
基于PPQ的CNN卷积神经网络INT8型量化应用小结
1、引言
对于在FPGA端侧进行CNN卷积神经网络加速,合适的量化方法不仅能够有效的提升DSP在单位周期内的操作数,同样也能够降低对存储空间、片内外交互带宽、逻辑资源等的需求。例如采用16Bit量化方式,每个DSP可以进行1次乘法运算;采用8Bit量化方式,DSP可以进行2次乘法运算,这个在之前的博客里有提到(https://www.cnblogs.com/ruidongwu/p/15713090.html)。
如果要实现INT8类型的量化,那么很关键的一点是选择合适的量化算法,很显然如果采用直接量化,势必会带来极大的精度损失,甚至有可能导致量化后的网络根本不可用,因此训练后量化(Post Training Quantization, PTQ)将输入少部分测试图片用于权重矫正,能够降低由于量化带来的计算误差,并且在精度上能够有很好的保障。其实在Tensorflow和Pytorch里面已经集成有很好的量化策略,但是这些策略更多是面向一部分平台,并且能够支持的量化方式是有限的。例如Tensorflow中通过8Bit量化感知训练得到的TFLite文件,对于权重数据采用的是非对称量化策略,也许在部分平台已经取得了很好的效果,但是在笔者当前课题所研究的面向FPGA平台的CNN加速场景并不是最优的选择。因此,选择适合FPGA平台的量化算法与量化策略,能够简化FPGA中加速器的开发流程。
综上所示,为了更好的开发适用于FPGA平台的量化策略,本文以商汤高性能计算团队(HPC)在OpenPPL开源项目中的PPQ量化工具(https://github.com/openppl-public/ppq)为例,实现对称的Power of 2量化方式的分析与原理性代码演示。
PS:笔者认为PPQ是见过最好的量化工具,没有之一。感兴趣的网友可以通过B站的视频来进一步了解(https://space.bilibili.com/289239037)
2、量化方式与原理分析
根据量化方式的不同,分为对称/非对称、整数(Power of 2)/非整数、线性/非线性、逐层/逐通道(per Tensor/Channel)等模式的随意组合,详细情况可通过商汤在B站发布的视频(https://www.bilibili.com/video/BV1fB4y1m7fJ)来进一步了解。
那么上述量化策略的使用,对于FPGA而言,效果最好的当然是对称+整数+线性+逐层的量化方式,当然逐通道也是可以的,理论上逐通道要比逐层的量化误差更小。
因此,接下来将对适合FPGA的量化策略进行理论分析,假设卷积计算的公式如下,其中$ \odot $为卷积操作,$A_n$为第n层卷积的输入特征图,$A_{n+1}$为第n层卷积的输出特征图,$W_n$为第n层卷积的卷积核权重,$B_n$为第n层卷积的偏置,
${A_{n + 1}} = {A_n} \odot {W_n} + {B_n}$
那么根据所采用的量化方式为Power of 2量化,对应量化因子为$S$,卷积计算可替换为如下计算过程:
${A_{n + 1}}{S_{{a_{n + 1}}}} = {A_n}{S_{{a_n}}} \odot {W_n}{S_{{w_n}}} + {B_n}{S_{{b_n}}}$
${S_x} = {2^x}$
而上述公式可进一步修改为:
${A_{n + 1}}{S_{{a_{n + 1}}}} = \left( {{A_n} \odot {W_n}} \right){S_{{a_n}}}{S_{{w_n}}} + {B_n}{S_{{b_n}}}$
不失一般性,如果我们将偏置和INT8卷积放在一起,那么上述计算公式可进一步更新为:
${A_{n + 1}} = \left( {{A_n} \odot {W_n} + {B_n}\frac{{{S_{{b_n}}}}}{{{S_{{a_n}}}{S_{{w_n}}}}}} \right)\frac{{{S_{{a_n}}}{S_{{w_n}}}}}{{{S_{{a_{n + 1}}}}}}$
然后将上述尺度因子转换为指数运算:
${A_{n + 1}} = \left( {{A_n} \odot {W_n} + {B_n}{2^{{b_n} - {a_n} - {w_n}}}} \right){2^{{a_n} + {w_n} - {a_{n + 1}}}}$
对于任意的2的$x$指数运算,在硬件逻辑上可进一步简化为:
$\left\{ \begin{array}{l}R \times {2^x} = R < < \left| x \right|,x \ge 0\\R \times {2^x} = R > > \left| x \right|,x < 0\end{array} \right. $
而在PPQ中典型的NXP_INT8量化模式中,对于偏置数据$B_n$的处理方式为:经过左移$ \beta $位至相同尺度,然后与卷积的结果进行累加。由于累加后结果需要考虑不同层中特征图数据的量化尺度$A_n$与$A_{n+1}$,对应累加后数据的右移$ \alpha $位操作。考虑到累加后数据存在溢出的情况,需要针对移位数据进行尺度空间范围内的截断操作。因此上述计算过程最终简化为:
$ \left\{ \begin{array}{l} {A_{n + 1}} = clip\left[ {\left( {{A_n} \odot {W_n} + {B_n} < < \beta } \right) > > \alpha } \right]\\ \alpha = {a_{n + 1}} - {a_n} - {w_n} = \left| {{a_n} + {w_n} - {a_{n + 1}}} \right|\\ \beta = {b_n} - {a_n} - {w_n} = \left| {{a_n} + {w_n} - {b_n}} \right| \end{array} \right. $
那么传统的INT8型量化后数据在3x3卷积计算流程如下:在整个计算中,只存在INT8类型乘法、32Bit加法、移位与截断操作,非常适合FPGA硬件电路的运算。等效的伪代码运行如下:
