20180925-3 效能分析
此作业的要求参见https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
对上周作业中的功能4 (仅由文件重定向读入,不由控制台读入) 做效能分析,以[https://coding.net/u/younggift/p/word_count_demo/git/blob/master/war_and_peace.txt]为输入数据。
git地址:https://coding.net/u/Ruidxr/p/Word_Frequency_Count/git
1. 以 战争与和平 作为输入文件,重读向由文件系统读入。
由于在vs中使用profile测试功能4会出现如下错误:

多次安装vs2015也并没能完成测试,最后CPU参数的测定以及后续的测试使用了very-sleepy。
第一次:
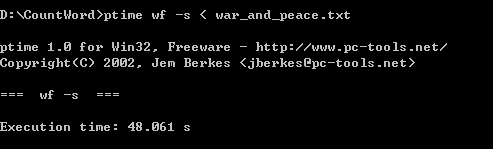

第二次:
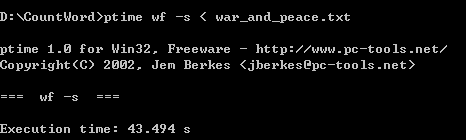

第三次:
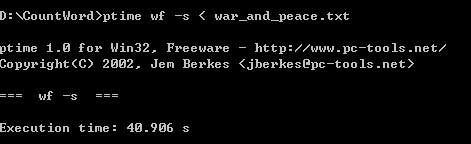

2. 给出你猜测程序的瓶颈。
测试前我猜测的程序的瓶颈是单词识别部分的代码,因为我是一个字符一个字符进行判断的,觉得很耗时。代码如下:


while(!feof(fp)) { c=fgetc(fp); if((c>=97 && c<=122) || (c>=65 && c<=90) || c==95 || c==45 || c==39) { if(c>=65 && c<=90) str[i]=c+32; else str[i]=c; //word中用"_"或'-'或'\''连接的算一个单词 str[++i]='\0'; flag=0; } else { if(flag==0) //如果是紧跟(考虑到有连续出现2个及以上标点的情况)在一个字母后的标点, //则前面读取到了一个单词,存入链表 { Save_word(str,head); flag=1; i=0; } } }
3. 通过very-sleepy找程序的瓶颈。
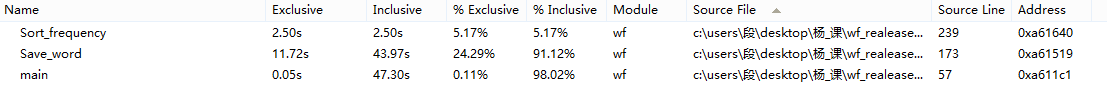
根据截图可以看出排序和存储单词这两个函数十分耗时,由于功能4的单词的判定写在了主函数里,也比较耗时。
4. 根据瓶颈,"尽力而为"地优化程序性能。
将排序算法由选择排序改为快速排序;
void QuickSortstruct word* array,struct word* left,struct word* right) { assert(array); if(left.num >= right.num) { return; } QuickSort(array,left,index->next); QuickSort(array,index->next,right); }
由于程序使用了链表,在存储单词的过程中十分耗时,应该改用数组会更有效率,但是由于所需改动太大,没能实现。
通过这次效能测试,深刻的体会到了链表有多费时。
5. 再次使用very-sleepy,给出此时的花费。
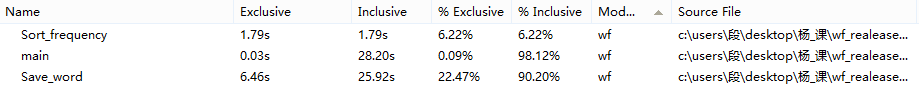
|
作者:段小胖 本文版权归作者和博客园共有,欢迎转载。未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出,以免更多的人被误导。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号