

Xilinx器件INT8优化方法的HLS示例
1、引言
Xilinx器件自带的DSP48E乘法器能够实现18x27位的乘法和高达48位的累加,关于Xilinx的DSP如何实现INT8的优化,官方早在2016年发布的WP486白皮书中已经给出了明确的指引。其设计思路是将两组具备同一系数的INT8乘法计算经过移位拼接,实现由单个DSP完成两组INT8的乘法和累加,最终实现1.75倍的性能提升。官方已经给出了很好的示例,笔者在此只是分享个人的一些感悟,以及该方法所对应的HLS实现方法。说实话,白皮书在2016年已经给出,现在已经过去6年了,再继续研究CNN在FPGA端侧的加速已经没有任何意义了,以后是ASIC的天下,而且我的研究也只是重复造轮子,官方提供的FINN和Brevitas工具链已经能够很好的实现FPGA对常用CNN算子的支持,直接拿来可以应对几乎所用的场景。唉,没意义~
2、DSP48E工作示例
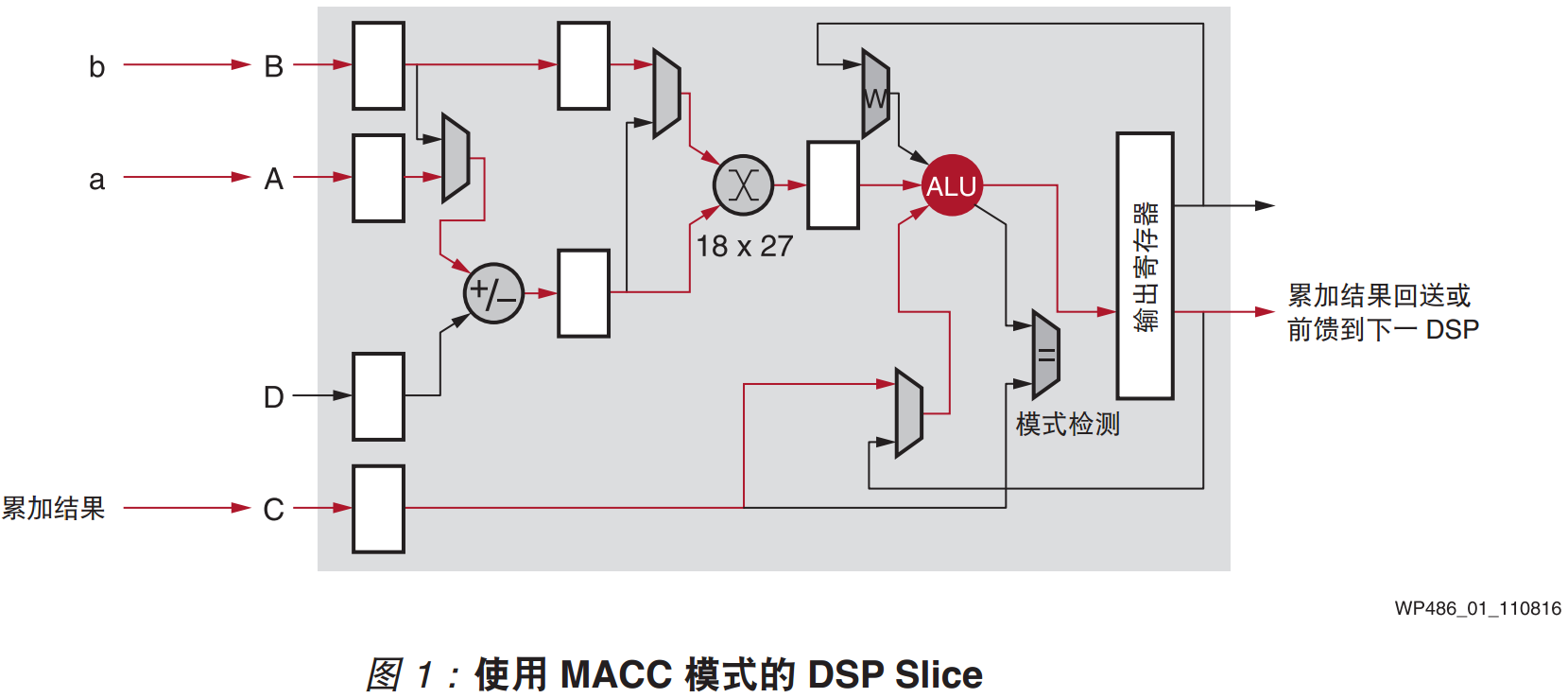
此处医用WP486官方文档的图片1,如下图所示。其中输入为A、B、C和D,实现的输出为B*(A+D)+C,其中C可以是上一次结果的输出,从而实现累加器的功能,根据其中对应的核心乘法器位宽为18x27,即输入数据B的位宽不应超过18bit,输入数据A和D的逻辑运算结果不应超过27bit。因此如果实现通用的16bit与16bit乘法,一般需要消耗1个DSP;而如果是两组8bit与8bit的数据相乘,如果能够先对数据完成移位拼接,然后使得乘法运算后的结果不对另一组数据的乘法运算结果造成影响,那么即可实现INT8计算的优化。
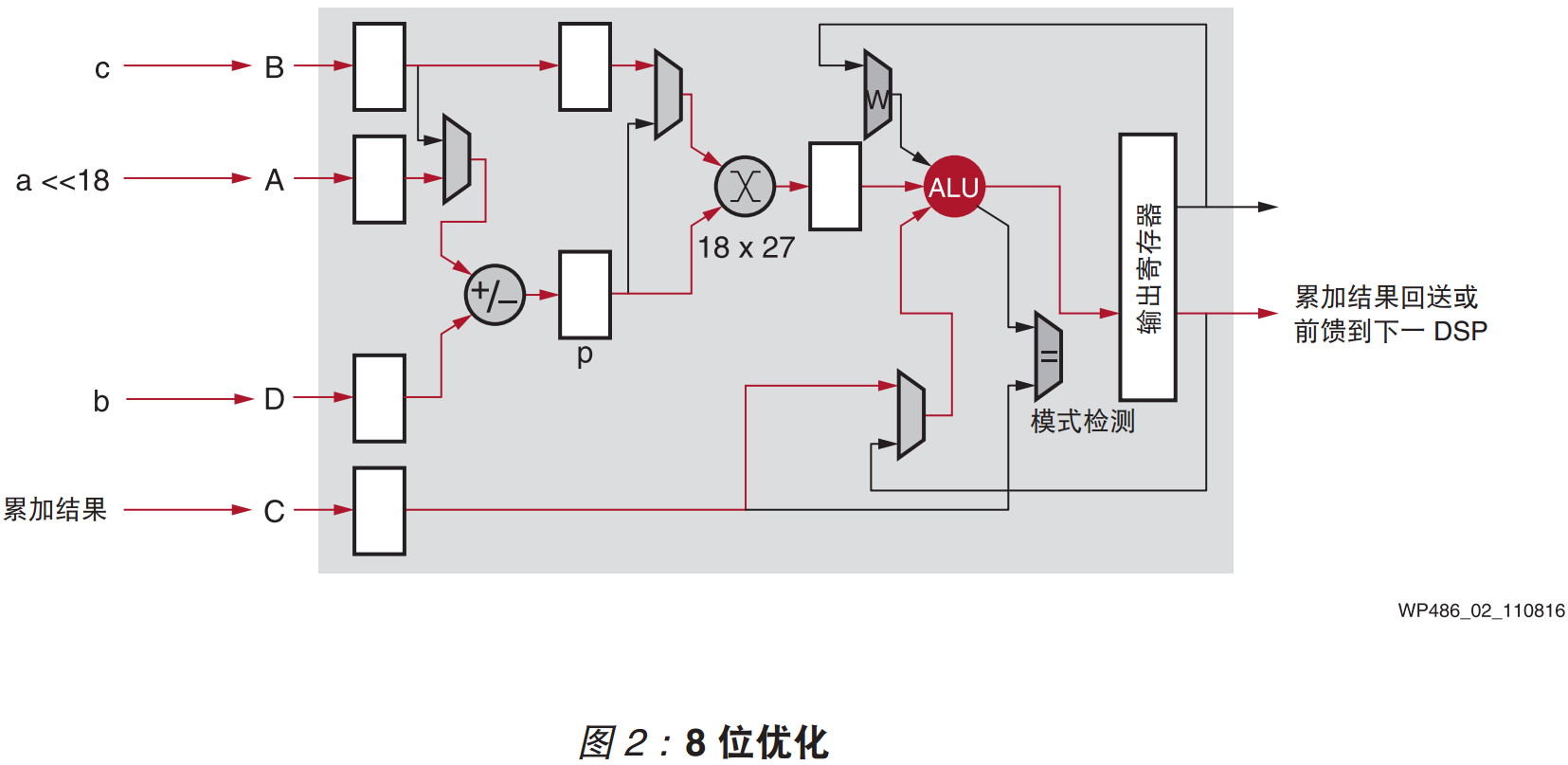
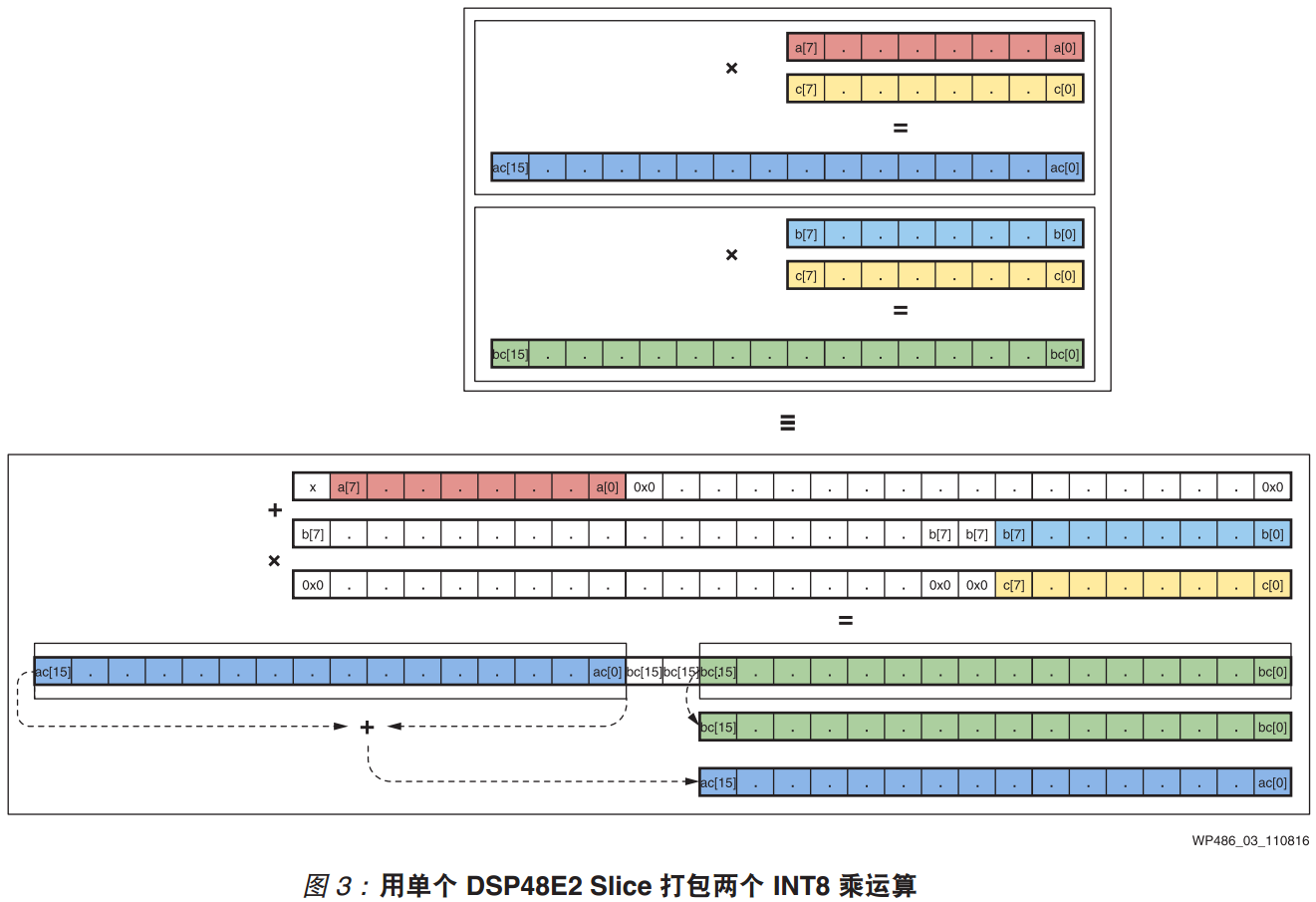
这里优化的前提是乘法运算的要有同一个乘数,即z0=a*c和z1=b*c。其核心优化思想是将y0和y1移位拼接为一个具有更大位宽的Y,计算x*Y,然后再对计算结果进行拆分,即得到z0和z1。 计算过程对应wp486里面的图2和图3。
3、HLS实现步骤与程序