1 #define R row 2 #define C column 3 #define M input_channel 4 #define N output_channel 5 signed char W0[N][M][3][3];//weight 6 signed short int B0[N];//bias 7 signed char A0[M][R][C];//input feature map 8 signed char A1[N][R][C];//output feature map 9 10 unsigned char W0_S[N];//weight scale 11 unsigned char B0_S[N];//bias scale 12 unsigned char A0_S;//input scale 13 unsigned char A1_S;//output scale 14 15 void ConvFunc(void) 16 { 17 for(int n=0; n<N; n++) 18 for(int r=0; r<R; r++) 19 for(int c=0; c<C; c++) 20 { 21 int sum = B0[n]; 22 sum <<= W0_S[n]+A0_S-B0_S[n];//bias scale shift 23 for(int m=0; m<M; m++) 24 for(int k0=0; k0<3; k0++) 25 for(int k1=0; k1<3; k1++) 26 { 27 if(is_range()) 28 sum += A0[m][r+k0-1][c+k1-1]*W0[n][m][k0][k1]; 29 } 30 sum >>= W0_S[n]+A0_S-A1_S;//layer scale shift 31 A1[n][r][c] = clip(sum); 32 } 33 }
3、基于Mnist数据集的分类网络量化示例
本节使用Mnist数据集进行实际的示例,所有的代码与权重都会在文章末尾提供下载地址。
首先我们需要基于pytorch训练一个浮点类型的网络实现手写字符分类,其中网络训练代码如下:
1 ''' 2 @Time : 2022.04.23 3 @Author : wuruidong 4 @Email : wuruidong@hotmail.com 5 @FileName: LeNet_onnx.py 6 @Software: python pytorch=1.6.0 ppq=0.6.3 onnx=1.8.1 7 @Cnblogs : https://www.cnblogs.com/ruidongwu 8 ''' 9 import torch as tf 10 import torch.nn as nn 11 import torch.nn. functional as F 12 import torch.optim as optim 13 from torch.autograd import Variable 14 from torchvision import datasets, transforms 15 16 # convenience class to keep track of averages 17 class Metric(object): 18 def __init__(self, name): 19 self.name = name 20 self.sum = tf.tensor(0.) 21 self.n = tf.tensor(0.) 22 def update(self, val): 23 self.sum += val.cpu() 24 self.n += 1 25 @property 26 def avg(self): 27 return self.sum / self.n 28 29 class LeNet(tf.nn.Module): 30 def __init__(self): 31 super(LeNet, self).__init__() 32 self.conv1 = nn.Conv2d(1, 4, 3, 1) 33 self.bn1 = nn.BatchNorm2d(4) 34 self.relu1 = nn.ReLU(inplace=False) # <== Module, not Function! 35 self.pool1 = nn.MaxPool2d(2) 36 37 self.conv2 = nn.Conv2d(4, 8, 3, 1) 38 self.bn2 = nn.BatchNorm2d(8) 39 self.relu2 = nn.ReLU(inplace=False) # <== Module, not Function! 40 #self.pad = nn.ZeroPad2d(padding=(1,0,1,0)) 41 self.pool2 = nn.MaxPool2d(2, padding=1) 42 43 self.conv3 = nn.Conv2d(8, 16, 3, 1) 44 self.bn3 = nn.BatchNorm2d(16) 45 self.relu3 = nn.ReLU(inplace=False) # <== Module, not Function! 46 self.pool3 = nn.MaxPool2d(2) 47 48 self.fc1 = nn.Linear(64, 10) 49 50 def forward(self, x): 51 x = self.conv1(x) 52 x = self.bn1(x) 53 x = self.relu1(x) # <== Module, not Function! 54 x = self.pool1(x) 55 56 x = self.conv2(x) 57 x = self.bn2(x) 58 x = self.relu2(x) # <== Module, not Function! 59 #x = self.pad(x) 60 x = self.pool2(x) 61 62 x = self.conv3(x) 63 x = self.bn3(x) 64 x = self.relu3(x) # <== Module, not Function! 