。
后缀自动机(Suffix Automaton)是一个字符串所有子串的压缩形式,能解决许多字符串相关问题。
字符串 \(s\) 的 SAM 是接受 \(s\) 所有后缀的最小 DFA(确定性有限状态自动机)。
如果你不知道自动机是啥(看不懂上面那句话),那么可以看下面的解释:
- SAM 是一个 DAG,节点称为状态,边称为转移。
- 图存在源点 \(t_0\),称为初始状态,从 \(t_0\) 出发可以到达所有节点。
- 有若干个终止状态,满足从 \(t_0\) 出发,经过若干条边走到一个终止状态,则路径上所有转移的字母连起来是 \(s\) 的后缀,\(s\) 的后缀也都可以用这样一条路径表示。
- SAM 是满足前三条性质的节点数最少的自动机。
SAM 包含一个字符串所有子串的信息,任意一条从 \(t_0\) 开始的路径,把转移的字母连起来,都会得到一个 \(s\) 的子串,每个 \(s\) 的子串也可以用这样一条路径表示。我们称这种子串和路径的关系为“对应”,下文可能出现路径对应了子串,或者子串对应了路径,就是这个意思。SAM 中到达一个状态的路径可能不止一条,我们称这个状态对应可以到达它的字符串的集合,这个集合的每个元素对应一条到达这个状态的路径。
我们举个简单的例子,对于字符串 \(\texttt{abbb}\) 建出的 SAM 如下:
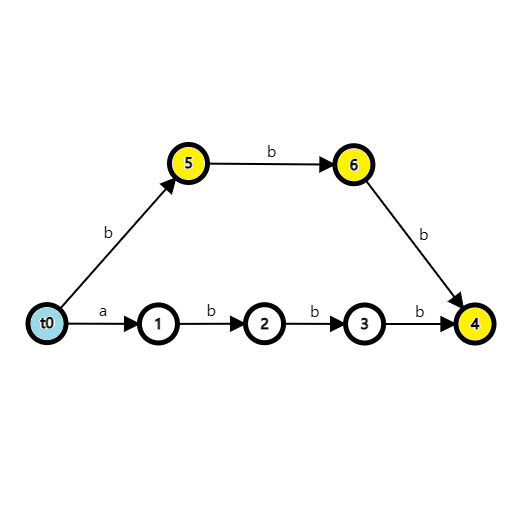
根据上面的定义,我们可以说路径 \(t_0\stackrel{\texttt{a}}{\to}1\stackrel{\texttt{b}}{\to}2\stackrel{\texttt{b}}{\to}3\) 对应了子串 \(\texttt{abb}\)。在这个 SAM 中,有两条从 \(t_0\) 到 \(4\) 的路径,也就是说状态 \(4\) 对应了字符串集合 \(\{\texttt{abbb},\texttt{bbb}\}\)。但为什么可以这么对应,这两个字符串有什么共同点呢?我们继续往下讲。
结束位置 \(\textrm{endpos}\)
对于字符串 \(s\) 的所有非空子串 \(t\),我们记 \(\textrm{endpos}(t)\) 为在 \(s\) 中 \(t\) 的所有结束位置。例如对于字符串 \(\texttt{abcbc}\),有 \(\textrm{endpos}(\texttt{bc})=\{3,5\}\)。
我们定义集合 \(S\) 为字符串 \(s\) 所有非空子串的集合,定义等价关系 \(\sim\) 为 \(\textrm{endpos}\) 相等,这样字符串 \(s\) 的所有非空子串都可以根据 \(\textrm{endpos}\) 划分为若干等价类。
则 SAM 的每个状态都对应了一个等价类,也就是一个或多个 \(\textrm{endpos}\) 相同的子串。在上面那个例子里,\(\texttt{abbb}\) 和 \(\texttt{bbb}\) 的 \(\textrm{endpos}\) 均为 \(4\)。
根据上面的定义,我们有一些引理:
引理一:字符串 \(s\) 的两个非空子串 \(u,v\) 满足 \(|u|\le |v|\) 且 \(\textrm{endpos}(u)=\textrm{endpos}(v)\),当且仅当 \(u\) 在 \(s\) 中所有出现位置都是 \(v\) 的后缀。
显然成立。
引理二:字符串 \(s\) 的两个非空子串 \(u,v\) 满足 \(|u|\le |v|\),则满足:
\[\begin{cases}\textrm{endpos}(u)\cap\textrm{endpos}(v)=\varnothing,&u\textrm{ is not a suffix of } v\\ \textrm{endpos}(v)\subseteq\textrm{endpos}(u),&\textrm{otherwise}\end{cases} \]
证明:若 \(\textrm{endpos}(u)\cap\textrm{endpos}(v)\ne\varnothing\),则 \(u,v\) 至少一次同时出现,类似于引理一可知 \(u\) 是 \(v\) 后缀,则 \(v\) 每一次出现 \(u\) 都会出现,即 \(\textrm{endpos}(v)\subseteq\textrm{endpos}(u)\)。
引理三:对于一个 \(\textrm{endpos}\) 等价类,不存在两个等长子串;且把属于这一等价类的所有子串按长度递增顺序排序,则前一个子串是后一个子串的后缀,这些子串的长度覆盖一个整数区间 \([x,y]\cap\Z\)。
证明:若等价类中只有一个元素,显然成立。
否则,由引理一,较短子串总是较长子串的真后缀,等价类中没有等长的子串。
记等价类中最长、最短的子串为 \(u,v\),则 \(x=|v|,y=|u|\)。考虑长度在 \([x,y]\) 间的 \(u\) 的后缀 \(w\),由引理一知 \(v\) 是 \(u\) 的后缀,则 \(v\) 是 \(w\) 的一个后缀。由引理二知 \(\textrm{endpos}(v)\subseteq\textrm{endpos}(w)\subseteq\textrm{endpos}(u)\),又因为 \(\textrm{endpos}(u)=\textrm{endpos}(v)\),所以 \(\textrm{endpos}(w)=\textrm{endpos}(u)\),\(w\) 也在这个等价类中。所有长度在 \([x,y]\) 间的 \(u\) 的后缀都在这个等价类中,因此这些子串的长度覆盖整数区间 \([x,y]\cap\Z\)。
后缀链接 \(\textrm{link}\)
对于 SAM 中一个不是 \(t_0\) 的状态 \(v\),假设 \(w\) 是状态 \(v\) 这个等价类中最长的字符串,则根据引理三,其他字符串都是 \(w\) 的后缀。同样根据引理三,我们还知道把 \(w\) 的所有后缀按长度降序排序,则前几个后缀一定在等价类 \(v\) 中,且至少有一个后缀(可以是空串 \(\varnothing\))在其他等价类中。我们记 \(t\) 为在其他等价类中的 \(w\) 的最长后缀,则后缀链接 \(\textrm{link}(v)\) 连接到 \(t\) 所在的等价类。
我们假设空串 \(\varnothing\) 包含于状态 \(t_0\) 中,为了方便我们令 \(\textrm{endpos}(t_0)=\{0,1,\cdots,|s|\}\)。
引理四:所有后缀链接构成一棵根节点为 \(t_0\) 的内向树。
证明:对于任意不是 \(t_0\) 的状态 \(v\),根据后缀链接的定义和引理三,沿后缀链接移动都会到达严格更短的字符串,因此一直沿后缀链接移动总能到达空串 \(\varnothing\) 对应的状态 \(t_0\)。
引理五:以 \(\textrm{endpos}\) 集合的包含关系作为父子关系构建出的树,与后缀链接构建出的树完全相同。
证明:由引理二,我们可以用 \(\textrm{endpos}\) 集合构建出一棵树。