那么针对上述所提出的优化思路,我们可以在HLS中对其进行仿真验证,结合图3中的设计思想,核心步骤在于数据打包与计算结果的拆分。我们以z0=a*c和z1=b*c作为核心示例,同时以CNN中常见的特征图复用与权重复用两种计算策略进行说明。
在数据打包的过程中,若a的数据位宽为W_a;b的数据位宽为W_b;c的数据位宽为W_c;则打包后的数据位宽为W_a+W_b+W_c,且该结果不能超过27bit,以及W_c不能超过18bit,其主要原因在于DSP48的输入为18bitx27bit。
因此笔者针对上述过程,只优化乘法部分,而对累加部分不作具体概述,因此做出如下的验证测试用例:
1 // @Time : 2021.12.20 2 // @Author : wuruidong 3 // @Email : wuruidong@hotmail.com 4 // @FileName: MAC_8bit_tb.cpp 5 // @Software: Vivado HLS 2018.3 6 // @Cnblogs : https://www.cnblogs.com/ruidongwu 7 8 #include <hls_half.h> 9 #include <ap_fixed.h> 10 #include <iostream> 11 using namespace std; 12 13 //iii 14 template<int A_N, int W0_N, int W1_N> 15 ap_int<A_N+W0_N+A_N+W1_N> MUL_MAC(ap_int<A_N> A, ap_int<W0_N> W0, ap_int<W1_N> W1) 16 { 17 ap_int<W0_N+A_N+W1_N> W; 18 W = (W0, ap_uint<A_N+W1_N>(0)) + ap_int<W0_N+A_N+W1_N>(W1); 19 20 ap_int<A_N+W0_N> r0; 21 ap_int<A_N+W1_N> r1; 22 23 (r0, r1) = A*W; 24 25 r0 = r0+r1[A_N+W1_N-1]; 26 27 return (r0,r1); 28 } 29 30 //uuu 31 template<int A_N, int W0_N, int W1_N> 32 ap_uint<A_N+W0_N+A_N+W1_N> MUL_MAC(ap_uint<A_N> A, ap_uint<W0_N> W0, ap_uint<W1_N> W1) 33 { 34 ap_uint<W0_N+A_N+W1_N> W; 35 W = (W0, ap_uint<A_N>(0), W1); 36 37 ap_uint<A_N+W0_N> r0; 38 ap_uint<A_N+W1_N> r1; 39 40 (r0, r1) = A*W; 41 42 //r0 = r0+r1[A_N+W1_N-1]; 43 44 return (r0,r1); 45 } 46 47 //uii 48 template<int A_N, int W0_N, int W1_N> 49 ap_int<A_N+W0_N+A_N+W1_N> MUL_MAC(ap_uint<A_N> A, ap_int<W0_N> W0, ap_int<W1_N> W1) 50 { 51 ap_int<W0_N+A_N+W1_N> W; 52 W = (W0, ap_uint<A_N+W1_N>(0)) + ap_int<W0_N+A_N+W1_N>(W1); 53 54 ap_int<A_N+W0_N> r0; 55 ap_int<A_N+W1_N> r1; 56 57 (r0, r1) = A*W; 58 59 r0 = r0+r1[A_N+W1_N-1]; 60 61 return (r0,r1); 62 } 63 64 //iuu 65 template<int W_N, int A0_N, int A1_N> 66 ap_int<W_N+A0_N+W_N+A1_N> MUL_MAC(ap_int<W_N> W, ap_uint<A0_N> A0, ap_uint<A1_N> A1) 67 { 68 ap_uint<A0_N+W_N+A1_N> A; 69 A = (A0, ap_uint<W_N>(0), A1); 70 71 ap_int<W_N+A0_N> r0; 72 