65 x = self.pool3(x) 66 67 x = tf.flatten(x, 1) 68 x = self.fc1(x) 69 #output = F.log_softmax(x, dim=1) # <== the softmax operation does not need to be quantized, we can keep it as it is 70 output = x 71 return output 72 73 def test(model, device, test_loader, integer=False, verbose=False): 74 model.eval() 75 test_loss = 0 76 correct = 0 77 test_acc = Metric('test_acc') 78 79 with tf.no_grad(): 80 for data, target in test_loader: 81 if integer: # <== this will be useful when we get to the 82 data *= 255 # IntegerDeployable stage 83 data, target = data.to(device), target.to(device) 84 output = model(data) 85 test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss 86 pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability 87 correct += pred.eq(target.view_as(pred)).sum().item() 88 test_acc.update((pred == target.view_as(pred)).float().mean()) 89 90 test_loss /= len(test_loader.dataset) 91 return test_acc.avg.item() * 100. 92 93 device = tf.device("cuda" if tf.cuda.is_available() else "cpu") 94 print('current device is', device) 95 96 train_loader = tf.utils.data.DataLoader( 97 datasets.MNIST('../data', train=True, download=False, transform=transforms.Compose([ 98 transforms.ToTensor() 99 ])), 100 batch_size=128, shuffle=True 101 ) 102 test_loader = tf.utils.data.DataLoader( 103 datasets.MNIST('../data', train=False, transform=transforms.Compose([ 104 transforms.ToTensor() 105 ])), 106 batch_size=128, shuffle=False 107 ) 108 109 110 model = LeNet() 111 if tf.cuda.is_available(): 112 model = model.cuda() 113 114 criterion = nn.CrossEntropyLoss() 115 optimizer = optim.SGD(model.parameters(), lr=1e-2) 116 117 losses = [] 118 acces = [] 119 eval_losses = [] 120 eval_acces = [] 121 122 for e in range(10): 123 train_loss = 0 124 train_acc = 0 125 model.train() 126 for im, label in train_loader: 127 im = Variable(im)*255 128 label = Variable(label) 129 if tf.cuda.is_available(): 130 im = im.cuda() 131 label = label.cuda() 132 out = model(im) 133 loss = criterion(out, label) 134 135 optimizer.zero_grad() 136 loss.backward() 137 optimizer.step() 138 139 train_loss += loss.item() 140 141 _, pred = out.max(1) 142 num_correct = (pred==label).sum().item() 143 144 acc = num_correct/im.shape[0] 145 train_acc += acc 146 147 losses.append(train_loss/len(train_loader)) 148 acces.append(train_acc/len(train_loader)) 149 150 eval_loss = 0 151 eval_acc = 0 152 model.eval() 153 154 acc = test(model, device, test_loader, integer=True) 155 print(e, "FullPrecision accuracy: %.02f%%" % acc) 156 157 158 tf.save(model.state_dict(), 'LeNet.pth') 159 160 161 dummy_input = tf.randn(16, 1, 28, 28, device='cuda') 162 input_names = [ "input" ] 163 output_names = [ "output" ] 164 165 tf.onnx.export(model, dummy_input, "LeNet.onnx", verbose=True, input_names=input_names, output_names=output_names) 166 print('Application is over!')
