

Neural Network Basics: Convolution Kernel
these are all from DSP for image processing.
A kernel is a small matrix than the original image that can apply the desired effect to the image, and in machine learning, this is used to extract the features (i.e. convolution). each kernel is designed for a specific function, for example, edge detection, etc.
-
3x3 Convolution Kernel

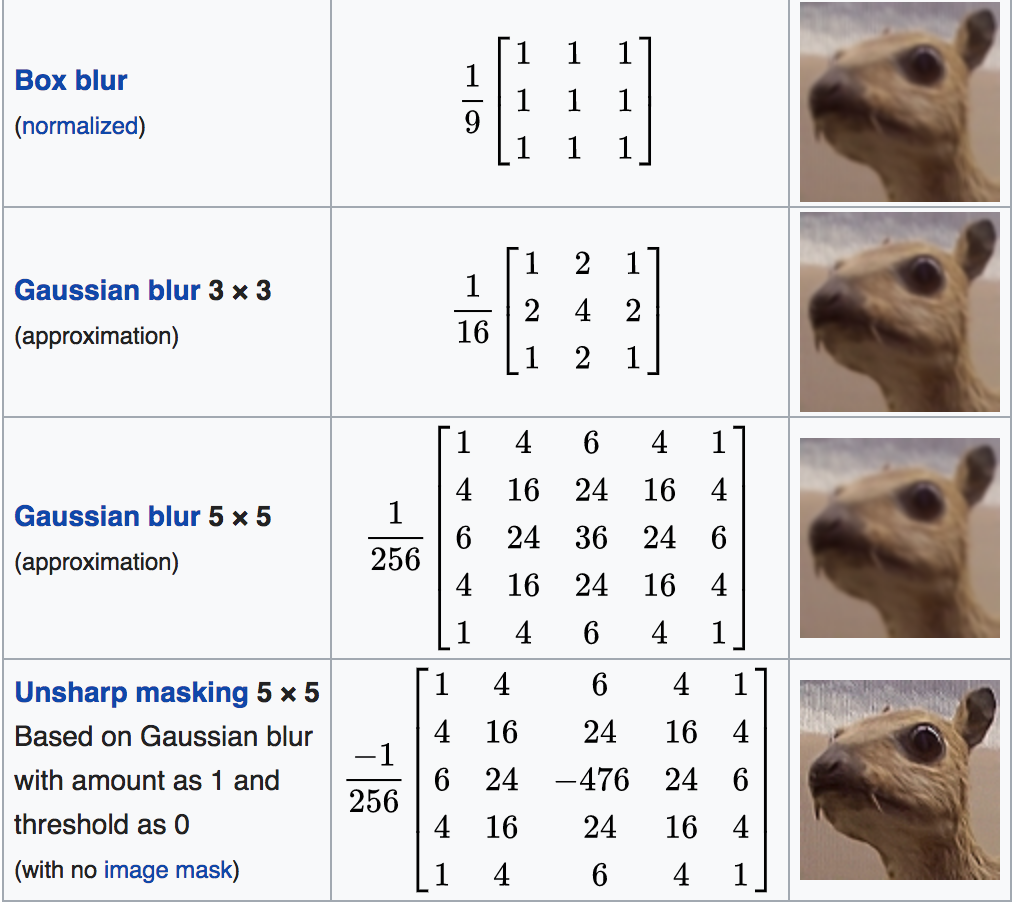
- Average (blur, smooth) 3x3 convolution kernel. This kernel is used for noise reduction and blurring the image. Must be normalized: for example, A/9, otherwise the result may not fit the (0, 255) range. there is more advanced filter: Gaussian Filter (https://www.mathworks.com/help/images/ref/imgaussfilt.html).
- Sharpen 3x3 convolution kernel. This kernel is used to enhance the small differences and edges in the image.
- Edge detection: Another word for object detection is segmentation. The object to be segmented differs greatly in contrast from the background image. Changes in contrast can be detected by operators that calculate the gradient of an image. The gradient image can be calculated and a threshold can be applied to create a binary mask containing the segmented cell. the image can be further dilated to get the contunous contour (https://www.mathworks.com/help/images/examples/detecting-a-cell-using-image-segmentation.html).
- there are also horizontal and vertical edge detection kernels:
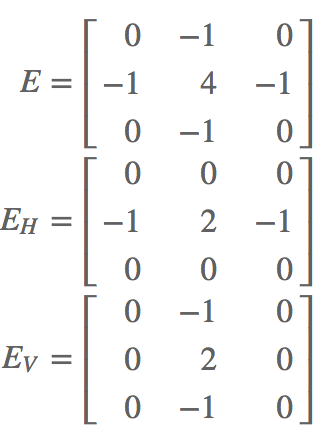
- Gradient detection: Kernels GH and GV are to calculate the magnitude of the horizontal and the vertical gradient.
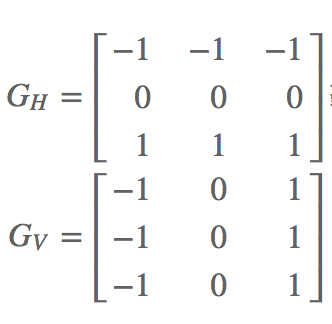
- Sobel operator: 3x3 conv kernel.

Sobel operators are similar to the gradient kernels, approximating the smoothed gradient of the image in horizontal and vertical directions. It can be seen from the decomposing, that this operator is a combination of a gradient detector and a smoothing kernel.
- Embossing 3x3 conv kernel:
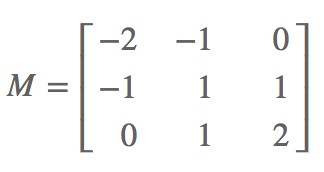
Summary:
for a NxN size image, the output size that after the conv with above kernel applied is: (N-F+2*P)/stride+1, where F is the filter (kernel) size, and P is the number of padded zeros; if not dividiable, ca apply zero pad into the original image (if necessary in practice). in general, common to see CONV layers with stride 1, filters of size FxF, and zero-padding with (F-1)/2. (will preserve size spatially):

(from: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf)
source:
http://setosa.io/ev/image-kernels/
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