对于不是 \(t_0\) 的状态 \(v\),由后缀链接和引理二可知 \(\textrm{endpos}(v)\subsetneq\textrm{endpos}(\textrm{link}(v))\)。这里是 \(\subsetneq\) 不是 \(\subseteq\),因为如果 \(\textrm{endpos}(v)=\textrm{endpos}(\textrm{link}(v))\),则他们在同一个等价类中,应当被合并为同一个节点。
结合前面的引理,可知后缀链接构建出的树就是 \(\textrm{endpos}\) 构建出的树。
例如,下面是 \(\texttt{abcbc}\) 的 SAM,红色边就是后缀链接:
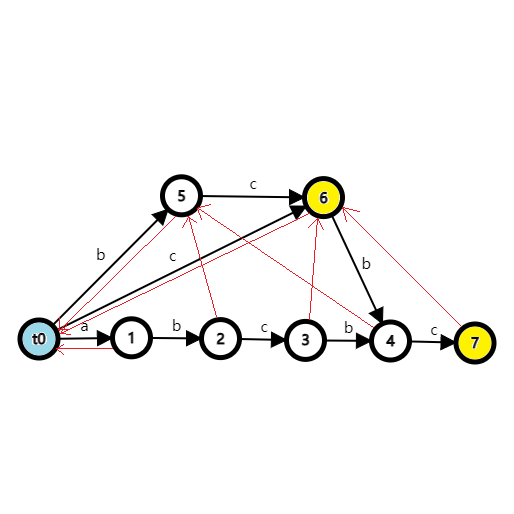
状态 \(7\) 的最长串为 \(\texttt{abcbc}\),但是 \(\texttt{bcbc}\) 和 \(\texttt{cbc}\) 的 endpos 也为 \(\{5\}\),属于同一个等价类,后缀链接指向 \(\texttt{bc}\) 对应的状态 \(6\)。
小结&记号引入
我们已经知道了:
- \(s\) 的子串可以根据 \(\textrm{endpos}\) 的不同分为若干等价类。
- SAM 中的状态包括初始状态 \(t_0\)(对应空串 \(\varnothing\))和每个 \(\textrm{endpos}\) 等价类对应的状态。
- 对于每个状态 \(v\),有若干个子串与它匹配。我们记 \(\textrm{longest}(v)\) 为等价类中最长的字符串,\(\textrm{maxlen}(v)=|\textrm{longest}(v)|\);记 \(\textrm{shortest}(v)\) 为等价类中最短的字符串,\(\textrm{minlen}(v)=|\textrm{shortest}(v)|\)。那么状态 \(v\) 对应的所有字符串都是 \(\textrm{longest}(v)\) 的后缀,且长度覆盖了整数区间 \([\textrm{minlen}(v),\textrm{maxlen}(v)]\cap\Z\)。
- 对任意不是 \(t_0\) 的状态 \(v\),后缀链接 \(\textrm{link}(v)\) 连接到字符串 \(\textrm{longest}(v)\) 的长度为 \(\textrm{minlen}(v)-1\) 的后缀对应的状态,即 \(\textrm{minlen}(v)=\textrm{maxlen}(\textrm{link}(v))+1\)。所有后缀链接构成了根节点为 \(t_0\) 的一棵内向树,这棵树也表示 \(\textrm{endpos}\) 的包含关系。
- 从任意状态 \(v_0\) 开始沿后缀链接遍历,总会到达初始状态 \(t_0\),路径上所有状态 \(v_i\) 的整数区间 \([\textrm{minlen}(v_i),\textrm{maxlen}(v_i)]\cap\Z\) 的交集为 \(\varnothing\),并集为 \([0,\textrm{maxlen}(v_0)]\cap\Z\)。
SAM 的构建
SAM 的构建的复杂度为 \(\mathcal{O}(|s|)\)。与 ACAM 的构建不同的是,这个算法是在线算法,可以每次在串尾(只有一个串)插入一个字符;而 ACAM 是离线算法,必须插入所有字符串后进行处理。
为了保证复杂度为线性,我们只会维护 \(\textrm{maxlen}\) 和 \(\textrm{link}\) 的值和每个状态的转移,而不会(也不能)动态维护终止标记(即接受状态)。但是如果需要的话,我们可以在全部插完后标记出终止节点。以下将 \(\textrm{maxlen}\) 简写为 \(\textrm{len}\)。