上面的这个网络其实结构比较简单,最后需要在working文件夹下导出model.onnx模型,该模型用来作为PPQ量化训练的输入模型。
然后再使用PPQ来完成量化训练(如果PPQ的版本<0.6.3),对应Python代码如下:
1 ''' 2 @Time : 2022.04.23 3 @Author : wuruidong 4 @Email : wuruidong@hotmail.com 5 @FileName: ppq_onnx.py 源文件参考PPQ中ProgramEntrance.py脚本 6 @Software: python pytorch=1.6.0 ppq=0.6.3 onnx=1.8.1 7 @Cnblogs : https://www.cnblogs.com/ruidongwu 8 ''' 9 from ppq import * 10 from ppq.api import * 11 from torch.utils.data import DataLoader 12 from torchvision import datasets, transforms 13 14 # modify configuration below: 15 WORKING_DIRECTORY = 'working' # choose your working directory 16 TARGET_PLATFORM = TargetPlatform.NXP_INT8 # choose your target platform 17 MODEL_TYPE = NetworkFramework.ONNX # or NetworkFramework.CAFFE 18 INPUT_LAYOUT = 'chw' # input data layout, chw or hwc 19 NETWORK_INPUTSHAPE = [16, 1, 28, 28] # input shape of your network 20 CALIBRATION_BATCHSIZE = 16 # batchsize of calibration dataset 21 EXECUTING_DEVICE = 'cuda' # 'cuda' or 'cpu'. 22 REQUIRE_ANALYSE = True 23 DUMP_RESULT = False 24 25 # ------------------------------------------------------------------- 26 # SETTING 对象用于控制 PPQ 的量化逻辑 27 # 当你的网络量化误差过高时,你需要修改 SETTING 对象中的参数来进行特定的优化 28 # ------------------------------------------------------------------- 29 SETTING = UnbelievableUserFriendlyQuantizationSetting( 30 platform = TARGET_PLATFORM, finetune_steps = 2500, 31 finetune_lr = 1e-3, calibration = 'percentile', 32 equalization = True, non_quantable_op = None) 33 SETTING = SETTING.convert_to_daddy_setting() 34 35 print('正准备量化你的网络,检查下列设置:') 36 print(f'WORKING DIRECTORY : {WORKING_DIRECTORY}') 37 print(f'TARGET PLATFORM : {TARGET_PLATFORM.name}') 38 print(f'NETWORK INPUTSHAPE : {NETWORK_INPUTSHAPE}') 39 print(f'CALIBRATION BATCHSIZE: {CALIBRATION_BATCHSIZE}') 40 41 42 mnist = datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor()])) 43 mnist_data = mnist.data.view(-1, 1, 28, 28).float() 44 dataset_len = mnist_data.shape[0] 45 #mnist_data = mnist_data/255 46 calibration_dataset = mnist_data 47 48 dataloader = DataLoader( 49 dataset=calibration_dataset, 50 batch_size=32, shuffle=True) 51 52 print('网络正量化中,根据你的量化配置,这将需要一段时间:') 53 quantized = quantize( 54 working_directory=WORKING_DIRECTORY, setting=SETTING, 55 model_type=MODEL_TYPE, executing_device=EXECUTING_DEVICE, 56 input_shape=NETWORK_INPUTSHAPE, target_platform=TARGET_PLATFORM, 57 dataloader=dataloader, calib_steps=256) 58 59 # ------------------------------------------------------------------- 60 # 如果你需要执行量化后的神经网络并得到结果,则需要创建一个 executor 61 # 这个 executor 的行为和 torch.Module 是类似的,你可以利用这个东西来获取执行结果 62 # 请注意,必须在 export 之前执行此操作。 