ap_int<W_N+A1_N> r1; 73 74 (r0, r1) = W*A; 75 76 r0 = r0+r1[W_N+A1_N-1]; 77 78 return (r0,r1); 79 } 80 81 int main(void) 82 { 83 ap_int<17> r0, r1; 84 85 ap_uint<8> a=255; 86 ap_int<9> w0=255, w1=-255; 87 (r0, r1) = MUL_MAC<8,9,9>(a, w0, w1); 88 cout<<"uii"<<endl; 89 cout<<r0.to_int()<<endl; 90 cout<<r1.to_int()<<endl; 91 92 ap_int<8> ax=-128; 93 (r0, r1) = MUL_MAC<8,9,9>(ax, w0, w1); 94 cout<<"iii"<<endl; 95 cout<<r0.to_int()<<endl; 96 cout<<r1.to_int()<<endl; 97 98 ap_uint<8> a0=255, a1=255; 99 ap_int<9> w=-255; 100 (r0, r1) = MUL_MAC<9,8,8>(w, a0, a1); 101 cout<<"iuu"<<endl; 102 cout<<r0.to_int()<<endl; 103 cout<<r1.to_int()<<endl; 104 105 ap_uint<8> x=255; 106 ap_uint<9> y0=511, y1=511; 107 ap_uint<17> z0, z1; 108 (z0, z1) = MUL_MAC<8,9,9>(x, y0, y1); 109 cout<<"uuu"<<endl; 110 cout<<z0.to_int()<<endl; 111 cout<<z1.to_int()<<endl; 112 113 return 0; 114 }