SAM 的初始化 init() 非常简单,只需要 \(\textrm{len}(t_0)\gets 0\) 并 \(\textrm{link}(t_0)\gets -1\)。我们用 \(0\) 号点表示状态 \(t_0\),\(-1\) 号点是虚拟出的不合法的状态。
下面考虑 SAM 的插入字符 extend(c) 操作。
在前面举的 SAM 的例子中,你可能会注意到两类节点:一些在最底下排成一条链(可能有不规则的连边),还有一些在上面连得乱七八糟。这个直觉是有道理的,我们会在下面讲解这两种点是怎么产生的。我们暂且称他们为“地上的点”和“天上的点”。
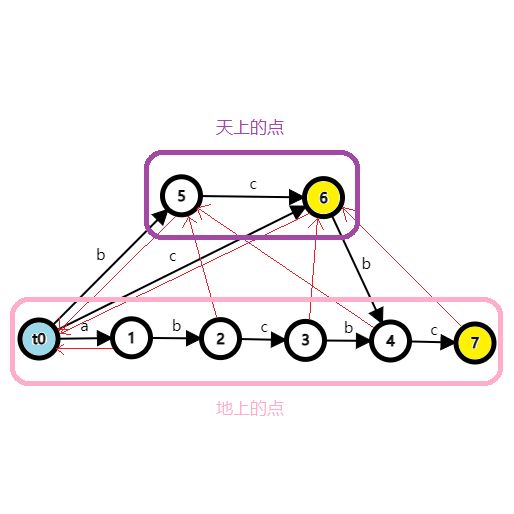
我们记录 \(lst\) 表示“地上的点”中最靠右的点,显然初始 \(lst=0\)。然后进行以下步骤:
- 创建一个新的状态 \(u\),令 \(\textrm{len}(u)\gets\textrm{len}(lst)+1\),此时 \(\textrm{link}(u)\) 尚未知。
- 从状态 \(lst\) 开始遍历后缀链接,如果还没有字符 \(c\) 的转移,就添加一个到 \(u\) 的字符 \(c\) 的转移。如果已经有了字符 \(c\) 的转移,就停下来不再遍历,记这个状态为 \(p\)。
- 如果没有找到这样的状态,即遍历到了虚拟状态 \(-1\),我们就令 \(\textrm{link}(u)\gets 0\) 并退出。
- 否则,我们记 \(p\stackrel{c}{\to}q\) 的节点为 \(q\)(请注意 \(\to\) 上面字母的格式,若为 \(\texttt{texttt}\) 形式则代表是这个字母,若为 \(default\) 形式则代表是一个变量),进行分类讨论:
- 如果 \(\textrm{len}(p)+1=\textrm{len}(q)\),我们令 \(\textrm{link}(u)\gets q\) 并退出。
- 否则就有点复杂,我们需要复制状态 \(q\) 的后缀链接和转移(不复制 \(\textrm{len}\)),得到一个新的状态 \(v\)。我们令 \(\textrm{len}(v)\gets\textrm{len}(p)+1\),然后我们令 \(\textrm{link}(u)\gets v\) 且 \(\textrm{link}(q)\gets v\)。最后我们从 \(p\) 开始遍历后缀链接,如果存在 \(p_i\stackrel{c}{\to}q\),就把这个转移重定向成 \(p_i\stackrel{c}{\to}v\)。
- 以上所有的情况过后,我们都将 \(lst\gets u\)。
这些步骤感觉很乱啊,下面我们来讲一下每一步的意义。对 \(p\stackrel{c}{\to}q\) 的转移,如果满足 \(\textrm{len}(p)+1=\textrm{len}(q)\),则称这是连续转移,否则称这是不连续转移。
- 没啥好说的,插了个字符,整个字符串长度增加了,显然要创建节点。这个节点是地上的点。
- 多了一个字符,我们要把所有新的后缀(即新的子串)添加进 SAM 里面。遍历后缀链接就是遍历所有的原来的后缀,添加转移就是在原来的后缀接一个新的字符。
- 如果所有的新后缀都没出现过,都加完了,就做完了,改一下后缀链接就行。
- 否则这个后缀之前出现过,那么原来的 \(\textrm{endpos}\) 会发生变化,可能需要重构 SAM 结构,就是下面的两个小情况。
- 如果这个转移是连续的,这种情况比较简单,只需要连一下后缀链接,因为 \(\textrm{endpos}\) 会同步变化。