63 # ------------------------------------------------------------------- 64 executor = TorchExecutor(graph=quantized) 65 # output = executor.forward(input) 66 67 # ------------------------------------------------------------------- 68 # 导出 PPQ 执行网络的所有中间结果,该功能是为了和硬件对比结果 69 # 中间结果可能十分庞大,因此 PPQ 将使用线性同余发射器从执行结果中采样 70 # 为了正确对比中间结果,硬件执行结果也必须使用同样的随机数种子采样 71 # 查阅 ppq.util.fetch 中的相关代码以进一步了解此内容 72 # 查阅 ppq.api.fsys 中的 dump_internal_results 函数以确定采样逻辑 73 # ------------------------------------------------------------------- 74 if DUMP_RESULT: 75 dump_internal_results( 76 graph=quantized, dataloader=dataloader, 77 dump_dir=WORKING_DIRECTORY, executing_device=EXECUTING_DEVICE) 78 79 # ------------------------------------------------------------------- 80 # PPQ 计算量化误差时,使用信噪比的倒数作为指标,即噪声能量 / 信号能量 81 # 量化误差 0.1 表示在整体信号中,量化噪声的能量约为 10% 82 # 你应当注意,在 graphwise_error_analyse 分析中,我们衡量的是累计误差 83 # 网络的最后一层往往都具有较大的累计误差,这些误差是其前面的所有层所共同造成的 84 # 你需要使用 layerwise_error_analyse 逐层分析误差的来源 85 # ------------------------------------------------------------------- 86 print('正计算网络量化误差(SNR),最后一层的误差应小于 0.1 以保证量化精度:') 87 reports = graphwise_error_analyse( 88 graph=quantized, running_device=EXECUTING_DEVICE, steps=256, 89 dataloader=dataloader, collate_fn=lambda x: x.to(EXECUTING_DEVICE)) 90 for op, snr in reports.items(): 91 if snr > 0.1: ppq_warning(f'层 {op} 的累计量化误差显著,请考虑进行优化') 92 93 if REQUIRE_ANALYSE: 94 print('正计算逐层量化误差(SNR),每一层的独立量化误差应小于 0.1 以保证量化精度:') 95 layerwise_error_analyse(graph=quantized, running_device=EXECUTING_DEVICE, steps=256, 96 interested_outputs=None, 97 dataloader=dataloader, collate_fn=lambda x: x.to(EXECUTING_DEVICE)) 98 99 print('网络量化结束,正在生成目标文件:') 100 export(working_directory=WORKING_DIRECTORY, 101 quantized=quantized, platform=TargetPlatform.ONNXRUNTIME) 102 #使用NXP_INT8导出浮点权重表示方法的模型,使用ONNXRUNTIME导出带有原始整形权重表示方法的模型 103 104 # 如果你需要导出 CAFFE 模型,使用下面的语句 105 #export(working_directory=WORKING_DIRECTORY, 106 # quantized=quantized, platform=TARGET_PLATFORM, 107 # input_shapes=[NETWORK_INPUTSHAPE])