上述HLS代码使用到了C++中的模块函数与函数重载功能。根据实际的INT8乘法计算过程,可以分为有符号乘有符号(iii)、无符号乘无符号(uuu)、有符号乘无符号(iuu)、无符号乘有符号(uii)四种类型。除了uuu不用考虑二进制补码的问题,其他均需要考虑。在此处,笔者考虑到CNN量化感知训练中常用的TFLite格式文件,权重数据通常使用8bit无符号与8bit的固定偏移来表示,即TFLite中权重数据通常使用9bit有符号数来表示(相关链接点我),因此在实际的测试中使用9bit与8bit的乘法运算作为示例。
4、使用说明
在实际的使用过程中:
①一般第一层卷积为8bit有符号或无符号的RGB数据,那么CNN加速中通常使用特征图复用,即iii或uii模式;
②随着第一层CNN网络计算结束,Relu函数的调用使得特征图通常由原来的8bit有符号数转换为7bit无符号数,若使用特征图复用,此时使用uii模式;
③若CNN网络的中间层没有使用Relu函数,或者使用了LeakyRelu、RLU、Tanh等,则特征图表示为8bit有符号数,此时使用iii模式;
③再随着CNN网络的加深,为了减少片上存储的消耗和外部DDR交互带宽的使用,CNN加速转变为权重复用,此时使用iuu模式;
④一直到CNN网络的最后一层,如果使用FC分类器,有可能出现权重数据均为无符号数的情况,那么此时可以使用uuu模式(可选,极少出现)。
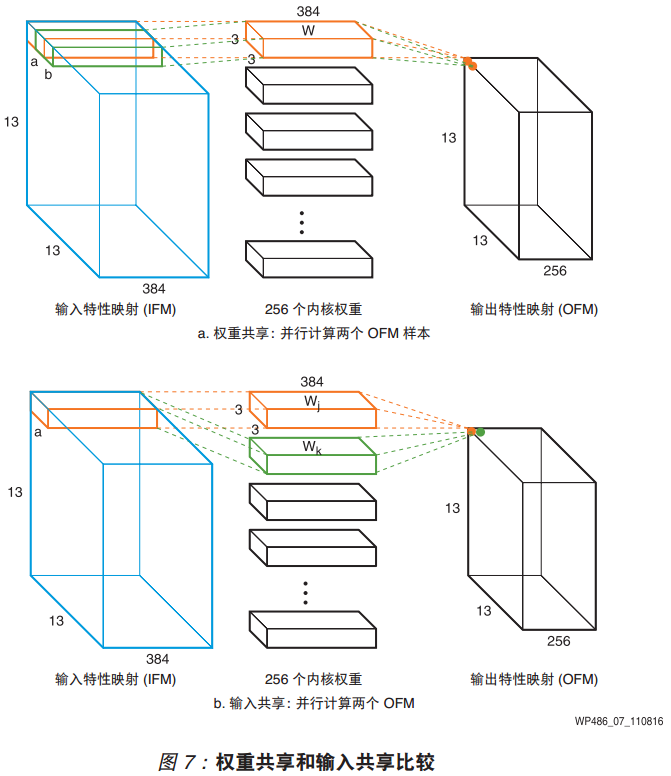
以上的INT8优化方法在使用的时候,必须要保证为两组具有同一系数的乘法操作,即对应wp486的图7。
5、总结
结合Xilinx官方给出的INT8优化方法,可以很轻松的实现INT8数据的算力翻倍。同理结合上述设计思路,同样能够实现其他bit的计算优化,例如若特征图为8bit,权重为3bit,则单个DSP可以实现3组乘法优化;若特征图为4bit,权重为4bit,加上使用特征图输入拼接打包为12bit,则单个DSP可以实现4组乘法优化;当然也支持其他数据位宽组合,只要特征图打包后位宽小于18bit,权重打包后位宽小于27bit,均可实现乘法优化。
参考资料:WP486 - Deep Learning with INT8 Optimization on Xilinx Devices White Paper