- 如果转移不连续,假设原来的字符串是 \(s\),那么新字符串就是 \(s+c\),找到了最长的 \(s\) 的后缀 \(x\) 使得 \(x+c\) 在 \(s\) 中出现过,此时的 \(\textrm{len}\) 值应当等于 \(\textrm{len}(p)+1\),但实际上并不等于,不存在这样的状态。因此我们创建了状态 \(v\),本质上其实是把原来的状态 \(q\) 拆成了两个,因为添加了字符 \(c\) 后导致原来的一个 \(\textrm{endpos}\) 等价类被拆成了两个。这个节点是天上的点。
- 把 \(lst\) 更新成新的地上的点 \(u\),注意 \(v\) 是天上的点不能更新。
容易发现,\(s\) 的每一个前缀都对应了一个地上的点,并且是这个地上的点的 \(\textrm{longest}\)。
我们只需要把 \(s\) 的每一个字符按顺序插入 SAM 就做完了。
如果需要知道终止节点(接受状态)是哪些,怎么办呢?根据定义,所有后缀对应接受状态。我们只需要把所有后缀对应的状态标为接受即可。显然 \(\textrm{longest}(lst)=s\) 是最长的后缀(就是原串),根据后缀链接的定义,我们从 \(lst\) 遍历后缀链接,把经过的状态标为接受状态即可。
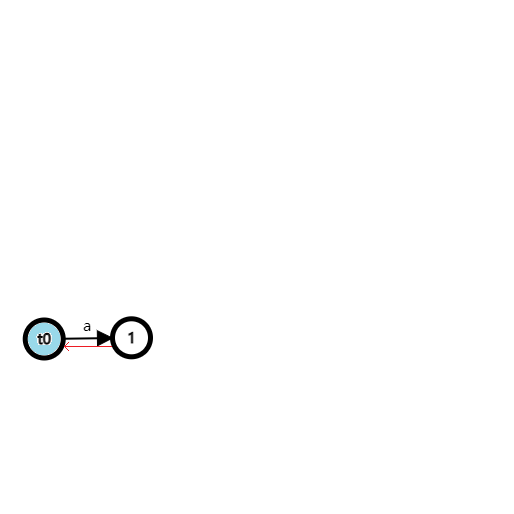
说了这么多,我们来演示一下字符串 \(\texttt{abcbc}\) 的 SAM 的构建,可以对着上面的步骤手玩一下。
首先初始化 SAM:

插入 \(\texttt{a}\):
插入 \(\texttt{b}\):
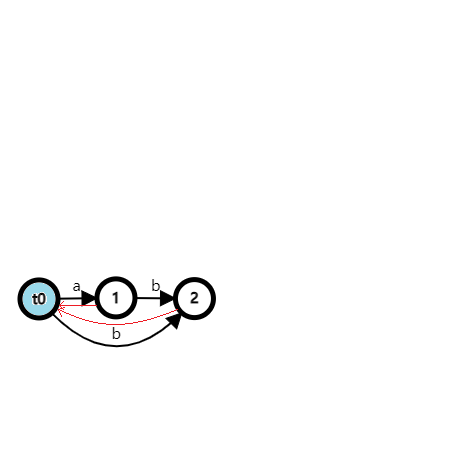
插入 \(\texttt{c}\):
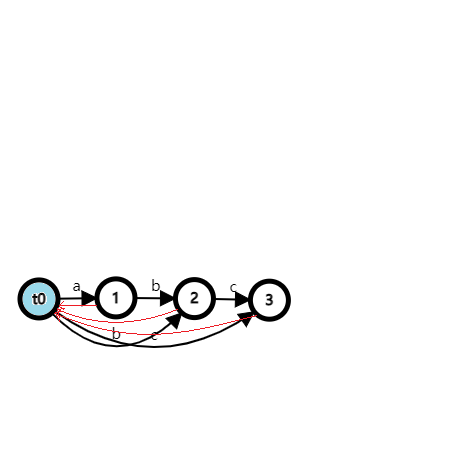
插入 \(\texttt{b}\),注意这时候出现了一个天上的点,SAM 的结构有些变化:
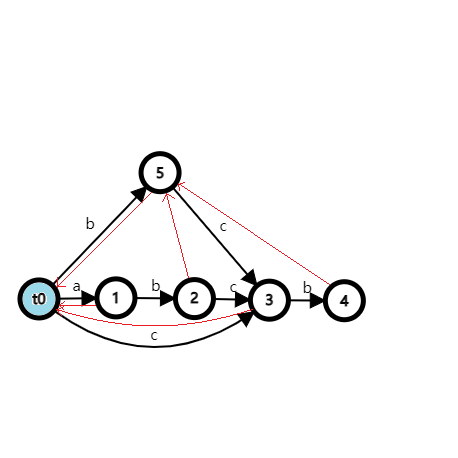
插入 \(\texttt{c}\),注意这时候又出现了一个天上的点,SAM 的结构有些变化:(这里 \(6,7\) 两个点的编号标反了,但问题不大就懒得改了)
SAM 的状态数和转移数
我们假设字符集大小为常数 \(|\Sigma|\),插入一个长度为 \(n\) 的字符串 \(s\)。
根据上面的步骤,SAM 每次插入最多增加两个状态,显然状态数不超过 \(2n-1\),可以在 \(s=\texttt{abbb}\cdots\texttt{bbb}\) 取到。
假设 \(n\ge 3\),转移数不会超过 \(3n-4\)。
证明:首先估计连续转移数量。考虑 \(t_0\) 开始的最长路径的生成树,生成树只包含连续边,连续转移数不超过状态数,最大为 \(2n-2\)。
然后估计不连续转移数量。设不连续转移为 \(p\stackrel{c}{\to}q\),它对应的字符串为 \(u+c+w\),其中 \(u\) 对应 \(t_0\) 到 \(p\) 的最长路径,\(w\) 对应 \(q\) 到任意接受状态的最长路径。一方面,因为 \(u,w\) 仅由完整的转移构成,所以每一个不完整的字符串对应的 \(u+c+w\) 不同;另一方面,由接受状态定义,\(u+c+w\) 为 \(s\) 的后缀,而 \(s\) 只有 \(n\) 个非空后缀,且 \(s\) 本身一定对应 \(n\) 个连续转移,因此不连续转移不超过 \(n-1\) 个。