因为PPQ的版本现在已经更新了,有的网友联系我说上面的程序没办法跑,因此我添加了新版本的量化程序。在新的量化程序中,在当前目录下新建working文件夹,然后将生成的onnx模型文件复制到该文件夹并重命名为model.onnx;在我提供的源码里面这一步已经完成了,可以直接拿来测试。
使用PPQ来完成量化训练(如果PPQ的版本>=0.6.4),对应Python代码如下:
1 ''' 2 @Time : 2022.09.26 3 @Author : wuruidong 4 @Email : wuruidong@hotmail.com 5 @FileName: ppq_onnx_2.py 源文件参考PPQ中ProgramEntrance.py脚本 6 @Software: python pytorch=1.6.0 ppq>=0.6.4 onnx=1.8.1 7 @Cnblogs : https://www.cnblogs.com/ruidongwu 8 ''' 9 10 """ 11 这是一个 PPQ 量化的入口脚本,将你的模型和数据按要求进行打包: 12 13 This file will show you how to quantize your network with PPQ 14 You should prepare your model and calibration dataset as follow: 15 16 ~/working/model.onnx <-- your model 17 ~/working/data/*.npy or ~/working/data/*.bin <-- your dataset 18 19 if you are using caffe model: 20 ~/working/model.caffemdoel <-- your model 21 ~/working/model.prototext <-- your model 22 23 ### MAKE SURE YOUR INPUT LAYOUT IS [N, C, H, W] or [C, H, W] ### 24 25 quantized model will be generated at: ~/working/quantized.onnx 26 """ 27 from ppq import * 28 from ppq.api import * 29 from torch.utils.data import DataLoader 30 from torchvision import datasets, transforms 31 32 # modify configuration below: 33 WORKING_DIRECTORY = 'working' # choose your working directory 34 TARGET_PLATFORM = TargetPlatform.FPGA_INT8 # choose your target platform 35 MODEL_TYPE = NetworkFramework.ONNX # or NetworkFramework.CAFFE 36 INPUT_LAYOUT = 'chw' # input data layout, chw or hwc 37 NETWORK_INPUTSHAPE = [16, 1, 28, 28] # input shape of your network 38 CALIBRATION_BATCHSIZE = 16 # batchsize of calibration dataset 39 EXECUTING_DEVICE = 'cuda' # 'cuda' or 'cpu'. 40 REQUIRE_ANALYSE = True 41 DUMP_RESULT = False 42 43 # ------------------------------------------------------------------- 44 # SETTING 对象用于控制 PPQ 的量化逻辑 45 # 当你的网络量化误差过高时,你需要修改 SETTING 对象中的参数来进行特定的优化 46 # ------------------------------------------------------------------- 47 SETTING = UnbelievableUserFriendlyQuantizationSetting( 48 platform = TARGET_PLATFORM, finetune_steps = 2500, 49 finetune_lr = 1e-3, calibration = 'percentile', 50 equalization = True, non_quantable_op = None) 51 SETTING = SETTING.convert_to_daddy_setting() 52 53 print('正准备量化你的网络,检查下列设置:') 54 print(f'WORKING DIRECTORY : {WORKING_DIRECTORY}') 55 print(f'TARGET PLATFORM : {TARGET_PLATFORM.name}') 56 print(f'NETWORK INPUTSHAPE : {NETWORK_INPUTSHAPE}') 57 print(f'CALIBRATION BATCHSIZE: {CALIBRATION_BATCHSIZE}') 58 59 60 mnist = datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor()])) 61 mnist_data = mnist.data.view(-1, 1, 28, 28).float() 62 dataset_len = mnist_data.shape[0] 63 mnist_data = mnist_data/255 64 calibration_dataset = mnist_data 65 66 dataloader = DataLoader( 67 dataset=calibration_dataset, 68 batch_size=32, shuffle=True) 69 70 print('网络正量化中,根据你的量化配置,这将需要一段时间:') 71 quantized = quantize( 72 working_directory=WORKING_DIRECTORY, setting=SETTING, 73 model_type=MODEL_TYPE, executing_device=EXECUTING_DEVICE, 74 input_shape=NETWORK_INPUTSHAPE, target_platform=TARGET_PLATFORM, 75 dataloader=dataloader, calib_steps=256) 76 77 # ------------------------------------------------------------------- 78 # 如果你需要执行量化后的神经网络并得到结果,则需要创建一个 executor 79 # 这个 executor 的行为和 torch.Module 是类似的,你可以利用这个东西来获取执行结果 80 # 请注意,必须在 export 之前执行此操作。 81 # ------------------------------------------------------------------- 82 executor = TorchExecutor(graph=quantized) 83 # output = executor.forward(input) 84 85 # ------------------------------------------------------------------- 86 # 导出 PPQ 执行网络的所有中间结果,该功能是为了和硬件对比结果 87 # 中间结果可能十分庞大,因此 PPQ 将使用线性同余发射器从执行结果中采样 88 # 为了正确对比中间结果,硬件执行结果也必须使用同样的随机数种子采样 89 # 查阅 ppq.util.fetch 中的相关代码以进一步了解此内容 90 # 查阅 ppq.api.fsys 中的 dump_internal_results 函数以确定采样逻辑 91 # ------------------------------------------------------------------- 92 if DUMP_RESULT: 93 dump_internal_results( 94 graph=quantized, dataloader=dataloader, 95 dump_dir=WORKING_DIRECTORY, executing_device=EXECUTING_DEVICE) 96 97 # ------------------------------------------------------------------- 98 # PPQ 计算量化误差时,使用信噪比的倒数作为指标,即噪声能量 / 信号能量 99 # 量化误差 0.1 表示在整体信号中,量化噪声的能量约为 10% 100 # 你应当注意,在 graphwise_error_analyse 分析中,我们衡量的是累计误差 101 # 网络的最后一层往往都具有较大的累计误差,这些误差是其前面的所有层所共同造成的 102 # 你需要使用 layerwise_error_analyse 逐层分析误差的来源 103 # ------------------------------------------------------------------- 104 print('正计算网络量化误差(SNR),最后一层的误差应小于 0.1 以保证量化精度:') 105 reports = graphwise_error_analyse( 106 graph=quantized, running_device=EXECUTING_DEVICE, steps=256, 107 dataloader=dataloader, collate_fn=lambda x: x.to(EXECUTING_DEVICE)) 108 for op, snr in reports.items(): 109 if snr > 0.1: ppq_warning(f'层 {op} 的累计量化误差显著,请考虑进行优化') 110 111 if REQUIRE_ANALYSE: 112 print('正计算逐层量化误差(SNR),每一层的独立量化误差应小于 0.1 以保证量化精度:') 113 layerwise_error_analyse(graph=quantized, running_device=EXECUTING_DEVICE, steps=256, 114 interested_outputs=None, 115 dataloader=dataloader, collate_fn=lambda x: x.to(EXECUTING_DEVICE)) 116 117 print('网络量化结束,正在生成目标文件:') 118 export(working_directory=WORKING_DIRECTORY, 119 quantized=quantized, platform=TargetPlatform.ONNXRUNTIME) 120 121 # 如果你需要导出 CAFFE 模型,使用下面的语句 122 #export(working_directory=WORKING_DIRECTORY, 123 # quantized=quantized, platform=TARGET_PLATFORM, 124 # input_shapes=[NETWORK_INPUTSHAPE])
完成上述操作以后,我们可以得到量化后的quantized.onnx文件。如果使用ONNXRUNTIME导出方式,还可以进一步看到每一层权重的整形数据表示。如下图所示:
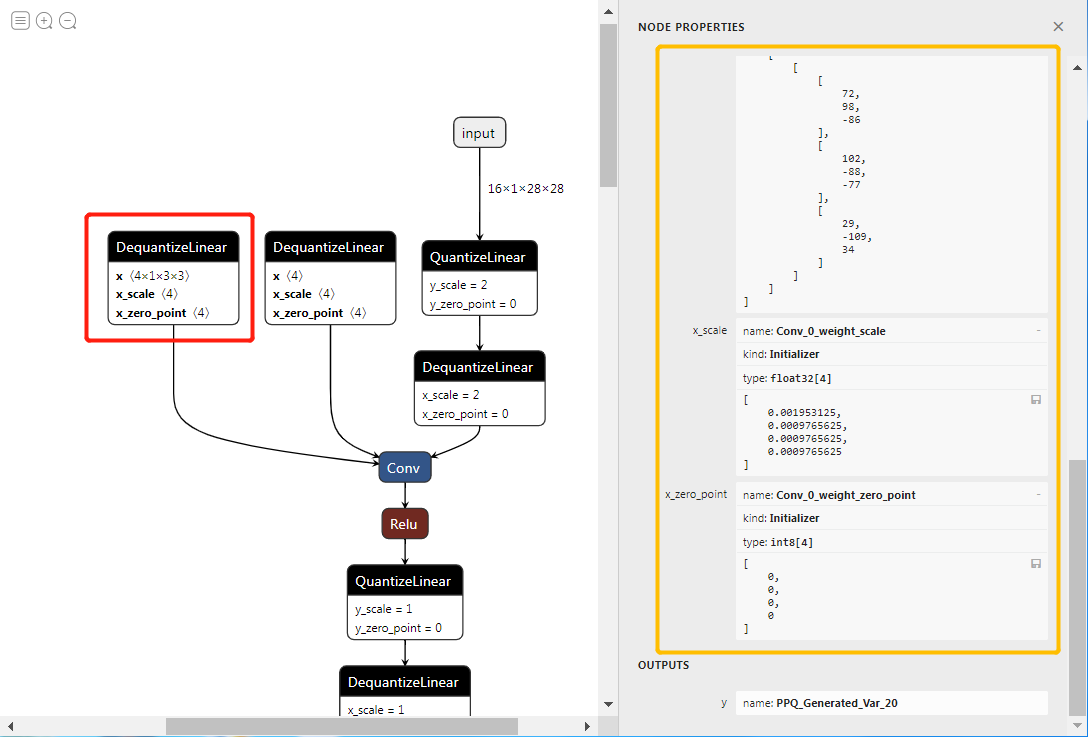
上面的权重数据即为推理中所需要的原始整形数据,对应的scale也都是2的指数,方面层与层之间的量化与反量化操作,即通过简单的移位截断完成数据尺度的转换。
同时,笔者也使用了导出为NXP_IN8类型的onnx文件,并且编写测试代码,查看量化后网络推理结果是能够正确完成分类,对应测试代码如下:
1 ''' 2 @Time : 2022.04.23 3 @Author : wuruidong 4 @Email : wuruidong@hotmail.com 5 @FileName: my_onnxruntime.py 6 @Software: python pytorch=1.6.0 onnxruntime=1.3.0 7 @Cnblogs : https://www.cnblogs.com/ruidongwu 8 ''' 9 import onnxruntime 10 from torch.utils.data import DataLoader 11 from torchvision import datasets, transforms 12 import numpy as np 13 14 sess = onnxruntime.InferenceSession("working/quantized.onnx") 15 16 mnist = datasets.MNIST('../data', train=False) 17 mnist_label = mnist.targets.view(-1, 16).numpy() 18 print(mnist_label[0]) 19 20 mnist_data = mnist.data.view(-1, 16, 1, 28, 28).float() 21 dataset_len = mnist_data.shape[0] 22 23 output = sess.run(['output'], {'input' : mnist_data[0].numpy()}) 24 25 out = np.array(output) 26 out = np.squeeze(out) 27 print(out.shape) 28 print(np.argmax(out, 1))
4、完整版前向推理(C语言)
为了进一步了解量化后网络前向推理的细节,笔者当时也是考虑到验证上述理论思路是否理解到位,因此使用C语言编写前向推理过程,并验证推理结果是否正确,测试结果肯定是通过了。受限于篇幅原因,笔者将上述所有代码和模型文件公布出来,方便大家对INT8类型的量化训练、PPQ工具有一个初步的了解,也希望能起到一个抛砖引玉的作用。由于笔者能力有限,上述理解不可避免存在瑕疵与疏忽的地方,如有错误,还行各位网友不吝赐教,一定会更改其中存在的问题,力求给大家带来一份高质量的理解。
最后,特别感谢商汤科技HPC团队的Jzz对笔者在量化过程中所遇到问题的详细解答,也感谢能够提供这么高质量的量化工具,感谢贡献PPQ的所有人(https://github.com/openppl-public/ppq)。
如果您觉得本文有所帮助,那么感谢您在写论文的时候,帮忙引用下我们团队的论文,谢谢大家。
① https://link.springer.com/article/10.1007/s10489-022-04251-3
② https://jeit.ac.cn/cn/article/doi/10.11999/JEIT220130
③ https://www.worldscientific.com/doi/10.1142/S0218126623500755