上面两部分相加得到上界 \(3n-3\),然而状态数最多只在 \(s=\texttt{abbb}\cdots\texttt{bbb}\) 取到,此时转移数量少于 \(3n-3\),因此转移数上界为 \(3n-4\),可以在 \(s=\texttt{abbb}\cdots\texttt{bbbc}\) 取到。
SAM 的两种实现和复杂度证明
两种实现其实没啥差别,就是存转移的时候是用平衡树(map)来存还是用一个大小为 \(|\Sigma|\) 的数组来存。前者的时间复杂度为 \(\mathcal{O}(n\log|\Sigma|)\),空间复杂度为 \(\mathcal{O}(n)\);后者的时间复杂度为 \(\mathcal{O}(n)\),空间复杂度为 \(\mathcal{O}(n|\Sigma|)\)。我个人认为后者更简单易懂,但有时字符集达到了 \(10^9\) 量级必须用前者。
我们将认为字符集大小为常数,也就是搜索转移、添加转移、查找下一个转移的复杂度均为 \(\mathcal{O}(1)\)。
考虑算法的过程,有三处的时间复杂度不明显为线性:
- 遍历 \(lst\) 的后缀链接,添加字符 \(c\)。
- 复制状态 \(q\to v\)。
- 修改指向 \(q\) 的转移,重定向到 \(v\)。
我们已经证明了 SAM 的状态数和转移数均为 \(\mathcal{O}(n)\),易知前面两处总复杂度显然为线性,下面估计第三处的复杂度。
我们将指向 \(q\) 的转移重定向到 \(v\),记 \(w=\textrm{longest}(p)\),\(w\) 是 \(s\) 的后缀,每次迭代长度递减。在迭代前如果 \(w\) 在后缀链接树中距离 \(lst\) 深度为 \(k\ (k\ge 2)\),则最后一次迭代后 \(w+c\) 会成为路径上第二个从 \(u\) 出发的后缀链接,它将成为新的 \(lst\)。
循环中每次迭代都会使作为当前字符串后缀的字符串 \(\textrm{longest}(\textrm{link}(\textrm{link}(lst)))\) 的位置单调递增,循环最多执行不超过 \(n\) 次迭代。
第二种实现的代码:
struct State {
int len, link, nxt[26];
};
struct SAM {
State st[N<<2];
int sz, lst;
void init() {
st[0].len = 0;
st[0].link = -1;
sz = lst = 0;
}
void extend(char ch) {
int u = ++sz, c = ch - 'a';
st[u].len = st[lst].len + 1;
int p = lst;
for(;p!=-1&&!st[p].nxt[c];p=st[p].link) st[p].nxt[c] = u;
if(p == -1) st[u].link = 0;
else {
int q = st[p].nxt[c];
if(st[p].len + 1 == st[q].len) st[u].link = q;
else {
int v = ++sz;
st[v].len = st[p].len + 1;
st[v].link = st[q].link;
memcpy(st[v].nxt, st[q].nxt, sizeof(st[q].nxt));
for(;p!=-1&&st[p].nxt[c]==q;p=st[p].link) st[p].nxt[c] = v;
st[q].link = st[u].link = v;
}
}
lst = u;
}
}sam;
SAM 练习题。
从洛谷找了份题单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号